Avaliar a capacidade provisionada para o provisionamento do tamanho certo de uma tabela do DynamoDB
Esta seção apresenta uma visão geral de como avaliar o provisionamento adequado para a tabela do DynamoDB. À medida que sua workload evolui, você deve modificar seus procedimentos operacionais adequadamente, especialmente quando sua tabela do DynamoDB está configurada no modo provisionado e você corre o risco de provisionar demais ou subprovisionar suas tabelas.
Os procedimentos descritos abaixo exigem informações estatísticas que devem ser capturadas das tabelas do DynamoDB que oferecem suporte à sua aplicação de produção. Para entender o comportamento da sua aplicação, você deve definir um período de tempo significativo o suficiente para capturar a sazonalidade dos dados da aplicação. Por exemplo, se a aplicação mostrar padrões semanais, usar um período de três semanas deve fornecer espaço suficiente para analisar as necessidades de throughput da aplicação.
Se não souber por onde começar, use pelo menos um mês de uso de dados para os cálculos abaixo.
Ao avaliar a capacidade, as tabelas do DynamoDB podem configurar unidades de capacidade de leitura (RCUs) e unidades de capacidade de gravação (WCU) de forma independente. Se as suas tabelas tiverem algum Índice Secundário Global (GSI) configurado, você deverá especificar o throughput que ela consumirá, que também será independente das RCUs e WCUs da tabela-base.
nota
Os índices secundários locais (LSI) consomem a capacidade da tabela-base.
Tópicos
Como recuperar métricas de consumo em suas tabelas do DynamoDB
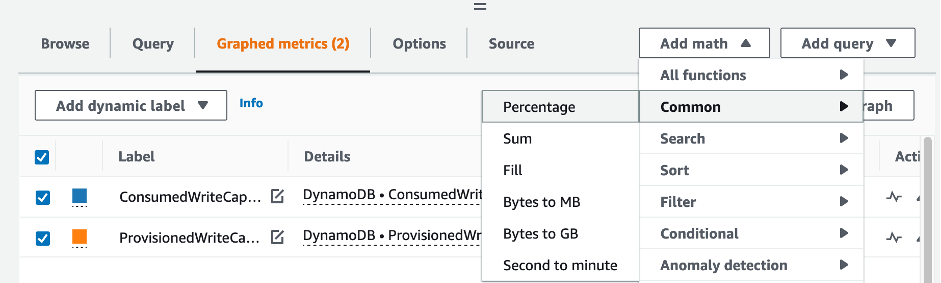
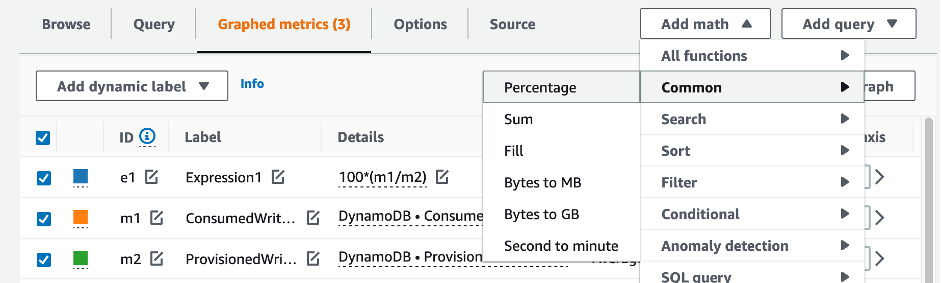
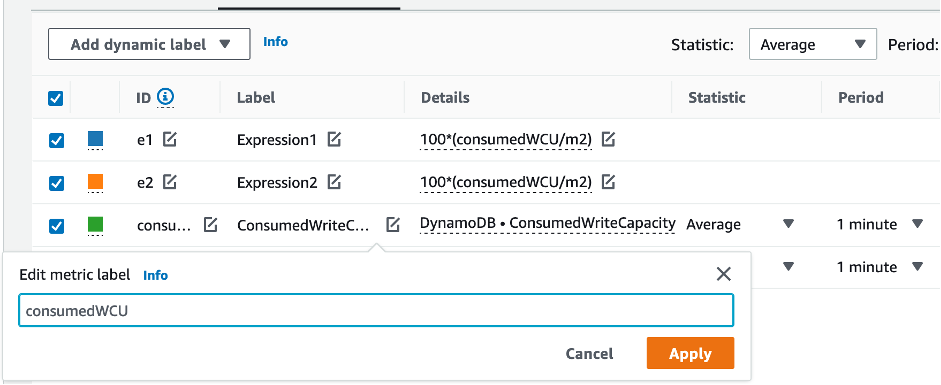
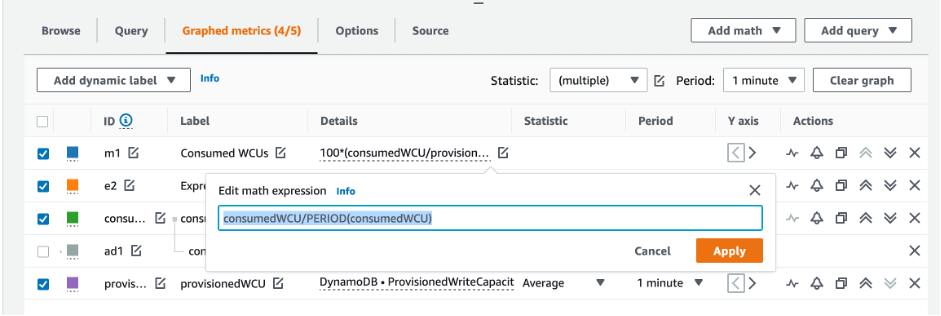
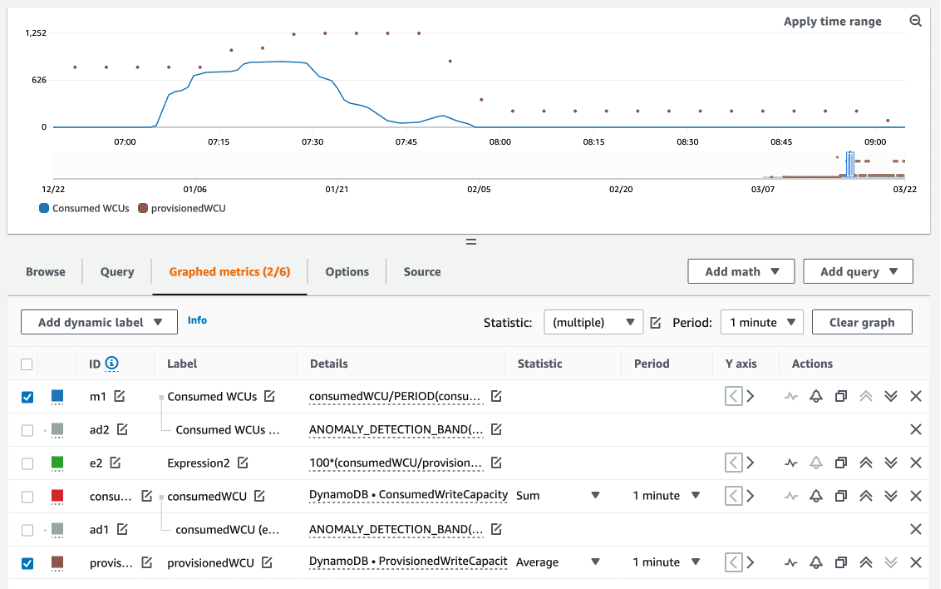
Para avaliar a tabela e a capacidade do GSI, monitore as seguintes métricas do CloudWatch e selecione a dimensão apropriada para recuperar as informações da tabela ou do GSI:
| Unidades de capacidade de leitura | Unidades de capacidade de gravação |
|---|---|
|
|
|
|
|
|
|
|
|
Você pode fazer isso por meio da AWS CLI ou do AWS Management Console.







