Restaurar um backup em uma instância de banco de dados do Amazon RDS para MySQL
O Amazon RDS permite a importação de bancos de dados MySQL com arquivos de backup. Você pode criar um backup do banco de dados, armazenar o arquivo de backup no Amazon S3 e, depois, restaurar o arquivo de backup em uma nova instância de banco de dados do Amazon RDS que executa o MySQL. O Amazon RDS permite a importação de arquivos de backup do Amazon S3 em todas as Regiões da AWS.
O cenário descrito nesta seção restaura um backup de um banco de dados on-premises. Desde que o banco de dados esteja acessível, você pode usar essa técnica para bancos de dados em outros locais, como o Amazon EC2 ou outros serviços de nuvem.
O diagrama a seguir mostra o cenário com suporte.
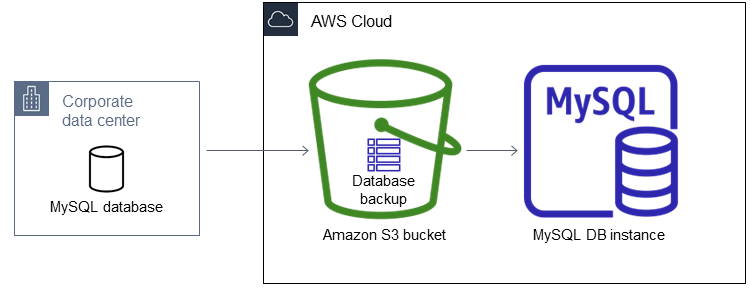
Se seu banco de dados on-premises puder ficar off-line enquanto você cria, copia e restaura os arquivos de backup, recomendamos usar os arquivos de backup para importar o banco de dados para o Amazon RDS. Se o banco de dados não puder ficar off-line, use um dos seguintes métodos:
-
Logs binários: primeiro, importe arquivos de backup do Amazon S3 para o Amazon RDS, conforme explicado neste tópico. Em seguida, use a replicação de log binário (binlog) para atualizar o banco de dados. Para obter mais informações, consulte Configurar a replicação da posição do arquivo de log binário com uma instância de origem externa.
-
AWS Database Migration Service: use o AWS Database Migration Service para migrar o banco de dados para o Amazon RDS. Para ter mais informações, consulte O que é o AWS Database Migration Service?
Visão geral da configuração para importar arquivos de backup do Amazon S3 para o Amazon RDS
Para configurar importar arquivos de backup do Amazon S3 para o Amazon RDS, você precisa dos seguintes componentes:
Um bucket do Amazon S3 para armazenar seus arquivos de backup.
Se você já tiver um bucket do Amazon S3, poderá usá-lo. Se você não tiver um bucket do Amazon S3, crie um. Para mais informações, consulte Criar um bucket.
Um backup de seu banco de dados no local criado pelo Percona XtraBackup.
Para obter mais informações, consulte Criar o backup de banco de dados.
-
Um perfil do AWS Identity and Access Management (IAM) para permitir que o Amazon RDS acesse o bucket do S3.
Se você já tiver um perfil do IAM, poderá usá-lo e anexar políticas de confiança e permissões a ele. Para obter mais informações, consulte Criação manual de uma função do IAM.
Se você não tiver um perfil do IAM, há duas opções:
-
É possível criar um perfil do IAM manualmente. Para obter mais informações, consulte Criação manual de uma função do IAM.
-
Você pode optar por deixar o Amazon RDS criar um perfil do IAM para você. Se quiser que o Amazon RDS crie um perfil do IAM para você, siga o procedimento que usa o Console de gerenciamento da AWS na seção Importar dados do Amazon S3 para uma nova instância de banco de dados MySQL.
-
Criar o backup de banco de dados
Use o software Percona XtraBackup para criar seu backup. É recomendável utilizar a versão mais recente do Percona XtraBackup. Você pode instalar o Percona XtraBackup em Software Downloads
Atenção
Ao criar um backup de banco de dados, o XtraBackup pode salvar credenciais no arquivo xtrabackup_info. Confirme se a configuração tool_command no arquivo xtrabackup_info não contém informações confidenciais.
A versão do Percona XtraBackup a ser usada depende da versão do MySQL da qual você está fazendo backup.
