Trabalhar com réplicas de leitura de instância de banco de dados
Uma réplica de leitura é uma cópia somente para leitura de uma instância de banco de dados. É possível reduzir a carga na instância de banco de dados primária roteando as consultas das aplicações para a réplica de leitura. Dessa maneira, é possível aumentar a escala horizontalmente para além das limitações de capacidade de uma única instância de banco de dados para workloads de banco de dados com muita leitura.
Para criar uma réplica de leitura com base em uma instância de banco de dados de origem, o Amazon RDS utiliza os recursos de replicação integrada do mecanismo de banco de dados. Para obter informações sobre como usar réplicas de leitura com um mecanismo específico, consulte as seguintes seções:
Depois de criar uma réplica de leitura com base em uma instância de banco de dados de origem, a origem se torna a instância de banco de dados primária. Quando você faz atualizações na instância de banco de dados primária, o Amazon RDS as copia de forma assíncrona para a réplica de leitura. O diagrama a seguir mostra uma instância de banco de dados de origem replicando para uma réplica de leitura em uma zona de disponibilidade (AZ) diferente. Os clientes têm acesso de leitura/gravação à instância de banco de dados primária e acesso somente de leitura à réplica.
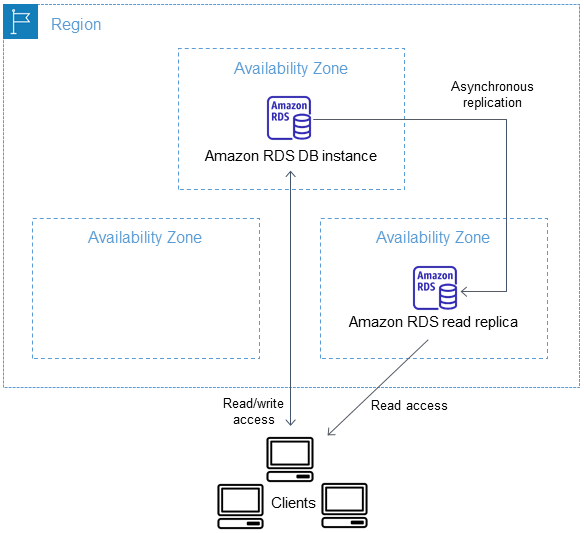
As réplicas de leitura são cobradas como instâncias de banco de dados padrão com as mesmas taxas da classe de instância de banco de dados usada para a réplica. Você não é cobrado pela transferência de dados incorrida na replicação de dados entre a instância de banco de dados de origem e uma réplica de leitura dentro da mesma Região da AWS. Para obter mais informações, consulte Custos da replicação entre regiões e Faturamento da instância de banco de dados para Amazon RDS .
Tópicos
Visão geral das réplicas de leitura do Amazon RDS
As seções a seguir abordam réplicas de leitura de instância de banco de dados. Para ter informações sobre réplicas de leitura de cluster de banco de dados multi-AZ, consulte Trabalhar com réplicas de leitura de cluster de banco de dados multi-AZ para o Amazon RDS.
Tópicos
Casos de uso para réplicas de leitura
Implantar uma ou mais réplicas de leitura a uma determinada instância de banco de dados de origem pode fazer sentido em inúmeros casos, inclusive os seguintes:
-
Expandir além da capacidade computacional ou de E/S de uma única instância de banco de dados para workloads de leitura pesadas de banco de dados. Poder direcionar esse tráfego de leitura excessivo a uma ou mais réplicas de leitura.
-
Atender ao tráfego de leitura enquanto a instância de banco de dados de origem está indisponível. Em alguns casos, sua instância de banco de dados de origem pode não ser capaz de fazer solicitações de E/S, por exemplo, devido à suspensão de E/S para backups ou manutenção programada. Nesses casos, é possível direcionar o tráfego de leitura para suas réplicas de leitura. Para esse tipo de caso de uso, lembre-se de que os dados na réplica de leitura podem estar "obsoletos", porque a instância de banco de dados de origem está indisponível.
