Índices secundários locais
Alguns aplicativos só precisam consultar dados usando a chave primária da tabela base. No entanto, podem haver situações em que uma chave de classificação alternativa seria útil. Para oferecer à sua aplicação opções de chaves de classificação, você pode criar um ou mais índices secundários locais em uma tabela do Amazon DynamoDB e emitir solicitações de Query ou Scan nesses índices.
Tópicos
Cenário: Uso de um índice secundário local
Como exemplo, considere a tabela Thread. Esta tabela é útil para aplicações como os Fóruns de discussão da AWS
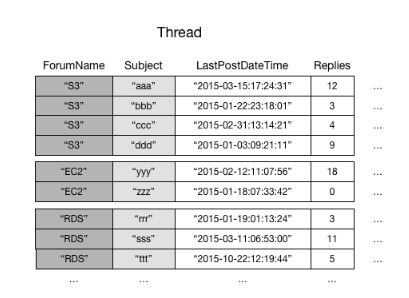
O DynamoDB armazena continuamente todos os itens com o mesmo valor de chave de partição. Neste exemplo, dado um determinado ForumName, uma operação Query poderia localizar imediatamente todos os threads desse fórum. Em um grupo de itens com o mesmo valor de chave de partição, os itens são classificados pelo valor de chave de classificação. Se a chave de classificação (Subject) também for fornecida na consulta, o DynamoDB poderá reduzir os resultados que são retornados. Por exemplo, retornar todos os threads do fórum "S3" em que Subject começa com a letra "a".
Algumas solicitações podem exigir padrões mais complexos de acesso aos dados. Por exemplo:
-
Quais threads do fórum recebem visualizações e respostas?
-
Qual thread em um determinado fórum tem o maior número de mensagens?
-
Quantos threads foram publicados em um fórum específico em um determinado período?
A ação Query não seria suficiente para responder a essas perguntas. Em vez disso, você teria de Scan toda a tabela. Para uma tabela com milhões de itens, isso poderia consumir uma grande quantidade de throughput provisionado de leitura e levar muito tempo para ser concluído.
No entanto, é possível especificar um ou mais índices secundários em atributos que não são chaves, como Replies ou LastPostDateTime.
Um índice secundário local mantém uma chave de classificação alternativa para um determinado valor de chave de partição. Um índice secundário local também contém uma cópia de alguns ou de todos os atributos de sua tabela-base. Você especifica quais atributos são projetados no índice secundário local ao criar a tabela. Os dados em um índice secundário local são organizados com a mesma chave de partição que a tabela-base, mas com outra chave de classificação. Isso permite que você acesse os itens de dados de forma eficiente nessa dimensão diferente. Para uma maior flexibilidade de consulta ou verificação, você pode criar até cinco índices secundários locais por tabela.
Suponha que um aplicativo precise encontrar todos os threads que foram publicados nos últimos três meses em um fórum específico. Sem um índice secundário local, a aplicação precisaria realizar Scan de toda a tabela Thread e descartar todas as publicações que não estivessem dentro do período especificado. Com um índice secundário local, uma operação de Query poderia usar LastPostDateTime como uma chave de classificação e encontrar os dados rapidamente.
O diagrama a seguir mostra um índice secundário local chamado LastPostIndex. Observe que a chave de partição é a mesma que a da tabela Thread, mas a chave de classificação é LastPostDateTime.
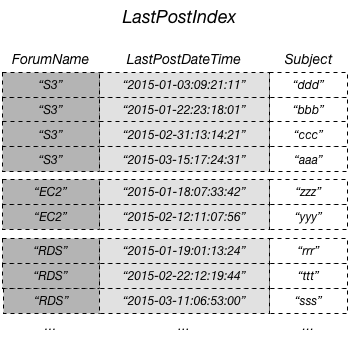
Cada índice secundário local deve atender às seguintes condições:
-
A chave de partição é a mesma que a de sua tabela-base.
-
A chave de classificação consiste em exatamente um atributo escalar.
-
A chave de classificação da tabela-base é projetada no índice, onde ela atua como um atributo que não é chave.
Neste exemplo, a chave de partição é ForumName e a chave de classificação do índice secundário local é LastPostDateTime. Além disso, o valor da chave de classificação da tabela base (neste exemplo, Subject) é projetado no índice, mas não faz parte da chave do índice. Se um aplicativo precisar de uma lista baseada em ForumName e LastPostDateTime, ele poderá emitir uma solicitação de Query com relação a LastPostIndex. Os resultados da consulta são classificados por LastPostDateTime e podem ser retornados em ordem crescente ou decrescente. A consulta também pode aplicar condições de chave, como retornar apenas os itens que têm uma LastPostDateTime dentro de um período específico.
Cada índice secundário local contém automaticamente as chave de partição e de classificação de sua tabela-base, mas você pode opcionalmente projetar atributos não chave no índice. Quando você consultar o índice, o DynamoDB poderá recuperar esses atributos projetados com eficiência. Quando você consulta um índice secundário local, a consulta também pode recuperar atributos que não são projetados no índice. O DynamoDB buscará automaticamente esses atributos na tabela-base, mas com uma latência maior e com custos de throughput provisionado mais altos.
