As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Melhores práticas para otimização de desempenho e eficiência no Amazon MQ para RabbitMQ
Você pode otimizar o desempenho do seu agente Amazon MQ for RabbitMQ maximizando a taxa de transferência, minimizando a latência e garantindo a utilização eficiente dos recursos. Siga as práticas recomendadas a seguir para otimizar o desempenho do seu aplicativo.
Etapa 1: mantenha o tamanho das mensagens abaixo de 1 MB
Recomendamos manter as mensagens com menos de 1 megabyte (MB) para otimizar o desempenho e a confiabilidade.
O RabbitMQ 3.13 suporta tamanhos de mensagem de até 128 MB por padrão, mas mensagens grandes podem acionar alarmes de memória imprevisíveis que bloqueiam a publicação e potencialmente criam alta pressão de memória ao replicar mensagens entre os nós. Mensagens superdimensionadas também podem afetar os processos de reinicialização e recuperação do agente, o que aumenta os riscos à continuidade do serviço e pode causar degradação do desempenho.
Armazene e recupere cargas úteis grandes usando o padrão de verificação de reivindicações
Para gerenciar mensagens grandes, você pode implementar o padrão de verificação de declaração armazenando a carga da mensagem no armazenamento externo e enviando somente o identificador de referência da carga por meio do RabbitMQ. O consumidor usa o identificador de referência da carga útil para recuperar e processar a mensagem grande.
O diagrama a seguir demonstra como usar o Amazon MQ para RabbitMQ e o Amazon S3 para implementar o padrão de verificação de solicitações.
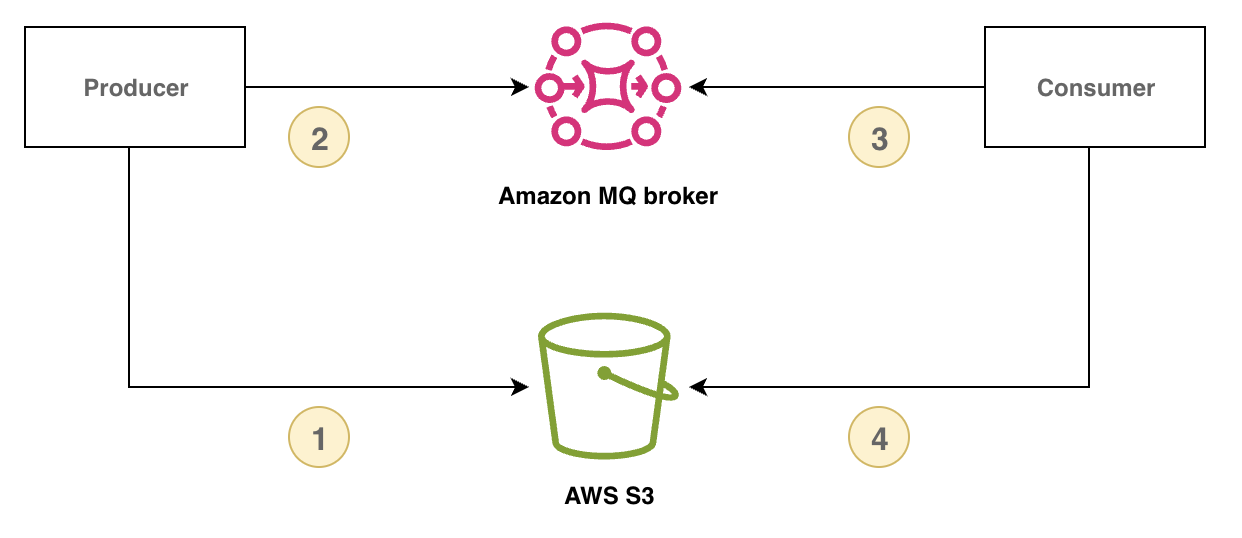
O exemplo a seguir demonstra esse padrão usando o Amazon MQ, AWS o SDK para Java 2.x e o Amazon S3:
-
Primeiro, defina uma classe de mensagem que conterá o identificador de referência do Amazon S3.
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
Crie um método de editor que armazene a carga no Amazon S3 e envie uma mensagem de referência por meio do RabbitMQ.
