Gerenciar arquivos temporários com o PostgreSQL
No PostgreSQL, uma consulta que executa operações de classificação e hash utiliza a memória da instância para armazenar resultados até o valor especificado no parâmetro work_memFreeLocalStorage. Para ter mais informações, consulte Solucionar problemas de armazenamento local
Você pode usar os parâmetros e as funções a seguir para gerenciar os arquivos temporários em sua instância.
-
temp_file_limit: esse parâmetro cancela qualquer consulta que exceda o tamanho de temp_files em KB. Esse limite impede que qualquer consulta seja executada indefinidamente e consuma espaço em disco com arquivos temporários. Você pode estimar o valor utilizando os resultados do parâmetro log_temp_files. Como prática recomendada, examine o comportamento da workload e defina o limite de acordo com a estimativa. O exemplo a seguir mostra como uma consulta é cancelada quando ela excede o limite.postgres=> select * from pgbench_accounts, pg_class, big_table;ERROR: temporary file size exceeds temp_file_limit (64kB) log_temp_files: esse parâmetro envia mensagens ao postgresql.log quando os arquivos temporários de uma sessão são removidos. Esse parâmetro produz logs após a conclusão bem-sucedida de uma consulta. Portanto, isso pode não ajudar na solução de problemas de consultas ativas e de longa duração. O exemplo a seguir mostra que, quando a consulta é concluída com êxito, as entradas são registradas no arquivo postgresql.log enquanto os arquivos temporários são limpos.
2023-02-06 23:48:35 UTC:205.251.233.182(12456):adminuser@postgres:[31236]:LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp31236.5", size 140353536 2023-02-06 23:48:35 UTC:205.251.233.182(12456):adminuser@postgres:[31236]:STATEMENT: select a.aid from pgbench_accounts a, pgbench_accounts b where a.bid=b.bid order by a.bid limit 10; 2023-02-06 23:48:35 UTC:205.251.233.182(12456):adminuser@postgres:[31236]:LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp31236.4", size 180428800 2023-02-06 23:48:35 UTC:205.251.233.182(12456):adminuser@postgres:[31236]:STATEMENT: select a.aid from pgbench_accounts a, pgbench_accounts b where a.bid=b.bid order by a.bid limit 10;pg_ls_tmpdir: essa função que está disponível no RDS para PostgreSQL 13 e versões posteriores oferece visibilidade sobre o uso atual de arquivos temporários. A consulta concluída não aparece nos resultados da função. No exemplo a seguir, você pode visualizar os resultados dessa função. postgres=> select * from pg_ls_tmpdir();name | size | modification -----------------+------------+------------------------ pgsql_tmp8355.1 | 1072250880 | 2023-02-06 22:54:56+00 pgsql_tmp8351.0 | 1072250880 | 2023-02-06 22:54:43+00 pgsql_tmp8327.0 | 1072250880 | 2023-02-06 22:54:56+00 pgsql_tmp8351.1 | 703168512 | 2023-02-06 22:54:56+00 pgsql_tmp8355.0 | 1072250880 | 2023-02-06 22:54:00+00 pgsql_tmp8328.1 | 835031040 | 2023-02-06 22:54:56+00 pgsql_tmp8328.0 | 1072250880 | 2023-02-06 22:54:40+00 (7 rows)postgres=> select query from pg_stat_activity where pid = 8355;query ---------------------------------------------------------------------------------------- select a.aid from pgbench_accounts a, pgbench_accounts b where a.bid=b.bid order by a.bid (1 row)O nome do arquivo inclui o ID de processamento (PID) da sessão que gerou o arquivo temporário. Uma consulta mais avançada, como no exemplo a seguir, executa uma soma dos arquivos temporários para cada PID.
postgres=> select replace(left(name, strpos(name, '.')-1),'pgsql_tmp','') as pid, count(*), sum(size) from pg_ls_tmpdir() group by pid;pid | count | sum ------+------------------- 8355 | 2 | 2144501760 8351 | 2 | 2090770432 8327 | 1 | 1072250880 8328 | 2 | 2144501760 (4 rows)-
pg_stat_statements: se você ativar o parâmetro pg_stat_statements, poderá visualizar o uso médio de arquivos temporários por chamada. Você pode identificar o query_id da consulta e usá-lo para examinar o uso do arquivo temporário, conforme mostrado no exemplo a seguir.postgres=> select queryid from pg_stat_statements where query like 'select a.aid from pgbench%';queryid ---------------------- -7170349228837045701 (1 row)postgres=> select queryid, substr(query,1,25), calls, temp_blks_read/calls temp_blks_read_per_call, temp_blks_written/calls temp_blks_written_per_call from pg_stat_statements where queryid = -7170349228837045701;queryid | substr | calls | temp_blks_read_per_call | temp_blks_written_per_call ----------------------+---------------------------+-------+-------------------------+---------------------------- -7170349228837045701 | select a.aid from pgbench | 50 | 239226 | 388678 (1 row) -
Performance Insights: no painel do Performance Insights, você pode visualizar o uso temporário de arquivos ativando as métricas temp_bytes e temp_files. Depois, você pode ver a média dessas duas métricas e como elas correspondem à workload da consulta. A exibição no Performance Insights não mostra especificamente as consultas que estão gerando os arquivos temporários. No entanto, ao combinar o Performance Insights com a consulta mostrada parapg_ls_tmpdir, você pode solucionar problemas, analisar e determinar as alterações em sua workload de consulta.Para ter mais informações sobre como analisar as métricas e as consultas com o Performance Insights, consulte Análise de métricas usando o painel do Performance Insights
Como visualizar o uso de arquivos temporários com o Performance Insights
-
No painel do Performance Insights, selecione Gerenciar métricas.