Para qualquer índice secundário local, você pode armazenar até 10 GB de dados por valor de chave de partição distinta. Esta imagem inclui todos os itens na tabela-base, além de todos os itens nos índices, que têm o mesmo valor de chave de partição. Para obter mais informações, consulte Conjuntos de itens em índices secundários locais.
Projeções de atributo
Com LastPostIndex, um aplicativo poderia usar ForumName e LastPostDateTime como critérios de consulta. No entanto, para recuperar qualquer atributo adicional, o DynamoDB deve executar operações de leitura adicionais na tabela Thread. Essas leituras extras são conhecidas como buscas e podem aumentar a quantidade total de throughput provisionado necessário para uma consulta.
Suponha que você quisesse preencher uma página da Web com uma lista de todos os threads de "S3" e o número de respostas para cada thread, classificados pela última data/hora de resposta, começando pela resposta mais recente. Para preencher essa lista, você precisaria dos seguintes atributos:
-
Subject -
Replies -
LastPostDateTime
A maneira mais eficiente de consultar esses dados e evitar operações de busca seria projetar o atributo Replies da tabela no índice secundário local conforme mostrado neste diagrama.
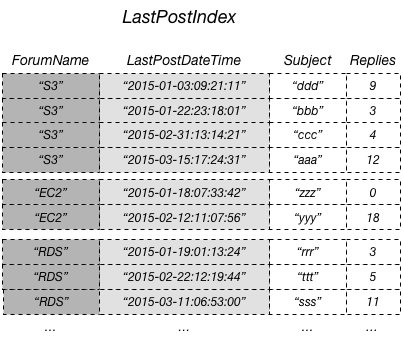
Uma projeção é o conjunto de atributos que é copiado de uma tabela para um índice secundário. A chave de partição e a chave de classificação da tabela são sempre projetadas no índice; você pode projetar outros atributos para suportar os requisitos de consulta da sua aplicação. Quando você consulta um índice, o Amazon DynamoDB pode acessar quaisquer atributos na projeção como se estivessem em uma tabela própria.
Quando você cria um índice secundário, é necessário especificar os atributos que serão projetados no índice. O DynamoDB proporciona três opções diferentes para fazer isso:
-
KEYS_ONLY: cada item do índice consiste apenas nos valores de chaves de partição e nas chaves de classificação da tabela, além dos valores de chaves do índice. A opção
KEYS_ONLYresulta no menor índice secundário possível. -
INCLUDE: além dos atributos descritos em
KEYS_ONLY, o índice secundário incluirá outros atributos não chave que você especificar. -
ALL: o índice secundário inclui todos os atributos da tabela de origem. Como todos os dados da tabela são duplicados no índice, uma projeção
ALLresulta no maior índice secundário possível.
No diagrama anterior, o atributo Replies que não é chave é projetado em LastPostIndex. Um aplicativo pode consultar LastPostIndex em vez da tabela Thread completa para preencher uma página da Web com Subject, Replies e LastPostDateTime. Se quaisquer outros atributos que não são chaves forem solicitados, o DynamoDB precisará buscar esses atributos na tabela Thread.
Do ponto de vista de um aplicativo, buscar atributos adicionais da tabela-base é automático e transparente, portanto, não há necessidade de reescrever qualquer lógica de aplicativo. No entanto, essa busca pode reduzir significativamente a vantagem de performance proporcionada pelo uso de um índice secundário local.
Ao escolher os atributos para projetar em um índice secundário local, você deve considerar a desvantagem entre os custos de throughput provisionado e os custos de armazenamento:
-
Se você precisar acessar apenas alguns atributos com a latência mais baixa possível, considere projetar apenas os atributos em um índice secundário local. Quanto menor o índice, menores serão os custos de armazenamento e de gravação. Se houver atributos que você precisa buscar ocasionalmente, o custo de throughput provisionado pode ultrapassar o custo por um prazo mais longo do armazenamento desses atributos.
-
Se sua aplicação acessar frequentemente alguns atributos não chave, considere projetar esses atributos em um índice secundário local. Os custos adicionais de armazenamento do índice secundário local compensarão o custo de executar verificações de tabelas frequentes.
-
Se precisar acessar a maioria dos atributos não chave com frequência, você poderá projetar esses atributos, inclusive a tabela-base inteira, em um índice secundário local. Isso fornece flexibilidade máxima e menor consumo de throughput provisionado, porque nenhuma busca será necessária. No entanto, o custo do armazenamento deve aumentar ou até dobrar se você estiver projetando todos os atributos.
-
Se o seu aplicativo precisa consultar uma tabela com pouca frequência, mas deve realizar muitas gravações ou atualizações nos dados na tabela, pense em projetar KEYS_ONLY. O índice secundário local seria de tamanho mínimo, mas ainda estaria disponível quando necessário para a atividade de consulta.