-
Casos de relatórios comerciais ou de data warehousing em que você pode desejar que as consultas de relatórios comerciais sejam executadas em relação a uma réplica de leitura, em vez de sua instância de banco de dados de produção.
-
Implementação da recuperação de desastres. É possível promover uma réplica de leitura para uma instância autônoma como solução de recuperação de desastres, caso haja uma falha na instância de banco de dados primária.
Como as réplicas de leitura funcionam
Ao criar uma réplica de leitura, especifique uma instância de banco de dados existente como origem. Em seguida, o Amazon RDS faz um snapshot da instância de origem e cria uma instância apenas para leitura a partir do snapshot. O Amazon RDS usará o método de replicação assíncrona para que o mecanismo de banco de dados atualize a réplica de leitura sempre que houver alteração na instância de banco de dados primária.
A réplica de leitura funciona como uma instância de banco de dados que só permite conexões somente leitura. As exceções são os mecanismos de banco de dados RDS para Db2 e RDS para Oracle, que oferecem suporte a bancos de dados de réplica no modo de espera e no modo montado, respectivamente. Uma réplica de espera e uma réplica montada não aceitam conexões de usuário e, portanto, não podem atender a workloads somente leitura. O principal uso para réplicas montadas de espera e montadas é a recuperação de desastres entre regiões. Para obter mais informações, consulte Trabalhar com réplicas para o Amazon RDS para Db2 e Trabalhar com réplicas de leitura do Amazon RDS para Oracle.
As aplicações se conectam a uma réplica de leitura, assim como fazem com qualquer instância de banco de dados. O Amazon RDS replica todos os bancos de dados na instância de banco de dados de origem.
Você deve criar réplicas de leitura manualmente. O RDS não permite o ajuste de escala automático de réplicas de leitura, que é a adição ou remoção automática de réplicas de leitura conforme a demanda de leitura muda.
Réplicas de leitura em uma implantação multi-AZ
Você pode configurar uma réplica de leitura para uma instância de banco de dados que também tenha uma réplica de espera configurada para alta disponibilidade em uma implantação multi-AZ. A replicação com a réplica em espera é síncrona. Ao contrário de uma réplica de leitura, uma réplica em espera não pode fornecer tráfego de leitura.
No cenário a seguir, os clientes têm acesso de leitura/gravação a uma instância de banco de dados primária em uma AZ. A instância primária copia as atualizações de forma assíncrona em uma réplica de leitura em uma segunda AZ e também as copia de forma síncrona em uma réplica em espera em uma terceira AZ. Os clientes têm acesso de leitura somente à réplica de leitura.
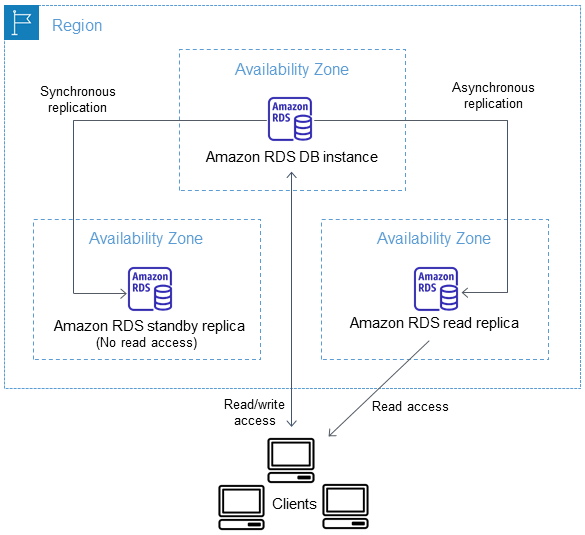
Para ter mais informações sobre réplicas de alta disponibilidade e de espera, consulte Configurar e gerenciar uma implantação multi-AZ para o Amazon RDS.