-
Escolha Métricas de banco de dados e selecione as métricas temp_bytes e temp_files como mostrado na imagem a seguir.
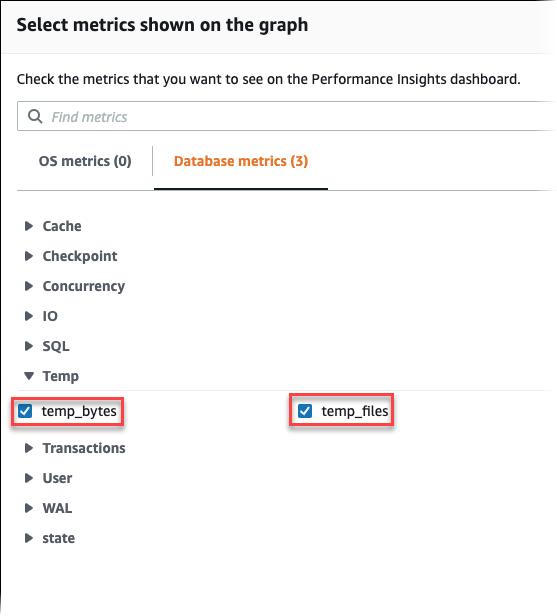
-
Na guia Top SQL, selecione o ícone Preferências.
-
Na janela Preferências, ative as estatísticas a seguir para serem exibidas na guia Top SQL e selecione Continuar.
-
Gravações temporárias/segundo
-
Leituras de temperatura/segundo
-
Gravação/chamada em bloco temporário
-
Leitura/chamada em bloco temporário
-
-
O arquivo temporário é dividido quando combinado com a consulta mostrada para
pg_ls_tmpdir, conforme exibido no exemplo a seguir.
-
Os eventos IO:BufFileRead e IO:BufFileWrite ocorrem porque as principais consultas na workload geralmente criam arquivos temporários. Você pode usar o Insights de Performance para identificar as principais consultas que aguardam IO:BufFileRead e IO:BufFileWrite revisando “Média de sessões ativas (AAS)” nas seções “Carga do banco de dados” e “SQL principal”.
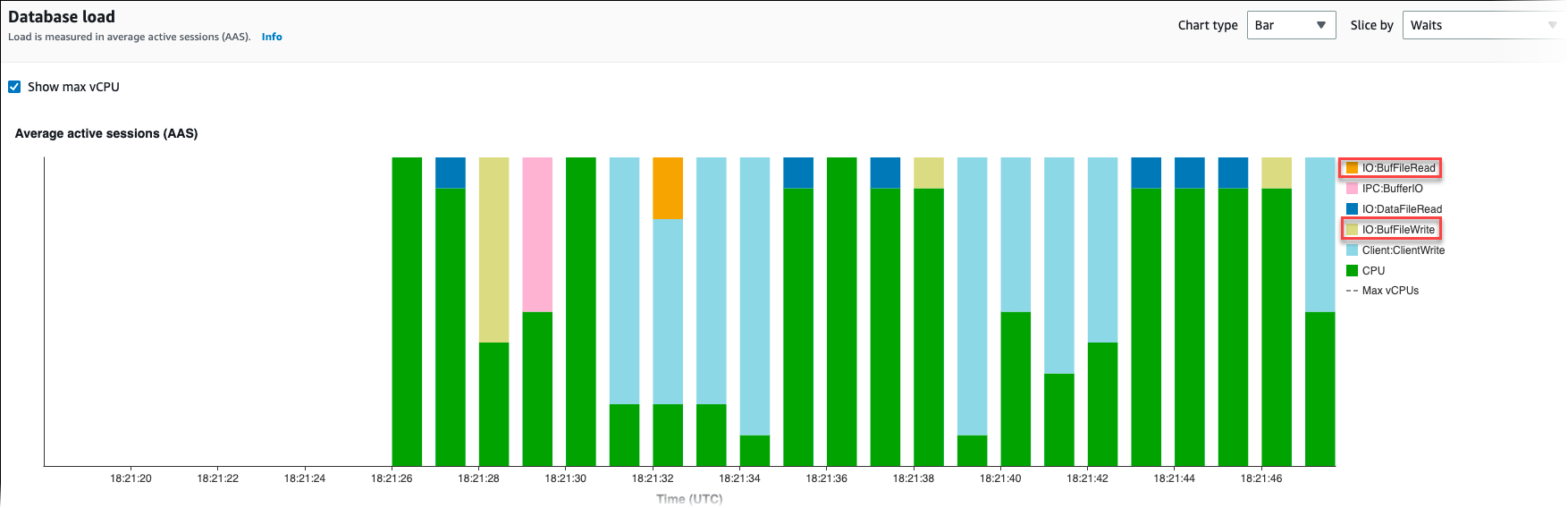
Para obter mais informações sobre como usar o Insights de Performance para analisar as principais consultas e a carga por eventos de espera, consulte Visão geral da guia Top SQL (SQL principal) Você deve identificar e ajustar as consultas que aumentam o uso de arquivos temporários e os eventos de espera correspondentes. Para obter mais informações sobre esses eventos de espera e a correção, consulte .
nota
O parâmetro work_mem
Como prática recomendada, quando você tem um relatório grande com várias junções e classificações, defina esse parâmetro no nível da sessão usando o comando SET work_mem. Depois, a alteração é aplicada somente à sessão atual e não altera o valor globalmente.
