Adição de um grupo de fragmentos de banco de dados a um cluster de banco de dados do Aurora PostgreSQL Limitless Database existente
Você pode criar um grupo de fragmentos de banco de dados em um cluster de banco de dados existente, por exemplo, se estiver restaurando um cluster de banco de dados ou se tiver excluído o grupo de fragmentos de banco de dados.
Para obter mais informações sobre os requisitos do cluster de banco de dados primário e do grupo de fragmentos de banco de dados, consulte Requisitos e considerações do Aurora PostgreSQL Limitless Database.
nota
É possível ter somente um grupo de fragmentos de banco de dados por cluster.
O cluster de banco de dados do Limitless Database deve estar no estado available antes que você possa criar um grupo de fragmentos de banco de dados.
Você pode usar o AWS Management Console para adicionar um grupo de fragmentos de banco de dados a um cluster de banco de dados existente.
Como adicionar um grupo de fragmentos de banco de dados
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
Navegue até a página Databases (Bancos de dados).
-
Selecione o cluster de banco de dados do Limitless Database ao qual você deseja adicionar um grupo de fragmentos de banco de dados.
-
Em Ações, escolha Adicionar um grupo de fragmentos de banco de dados.
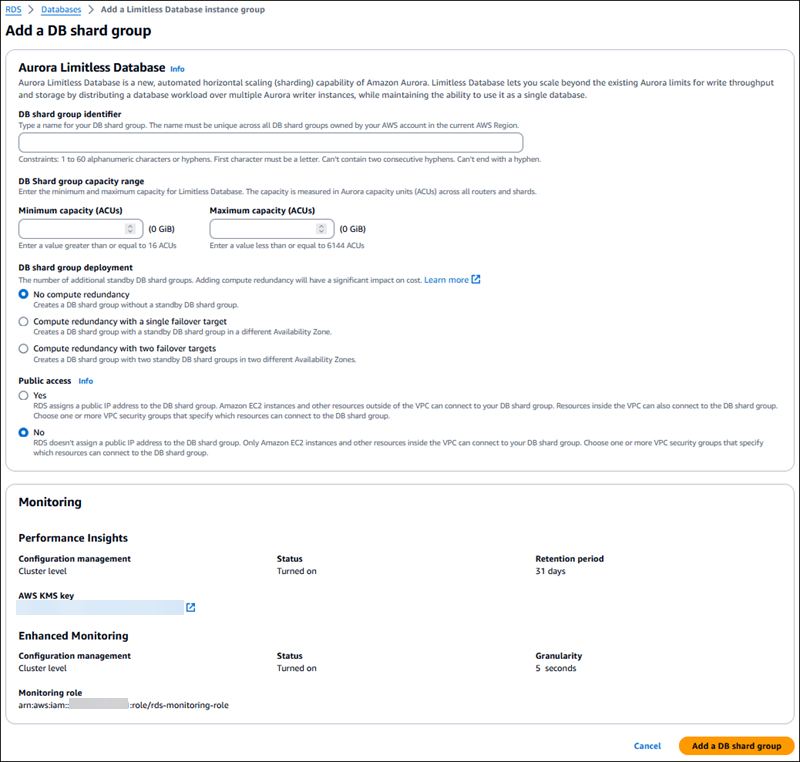
-
Insira um Identificador do grupo de fragmentos de banco de dados.
Importante
Depois de criar o grupo de fragmentos de banco de dados, não é possível alterar o identificador do cluster de banco de dados ou o identificador do grupo de fragmentos de banco de dados.
-
Insira a Capacidade mínima (ACUs). Use um valor de pelo menos 16 ACUs.
-
Insira a Capacidade máxima (ACUs). Use um valor de 16 a 6144 ACUs.
Para ter mais informações, consulte Correlação da capacidade máxima do grupo de fragmentos de banco de dados com o número de roteadores e fragmentos criados.