-
MySQL 8.4: use o Percona XtraBackup versão 8.4.
-
MySQL 8.0: use o Percona XtraBackup versão 8.0.
nota
O Percona XtraBackup 8.0.12 e versões posteriores oferecem suporte à migração de todas as versões do MySQL 8.0. Se você estiver migrando para o RDS para MySQL 8.0.32 ou posterior, use o Percona XtraBackup 8.0.12 ou posterior.
-
MySQL 5.7: use o Percona XtraBackup versão 2.4.
Você pode usar o Percona XtraBackup para criar um backup completo de seus arquivos de banco de dados MySQL. Ou, se você já usa o Percona XtraBackup para fazer o backup dos arquivos do banco de dados MySQL, pode fazer upload dos arquivos e diretórios de backup completos e incrementais.
Para ter mais informações sobre como fazer backup do banco de dados com o Percona XtraBackup, consulte Percona XtraBackup - Documentation
Criar um backup completo com o Percona XtraBackup
Para criar um backup completo dos arquivos do banco de dados MySQL que o Amazon RDS pode restaurar do Amazon S3, use o utilitário Percona XtraBackup (xtrabackup).
Por exemplo, o seguinte comando cria um backup de um banco de dados MySQL e armazena os arquivos na pasta /on-premises/s3-restore/backup.
xtrabackup --backup --user=myuser--password=password--target-dir=/on-premises/s3-restore/backup
Se você deseja compactar o backup em um único arquivo, que pode ser dividido posteriormente, se necessário, salve o backup em um dos seguintes formatos com base em sua versão do MySQL:
Gzip (.gz): para MySQL 5.7 e versões anteriores.
tar (.tar): para MySQL 5.7 e versões anteriores.
Percona xbstream (.xbstream): para todas as versões do MySQL.
nota
O Percona XtraBackup 8.0 e posterior permite que apenas o Percona xbstream seja usado para compactação.
MySQL 5.7 e versões anteriores
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos Gzip. Substitua os valores por suas próprias informações.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| gzip - | split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar.gz
MySQL 5.7 e versões anteriores
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos tar. Substitua os valores por suas próprias informações.
xtrabackup --backup --user=my_user--password=password--stream=tar \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.tar
Todas as versões do MySQL
O comando a seguir cria um backup do seu banco de dados MySQL dividido em vários arquivos xbstream. Substitua os valores por suas próprias informações.
xtrabackup --backup --user=myuser--password=password--stream=xbstream \ --target-dir=/on-premises/s3-restore/backup| split -d --bytes=500MB \ -/on-premises/s3-restore/backup/backup.xbstream
nota
Se você vir o erro a seguir, é provável que você tenha misturado os formatos de arquivo em seu comando:
ERROR:/bin/tar: This does not look like a tar archive
Usar backups incrementais com o Percona XtraBackup
Se você já usa o Percona XtraBackup para fazer backups completos e incrementais de seus arquivos de banco de dados MySQL, não precisa criar um backup completo e fazer upload dos arquivos de backup no Amazon S3. Em vez disso, para economizar tempo, copie os diretórios e arquivos de backup existentes no bucket do Amazon S3. Para ter mais informações sobre como criar backups incrementais usando o Percona XtraBackup, consulte Create an incremental backup
Quando copiar os arquivos existentes de backup completo e incremental para um bucket do Amazon S3, copie recursivamente o conteúdo do diretório de base. Esse conteúdo inclui o backup completo e todos os diretórios e arquivos de backup incremental. Essa cópia deve preservar a estrutura de diretórios no bucket do Amazon S3. O Amazon RDS percorre todos os arquivos e diretórios. O Amazon RDS usa o arquivo xtrabackup-checkpoints incluído em cada backup incremental para identificar o diretório de base e ordenar os backups incrementais por intervalo de número de sequência de log (LSN).
Considerações sobre backup para o Percona XtraBackup
O Amazon RDS consome seus arquivos de backup com base no nome do arquivo. Nomeie os arquivos de backup com a extensão de arquivo apropriada com base no formato do arquivo. Por exemplo, use .xbstream para arquivos armazenados que usam o formato Percona xbstream.