Réplicas de leitura entre regiões
Em alguns casos, uma réplica de leitura reside em uma Região da AWS diferente daquela da instância de banco de dados primária. Nesses casos, o Amazon RDS configura um canal de comunicação seguro entre a instância de banco de dados primária e a réplica de leitura. O Amazon RDS estabelece quaisquer configurações de segurança da AWS necessárias para permitir o canal seguro, como a inclusão de entradas de grupos de segurança. Para ter mais informações sobre réplicas de leitura entre regiões, consulte Criar uma réplica de leitura em uma diferente Região da AWS.
As informações neste capítulo aplicam-se à criação de réplicas de leitura do Amazon RDS na mesma Região da AWS que a instância de banco de dados de origem ou em uma Região da AWS separada. As informações a seguir não se aplicam à configuração da replicação com uma instância que esteja sendo executada em um instância do Amazon EC2 ou em um ambiente on-premises.
Tipos de armazenamento da réplica de leitura
Por padrão, uma réplica de leitura é criada com o mesmo tipo de armazenamento que a instância de banco de dados de origem. No entanto, é possível pode criar uma réplica de leitura que tenha um tipo diferente de armazenamento que o da instância de banco de dados de origem com base nas opções listadas na tabela a seguir.
| Tipo de armazenamento da instância de banco de dados de origem | Alocação de armazenamento da instância de banco de dados de origem | Opções de tipo de armazenamento da réplica de leitura |
|---|---|---|
| Provisioned IOPS (IOPS provisionadas) | 100 GiB–64 TiB | IOPS provisionadas, propósito geral, magnético |
| Finalidade geral | 100 GiB–64 TiB | IOPS provisionadas, propósito geral, magnético |
| Finalidade geral | <100 GiB | Propósito geral, magnético |
| Magnético | 100 GiB – 6 TiB | IOPS provisionadas, propósito geral, magnético |
| Magnético | <100 GiB | Propósito geral, magnético |
nota
Quando você aumenta o armazenamento alocado de uma réplica de leitura, ela deve ser de pelo menos 10%. Ao tentar aumentar o valor em menos de 10%, você obtém um erro.
Restrições para criar uma réplica com base em uma réplica
O Amazon RDS não suporta a replicação circular. Você não pode configurar uma instância de banco de dados para servir como origem de replicação para uma instância de banco de dados existente. Só é possível criar uma nova réplica de leitura de uma instância de banco de dados existente. Por exemplo, se MySourceDBInstance replicar para ReadReplica1, não será possível configurar ReadReplica1 para replicar de volta para MySourceDBInstance.
No RDS para MariaDB, no RDS para MySQL e em determinadas versões do RDS para PostgreSQL, é possível criar uma réplica de leitura de uma réplica de leitura existente. Por exemplo, é possível criar uma réplica de leitura ReadReplica2 com base em uma réplica existente ReadReplica1. Para o RDS para Db2, RDS para Oracle e RDS para SQL Server, não é possível criar uma réplica de leitura de uma réplica de leitura existente.
Considerações ao excluir réplicas
O RDS não permite o ajuste de escala automático de réplicas de leitura. Por isso, o RDS não aumentará o número de réplicas quando a demanda aumentar nem diminuirá o número de réplicas quando a demanda diminuir. Se você não precisar mais das réplicas de leitura, exclua-as manualmente usando os mesmos mecanismos para excluir uma instância de banco de dados. Se você excluir uma instância de banco de dados de origem sem excluir suas réplicas de leitura na mesma Região da AWS, cada réplica será promovida a uma instância de banco de dados autônoma.
Para obter informações sobre como excluir uma instância de banco de dados, consulte Excluir uma instância de banco de dados. Para obter informações sobre a promoção de réplicas de leitura, consulte Promoção de uma réplica de leitura a uma instância de banco de dados autônoma. Para ter informações sobre como excluir a instância de banco de dados de origem de uma réplica de leitura entre regiões, consulte Considerações sobre replicação entre regiões.