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
Implemente um método de consumidor que recupere a carga útil do Amazon S3, processe a carga e exclua o objeto do Amazon S3.
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
Etapa 2: uso basic.consume e consumidores duradouros
Usar basic.consume com um consumidor de longa data é mais eficiente do que pesquisar o uso de mensagens individuais. basic.get Para obter mais informações, consulte Pesquisa de mensagens individuais
Etapa 3: configurar a pré-busca
Você pode usar o valor de pré-busca RabbitMQ para otimizar como seus consumidores consomem mensagens. O RabbitMQ implementa o mecanismo de pré-busca do canal fornecido pelo AMQP 0-9-1 aplicando a contagem de pré-busca aos consumidores em oposição aos canais. O valor de pré-busca é usado para especificar quantas mensagens estão sendo enviadas ao consumidor em um determinado momento. Por padrão, o RabbitMQ define um tamanho ilimitado de buffer para aplicações do cliente.
Há muitos fatores a serem considerados ao definir uma contagem de pré-busca para seus consumidores RabbitMQ. Primeiro, considere o ambiente e a configuração dos seus consumidores. Como os consumidores precisam manter todas as mensagens na memória enquanto estão sendo processadas, um alto valor de pré-busca pode ter um impacto negativo na performance de seus consumidores e, em alguns casos, pode resultar em um consumidor potencialmente travando tudo. Da mesma forma, o próprio agente RabbitMQ mantém todas as mensagens que envia armazenadas em cache na memória até receber reconhecimento do consumidor. Um valor de pré-busca alto pode fazer com que o servidor RabbitMQ fique sem memória rapidamente se a confirmação automática não estiver configurada para os consumidores e se os consumidores demorarem um tempo relativamente longo para processar mensagens.
Com as considerações acima em mente, recomendamos sempre definir um valor de pré-busca para evitar situações em que um agente RabbitMQ ou seus consumidores ficam sem memória devido a um grande número de mensagens não processadas ou não confirmadas. Se você precisar otimizar seus agentes para processar grandes volumes de mensagens, você pode testar seus agentes e consumidores usando uma gama de contagens de pré-busca para determinar o valor em que ponto a sobrecarga de rede se torna em grande parte insignificante em comparação com o tempo que um consumidor leva para processar mensagens.
nota
Se as aplicações do seu cliente tiverem configurado para confirmar automaticamente a entrega de mensagens aos consumidores, a definição de um valor de pré-busca não terá efeito.
Todas as mensagens pré-buscadas são removidas da fila.
O exemplo a seguir demonstra a configuração de um valor de pré-busca de 10 para um único consumidor usando a biblioteca do cliente Java RabbitMQ.
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
nota
Na biblioteca do cliente Java RabbitMQ, o valor padrão para global está definido como false, de modo que o exemplo acima pode ser escrito simplesmente como channel.basicQos(10).
Etapa 4: usar o Celery 5.5 ou posterior com filas de quórum
O Python Celery
Para todas as versões do Celery
-
Desative
task_create_missing_queuespara mitigar a rotatividade da fila. -
Em seguida, desative
worker_enable_remote_controlpara interromper a criação dinâmica decelery@...pidboxfilas. Isso reduzirá a rotatividade de filas na corretora.worker_enable_remote_control = false -
Para reduzir ainda mais a atividade de mensagens não críticas, desative o Celery worker-send-task-events
sem incluir -Eou--task-eventssinalizar ao iniciar seu aplicativo Celery. -
Inicie seu aplicativo Celery usando os seguintes parâmetros:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
Para as versões 5.5 e superiores do Celery
-
Atualize para a versão 5.5 do Celery
, a versão mínima que suporta filas de quórum, ou uma versão posterior. Para verificar qual versão do Celery você está usando, use celery --version. Para obter mais informações sobre filas de quórum, consulte. Filas de quórum do RabbitMQ no Amazon MQ -
Depois de atualizar para o Celery 5.5 ou posterior, configure
task_default_queue_typepara “quorum”. -
Em seguida, você também deve ativar a opção Publicar confirmações nas opções de transporte da corretora
: broker_transport_options = {"confirm_publish": True}