O Amazon RDS consome os arquivos de backup em ordem alfabética assim como na ordem numérica natural. Para garantir que os arquivos de backup sejam gravados e nomeados na ordem apropriada, use a opção split ao emitir o comando xtrabackup.
O Amazon RDS não oferece suporte a backups parciais criados com o Percona XtraBackup. Não é possível usar as seguintes opções para criar um backup parcial ao fazer backup dos arquivos de origem de seu banco de dados:
-
--tables -
--tables-exclude -
--tables-file -
--databases -
--databases-exclude -
--databases-file
Criação manual de uma função do IAM
Se você não tiver um perfil do IAM, crie um novo manualmente. No entanto, se você restaurar o banco de dados usando o Console de gerenciamento da AWS, recomendamos que deixe que Amazon o RDS crie esse perfil do IAM para você. Para que o Amazon RDS crie esse perfil para você, siga o procedimento na seção Importar dados do Amazon S3 para uma nova instância de banco de dados MySQL.
Para criar manualmente um perfil do IAM para importar seu banco de dados do Amazon S3, crie um perfil para delegar permissões do Amazon RDS ao bucket do Amazon S3. Quando você cria um perfil do IAM, você anexa as políticas de confiança e permissões. Para importar os arquivos de backup do Amazon S3, use políticas de confiança e de permissões semelhantes aos exemplos a seguir. Para ter mais informações sobre como criar a função, consulte Criar uma função para delegar permissões a um AWSserviço da .
As políticas de confiança e permissões exigem que você forneça um Nome do recurso da Amazon (ARN). Para ter mais informações sobre como formatar o ARN, consulte Nomes de recurso da Amazon (ARNs) e AWS namespaces de serviço da .
exemplo política de confiança para importar do Amazon S3
exemplo política de permissões para importar do Amazon S3: permissões de usuário do IAM
No exemplo a seguir, substitua iam_user_id por seu próprio valor.
exemplo Política de permissões para importar do Amazon S3: permissões de perfil
No exemplo a seguir, substitua amzn-s3-demo-bucket e prefix por seus próprios valores.
nota
Se você incluir um prefixo de nome de arquivo, inclua o asterisco (*) após o prefixo. Se não quiser especificar um prefixo, especifique apenas um asterisco.
Importar dados do Amazon S3 para uma nova instância de banco de dados MySQL
Você pode importar dados do Amazon S3 para uma nova instância de banco de dados do MySQL usando o Console de gerenciamento da AWS, a AWS CLI ou a API do RDS.
Para importar dados do Amazon S3 para uma nova instância de banco de dados MySQL
-
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No canto superior direito do console do Amazon RDS, escolha a Região da AWS na qual você quer criar a instância de banco de dados. Escolha a mesma Região da AWS do bucket do Amazon S3 que contém o backup do banco de dados.
-
No painel de navegação, escolha Databases (Bancos de dados).
-
Escolha Restore from S3 (Restaurar do S3).
A página Create database by restoring from S3 (Criar banco de dados restaurando a partir do S3) é exibida.
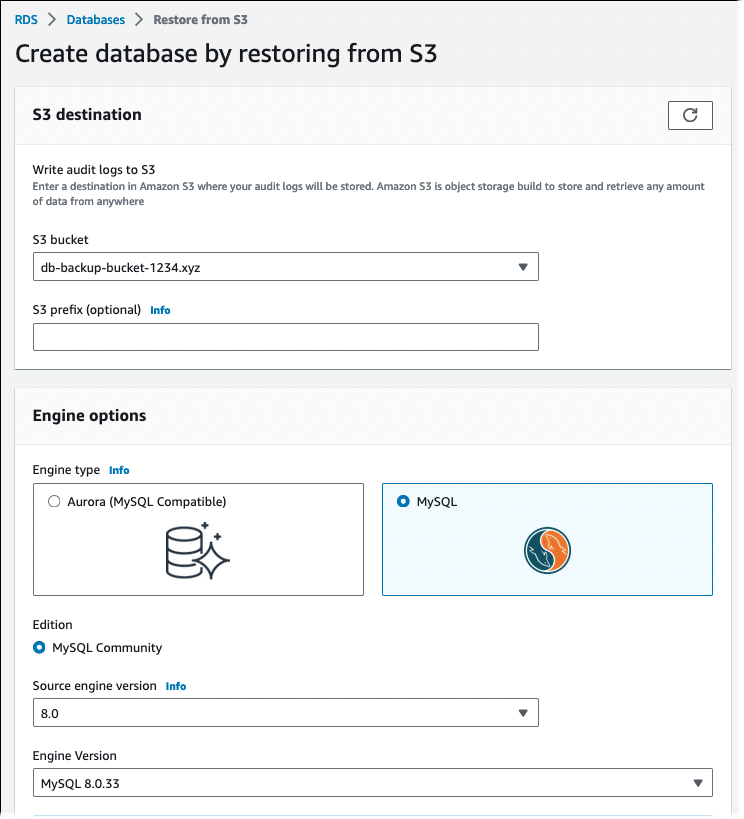
-
Em Origem do S3:
-
Selecione o S3 bucket (bucket do S3) que contém o backup.