-
Em Implantação de grupos de fragmentos de banco de dados, escolha se deseja criar standbys para o grupo de fragmentos de banco de dados:
-
Sem redundância computacional: cria um grupo de fragmentos de banco de dados sem standbys para cada fragmento. Este é o valor padrão.
-
Redundância computacional com um único destino de failover: cria um grupo de fragmentos de banco de dados com um standby computacional em uma zona de disponibilidade (AZ) diferente.
-
Redundância computacional com dois destinos de failover: cria um grupo de fragmentos de banco de dados com dois standbys computacionais em duas AZs diferentes.
-
-
Escolha se deseja tornar o grupo de fragmentos de banco de dados acessível publicamente.
nota
Não é possível modificar essa configuração após criar o grupo de fragmentos de banco de dados.
-
Escolha Adicionar um grupo de fragmentos de banco de dados.
Use o comando create-db-shard-group da AWS CLI para criar um grupo de fragmentos de banco de dados.
Os seguintes parâmetros são obrigatórios:
-
--db-cluster-identifier: o cluster de banco de dados ao qual o grupo de fragmentos de banco de dados pertence. -
--db-shard-group-identifier: o nome do grupo de fragmentos de banco de dados.O identificador do grupo de fragmentos de banco de dados tem as seguintes restrições:
-
Ele deve ser exclusivo na Conta da AWS e Região da AWS em que você o criou.
-
Deve conter de 1 a 63 letras, números ou hifens.
-
O primeiro caractere deve ser uma letra.
-
Não pode terminar com um hífen ou conter dois hífens consecutivos.
Importante
Depois de criar o grupo de fragmentos de banco de dados, não é possível alterar o identificador do cluster de banco de dados ou o identificador do grupo de fragmentos de banco de dados.
-
-
--max-acu: a capacidade máxima do grupo de fragmentos de banco de dados. Use um valor de 16 a 6144 ACUs.
Os seguintes parâmetros são opcionais:
-
--compute-redundancy: se deve criar standbys para o grupo de fragmentos de banco de dados. Esse parâmetro pode ter um dos seguintes valores:-
0: cria um grupo de fragmentos de banco de dados sem standbys para cada fragmento. Este é o valor padrão. -
1: cria um grupo de fragmentos de banco de dados com um standby computacional em uma zona de disponibilidade (AZ) diferente. -
2: cria um grupo de fragmentos de banco de dados com dois standbys computacionais em duas AZs diferentes.
nota
Se você definir a redundância computacional para um valor diferente de zero, o número total de nós será dobrado ou triplicado. Isso incorrerá em custos adicionais.
-
-
--min-acu: a capacidade mínima do grupo de fragmentos de banco de dados. Deve ser de pelo menos 16 ACUs, que é o valor padrão. -
--publicly-accessible|--no-publicly-accessible: se devem ser atribuídos endereços IP acessíveis publicamente ao grupo de fragmentos de banco de dados. O acesso ao grupo de fragmentos de banco de dados é controlado pelos grupos de segurança usados pelo cluster.O padrão é
--no-publicly-accessible.nota
Não é possível modificar essa configuração após criar o grupo de fragmentos de banco de dados.
O exemplo a seguir cria um grupo de fragmentos de banco de dados no cluster de banco de dados do Aurora PostgreSQL.
aws rds create-db-shard-group \ --db-cluster-identifiermy-db-cluster\ --db-shard-group-identifiermy-new-shard-group\ --max-acu1000
A saída será semelhante ao seguinte exemplo.
{ "Status": "CREATING", "Endpoint": "my-db-cluster.limitless-ckifpdyyyxxx.us-east-1.rds.amazonaws.com", "PubliclyAccessible": false, "DBClusterIdentifier": "my-db-cluster", "MaxACU": 1000.0, "DBShardGroupIdentifier": "my-new-shard-group", "DBShardGroupResourceId": "shardgroup-8986d309a93c4da1b1455add17abcdef", "ComputeRedundancy": 0 }