Como identificar tabelas do DynamoDB subprovisionadas
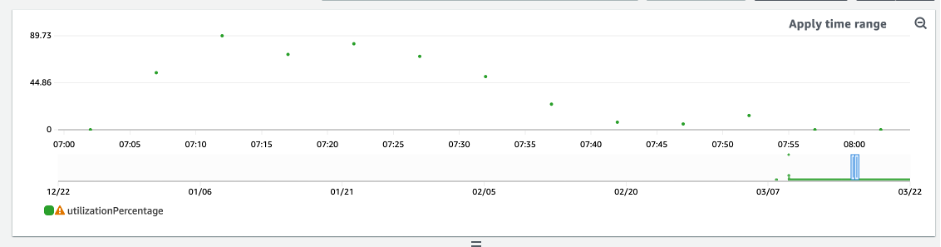
Para a maioria das workloads, uma tabela é considerada subprovisionada quando consome constantemente mais de 80% de sua capacidade provisionada.
A capacidade de expansão é um recurso do DynamoDB que permite que os clientes consumam temporariamente mais RCUS/WCUs do que o provisionado originalmente (mais do que o throughput provisionado por segundo definido na tabela). A capacidade de expansão foi criada para absorver aumentos repentinos no tráfego devido a eventos especiais ou picos de uso. Essa capacidade de expansão não dura para sempre. Assim que as RCUs e WCUs não utilizadas forem esgotadas, você terá controle de utilização se tentar consumir mais capacidade do que a provisionada. Quando o tráfego do sua aplicação está se aproximando da taxa de utilização de 80%, o risco de controle de utilização é significativamente maior.
A regra da taxa de utilização de 80% varia com a sazonalidade de seus dados e com o crescimento do tráfego. Considere os seguintes cenários:
-
Se o seu tráfego se manteve estável com uma taxa de utilização de ~90% nos últimos 12 meses, sua tabela tem a capacidade certa
-
Se o tráfego da sua aplicação estiver crescendo a uma taxa de 8% ao mês em menos de 3 meses, você chegará a 100%
-
Se o tráfego da sua aplicação estiver crescendo a uma taxa de 5% em pouco mais de 4 meses, você ainda chegará a 100%
Os resultados das consultas acima fornecem uma imagem da sua taxa de utilização. Use-os como um guia para avaliar melhor outras métricas que podem ajudar você a escolher aumentar a capacidade da tabela conforme necessário (por exemplo: uma taxa de crescimento mensal ou semanal). Trabalhe com sua equipe de operações para definir qual é uma boa porcentagem para sua workload e suas tabelas.
Há cenários especiais em que os dados são distorcidos quando os analisamos diariamente ou semanalmente. Por exemplo, com aplicações sazonais que têm picos de uso durante o horário comercial (mas depois caem para quase zero fora do horário comercial), é possível se beneficiar do ajuste de escala automático programado, em que você especifica as horas do dia (e os dias da semana) para aumentar a capacidade provisionada e quando reduzi-la. Em vez de buscar maior capacidade para cobrir as horas de pico, também é possível se beneficiar das configurações de ajuste de escala automático de tabelas do DynamoDB se a sua sazonalidade for menos acentuada.
nota
Ao criar uma configuração de Auto Scaling do DynamoDB para sua tabela-base, lembre-se de incluir outra configuração para qualquer GSI associado à tabela.
Como identificar tabelas superprovisionadas do DynamoDB
Os resultados da consulta obtidos dos scripts acima fornecem os pontos de dados necessários para realizar algumas análises iniciais. Se o seu conjunto de dados apresentar valores inferiores a 20% de utilização em vários intervalos, sua tabela pode estar superprovisionada. Para definir melhor se você precisa reduzir o número de WCUs e RCUS, revise as outras leituras nos intervalos.
Quando suas tabelas contêm vários intervalos de uso baixos, é possível se beneficiar do uso de políticas de ajuste de escala automático, seja programando o ajuste de escala automático ou simplesmente configurando as políticas de ajuste de escala automático padrão para a tabela, com base na utilização.
Se você tem uma workload com baixa utilização e alta taxa de controle de utilização (Max(ThrottleEvents)/Min(ThrottleEvents) no intervalo), isso pode acontecer quando você tem uma workload com muitos picos, em que o tráfego aumenta muito durante alguns dias (ou horas), mas, em geral, o tráfego é consistentemente baixo. Nesses cenários, pode ser benéfico usar o ajuste de escala automático programado.