-
(Opcional) Em Prefixo do S3, insira o prefixo do caminho dos arquivos armazenados no bucket do Amazon S3.
Se você não especificar um prefixo, o Amazon RDS criará a instância de banco de dados usando todos os arquivos e pastas na pasta raiz do bucket do S3. Se você especificar um prefixo, o Amazon RDS criará a instância de banco de dados usando os arquivos e as pastas no bucket do S3 no qual o caminho para o arquivo começa com o prefixo especificado.
Por exemplo, você armazena seus arquivos de backup no S3 em uma subpasta denominada backups e tem vários conjuntos de arquivos de backup, cada um em seu próprio diretório (gzip_backup1, gzip_backup2 e assim por diante). Nesse caso, para restaurar dos arquivos na pasta gzip_backup1 para especifique o prefixo backups/gzip_backup1.
-
-
Em Engine options (Opções de mecanismo):
-
Em Engine type (Tipo de mecanismo), escolha MySQL.
-
Para Source engine version (Versão do mecanismo de origem), escolha a versão principal do MySQL de seu banco de dados de origem.
-
Em Versão do mecanismo, escolha a versão secundária padrão da versão principal do MySQL na Região da AWS.
No Console de gerenciamento da AWS, apenas a versão secundária padrão está disponível. Depois de concluir a importação, você pode atualizar a instância de banco de dados.
-
-
Em Perfil do IAM, crie ou escolha o perfil do IAM com a política de confiança e a política de permissões necessárias para que o Amazon RDS acesse o bucket do Amazon S3. Execute uma das seguintes ações:
(Recomendado) Escolha Criar um perfil e insira o Nome do perfil do IAM. Com essa opção, o Amazon RDS cria automaticamente o perfil com a política de confiança e a política de permissões para você.
Escolha um perfil do IAM existente. Verifique se esse perfil atende a todos os critérios em Criação manual de uma função do IAM.
-
Especifique as informações da instância de banco de dados. Para obter informações sobre cada configuração, consulte Configurações para instâncias de banco de dados.
nota
Aloque armazenamento suficiente para sua nova instância de banco de dados para que a operação de restauração possa continuar.
Para permitir o crescimento futuro automaticamente, em Configuração adicional de armazenamento, escolha Habilitar escalabilidade automática do armazenamento.
-
Escolha configurações adicionais conforme necessário.
-
Escolha Criar banco de dados.
Para importar dados do Amazon S3 para uma nova instância de banco de dados MySQL usando a AWS CLI, execute o comando restore-db-instance-from-s3 com as opções a seguir. Para obter informações sobre cada configuração, consulte Configurações para instâncias de banco de dados.
nota
Aloque armazenamento suficiente para sua nova instância de banco de dados para que a operação de restauração possa continuar.
Para habilitar o ajuste de escala automático do armazenamento e permitir o crescimento futuro automaticamente, use a opção --max-allocated-storage.
--allocated-storage--db-instance-identifier--db-instance-class--engine--master-username--manage-master-user-password--s3-bucket-name--s3-ingestion-role-arn--s3-prefix--source-engine--source-engine-version
exemplo
Para Linux, macOS ou Unix:
aws rds restore-db-instance-from-s3 \ --allocated-storage250\ --db-instance-identifiermy_identifier\ --db-instance-classdb.m5.large\ --enginemysql\ --master-usernameadmin\ --manage-master-user-password \ --s3-bucket-nameamzn-s3-demo-bucket\ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename\ --s3-prefixbucket_prefix\ --source-enginemysql\ --source-engine-version8.0.32\ --max-allocated-storage1000
Para Windows:
aws rds restore-db-instance-from-s3 ^ --allocated-storage250^ --db-instance-identifiermy_identifier^ --db-instance-classdb.m5.large^ --enginemysql^ --master-usernameadmin^ --manage-master-user-password ^ --s3-bucket-nameamzn-s3-demo-bucket^ --s3-ingestion-role-arnarn:aws:iam::account-number:role/rolename^ --s3-prefixbucket_prefix^ --source-enginemysql^ --source-engine-version8.0.32^ --max-allocated-storage1000
Para importar dados do Amazon S3 para uma nova instância de banco de dados MySQL usando a API do Amazon RDS, chame a operação RestoreDBInstanceFromS3.
Limitações e considerações para importar arquivos de backup do Amazon S3 para o Amazon RDS
As seguintes limitações e considerações se aplicam à importação de arquivos de backup do Amazon S3 para uma instância de banco de dados do RDS para MySQL:
-
Só é possível migrar os dados para uma nova instância de banco de dados, não para uma instância existente.
-
Você deve usar o Percona XtraBackup para fazer backup dos dados no Amazon S3. Para obter mais informações, consulte Criar o backup de banco de dados.
-
O bucket do Amazon S3 e a instância de banco de dados do RDS para MySQL devem estar na mesma Região da AWS.
-
Não é possível restaurar nas seguintes origens:
-
Uma exportação de um snapshot de instância de banco de dados para o Amazon S3. Também não é possível migrar dados de uma exportação de snapshot de instância de banco de dados para o bucket do Amazon S3.
-
Um banco de dados de origem criptografado. Entretanto, você pode criptografar os dados que estão sendo migrados. Também é possível deixar os dados não criptografados durante o processo de migração.
-
Um banco de dados MySQL 5.5 ou 5.6.
-
-
O RDS para MySQL não aceita o Percona Server para MySQL como banco de dados de origem porque ele pode conter tabelas
compression_dictionary*no esquemamysql schema. -
O RDS para MySQL não permite a reversão de migrações para versões principais ou secundárias. Por exemplo, não é possível migrar do MySQL versão 8.0 para o RDS para MySQL 5.7 nem do MySQL versão 8.0.32 para o RDS para MySQL versão 8.0.26.
-
O Amazon RDS não permite fazer importações na classe de instância de banco de dados db.t2.micro por meio do Amazon S3. Contudo, você poderá restaurar para outra classe de instância de banco de dados e, posteriormente, alterar a instância de banco de dados. Para mais informações sobre as classes da instância, consulte Especificações de hardware para classes de instância de banco de dados.
-
O Amazon S3 limita o tamanho de um arquivo carregado para um bucket do Amazon S3 a 5 TB. Se um arquivo de backup exceder 5 TB, você deverá dividi o arquivo de backup em arquivos menores.
-
O Amazon RDS limita a 1 milhão o número de arquivos carregados para um bucket do Amazon S3. Se os dados de backup do banco de dados, incluindo todos os backups completos e incrementais, exceder 1 milhão de arquivos, use um arquivo Gzip (.gz), tar (.tar.gz) ou Percona xbstream (.xbstream) para armazenar arquivos de backup completos e incrementais no bucket do Amazon S3. O Percona XtraBackup 8.0 oferece suporte apenas ao Percona xbstream para compactação.
-
Para fornecer serviços de gerenciamento para cada instância de banco de dados, o Amazon RDS cria o usuário
rdsadminao criar a instância de banco de dados. Comordsaminé um usuário reservado no Amazon RDS, as seguintes limitações se aplicam:-
O Amazon RDS não importa funções, procedimentos, visualizações, eventos e acionadores com o definidor
'rdsadmin'@'localhost'. Para obter mais informações, consulte Objetos armazenados com “rdsadmin'@'localhost” como definidor e Privilégios da conta de usuário mestre. -
Ao criar a instância de banco de dados, o Amazon RDS cria um usuário principal com os privilégios máximos permitidos. Na restauração por meio de backup, o Amazon RDS remove automaticamente qualquer privilégio não permitido atribuído aos usuários que estão sendo importados.
Para identificar usuários que possam ser afetados por isso, consulte Contas de usuário com privilégios não compatíveis. Para ter mais informações sobre privilégios permitidos no RDS para MySQL, consulte Modelo de privilégios baseados em perfis para o RDS para MySQL.
-
-
O Amazon RDS não migra tabelas criadas pelo usuário no esquema
mysql. -
Você deve configurar o parâmetro
innodb_data_file_pathcom apenas um arquivo de dados que usa o nome de arquivo de dados padrãoibdata1:12M:autoextend. Você pode migrar bancos de dados com dois arquivos de dados ou com um arquivo de dados com um nome diferente usando esse método.Os seguintes exemplos são nomes de arquivo que o Amazon RDS não permite:
-
innodb_data_file_path=ibdata1:50M -
ibdata2:50M:autoextend -
innodb_data_file_path=ibdata01:50M:autoextend
-
-
Não é possível migrar de um banco de dados de origem que tenha tabelas definidas fora do diretório de dados MySQL padrão.
-
O tamanho máximo aceito para backups não compactados usando esse método é 64 TiB. Para backups compactados, esse limite é menor para levar em conta os requisitos de espaço sem compactação. Nesses casos, o tamanho máximo de backup aceito é
64 TiB - compressed backup size.Para ter informações sobre o tamanho máximo do banco de dados que o Amazon RDS para MySQL permite, consulte Armazenamento SSD de uso geral e Armazenamento SSD de IOPS provisionadas.
-
O Amazon RDS não permite importações do MySQL e de outros componentes e plug-ins externos.
-
Ele não restaura tudo do seu banco de dados. Recomendamos salvar o esquema do banco de dados e os valores dos itens do banco de dados MySQL de origem relacionados abaixo e adicioná-los à instância de banco de dados restaurada do RDS para MySQL depois que ela for criada:
-
Contas de usuário
-
Funções
-
Procedimentos armazenados
-
Informações de fuso horário. As informações de fuso horário são carregadas do sistema operacional local da instância de banco de dados do RDS para MySQL. Para obter mais informações, consulte Fuso horário local para instâncias de banco de dados MySQL.
-
Objetos armazenados com “rdsadmin'@'localhost” como definidor
O Amazon RDS não importa funções, procedimentos, visualizações, eventos e acionadores com o 'rdsadmin'@'localhost' como definidor.
Você pode usar o script SQL a seguir, no banco de dados MySQL de origem, a fim de listar os objetos armazenados que têm o definidor incompatível.
-- This SQL query lists routines with `rdsadmin`@`localhost` as the definer. SELECT ROUTINE_SCHEMA, ROUTINE_NAME FROM information_schema.routines WHERE definer = 'rdsadmin@localhost'; -- This SQL query lists triggers with `rdsadmin`@`localhost` as the definer. SELECT TRIGGER_SCHEMA, TRIGGER_NAME, DEFINER FROM information_schema.triggers WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists events with `rdsadmin`@`localhost` as the definer. SELECT EVENT_SCHEMA, EVENT_NAME FROM information_schema.events WHERE DEFINER = 'rdsadmin@localhost'; -- This SQL query lists views with `rdsadmin`@`localhost` as the definer. SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.views WHERE DEFINER = 'rdsadmin@localhost';
Contas de usuário com privilégios não compatíveis
As contas de usuário com privilégios que o RDS para MySQL não permite são importadas sem os privilégios não permitidos. Para ver a lista de privilégios compatíveis, consulte Modelo de privilégios baseados em perfis para o RDS para MySQL.
É possível executar a consulta SQL a seguir em seu banco de dados de origem para listar as contas de usuário com privilégios incompatíveis.
SELECT user, host FROM mysql.user WHERE Shutdown_priv = 'y' OR File_priv = 'y' OR Super_priv = 'y' OR Create_tablespace_priv = 'y';