Criação de um índice secundário local
Para criar um ou mais índices secundários locais, use o parâmetro LocalSecondaryIndexes da operação CreateTable. Os índices secundários locais em uma tabela são criados quando a tabela é criada. Quando você exclui uma tabela, todos os índices secundários locais da tabela também são excluídos.
Você deve especificar um atributo não chave para atuar como a chave de classificação do índice secundário local. O atributo escolhido deve ser de um tipo escalar como String, Number ou Binary Outros tipos escalares, tipos de documento e tipos de conjunto não são permitidos. Para obter uma lista completa de tipos de dados, consulte Tipos de dados.
Importante
Para tabelas com índices secundários locais, há um limite de tamanho de 10 GB para cada valor de chave de partição. Uma tabela com índices secundários locais pode armazenar qualquer número de itens, desde que o tamanho total de qualquer valor de chave de partição não exceda 10 GB. Para obter mais informações, consulte Limite de tamanho de conjunto de itens.
Você pode projetar atributos de qualquer tipo de dados em um índice secundário local. Isso inclui escalares, documentos e conjuntos. Para obter uma lista completa de tipos de dados, consulte Tipos de dados.
Ler dados de um índice secundário local
Você pode recuperar itens de um índice secundário local usando as operações Query e Scan. As operações GetItem e BatchGetItem não podem ser usadas em um índice secundário local.
Como consultar um índice secundário local
Em uma tabela do DynamoDB, o valor da chave de partição combinada e o valor da chave de classificação de cada item devem ser exclusivos. No entanto, em um índice secundário local, o valor da chave de classificação não precisa ser exclusivo para um determinado valor de chave de partição. Se houver vários itens no índice secundário local com o mesmo valor de chave de classificação, uma operação Query retornará todos os itens que têm o mesmo valor de chave de partição. Na resposta, os itens correspondentes não são retornados em uma ordem específica.
Você pode consultar um índice secundário local usando leituras fortemente consistentes ou finais consistentes. Para especificar qual tipo de consistência você deseja, use o parâmetro ConsistentRead da operação Query. Uma leitura fortemente consistente de um índice secundário local sempre retorna os valores atualizados mais recentes. Se a consulta precisar buscar atributos adicionais na tabela base, esses atributos serão consistentes com relação ao índice.
exemplo
Considere os seguintes dados retornados de uma Query que solicita dados dos threads de discussão em um determinado fórum.
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
Nesta consulta:
-
O DynamoDB acessa
LastPostIndexusando a chave de partiçãoForumNamepara localizar os itens do índice para o "EC2". Todos os itens do índice com essa chave são armazenados lado a lado para rápida recuperação. -
Neste fórum, o DynamoDB usa o índice para pesquisar as chaves que correspondem à condição
LastPostDateTimeespecificada. -
Como o atributo
Repliesé projetado no índice, o DynamoDB pode recuperar esse atributo sem consumir nenhum throughput provisionado adicional. -
O atributo
Tagsnão é projetado no índice, portanto, o DynamoDB deve acessar a tabelaThreade buscar esse atributo. -
Os resultados são retornados, classificados por
LastPostDateTime. As entradas de índice são classificadas por valor de chave de partição e, em seguida, pelo valor de chave de classificação, eQueryretorna-as na ordem em que são armazenadas. (Você pode usar o parâmetroScanIndexForwardpara retornar os resultados em ordem decrescente.)
Como o atributo Tags não é projetado no índice secundário local, o DynamoDB deve consumir unidades de capacidade de leitura adicionais para buscar esse atributo na tabela-base. Se for necessário executar essa consulta com frequência, projete Tags no LastPostIndex para evitar a busca na tabela base. No entanto, se for necessário acessar Tags apenas ocasionalmente, o custo do armazenamento adicional para a projeção de Tags no índice pode não valer a pena.
Verificação de um índice secundário local
Você pode usar Scan para recuperar todos os dados de um índice secundário local. Você deve fornecer o nome da tabela-base e o nome de índice na solicitação. Com uma operação Scan, o DynamoDB lê todos os dados do índice e os retorna para a aplicação. Você também pode solicitar que apenas alguns dos dados sejam retornados, e que os dados restantes sejam descartados. Para fazer isso, use o parâmetro FilterExpression da API Scan. Para obter mais informações, consulte Expressões de filtro para verificação.
Gravações de itens e índices secundários locais
O DynamoDB mantém automaticamente todos os índices secundários locais sincronizados com suas respectivas tabelas base. Os aplicativos nunca gravam diretamente em um índice. No entanto, é importante compreender as implicações de como o DynamoDB mantém esses índices.
Ao criar um índice secundário local, você especifica um atributo para servir como a chave de classificação do índice. Você também especifica um tipo de dados desse atributo. Isso significa que sempre que você grava um item na tabela-base, se o item define um atributo de chave do índice, seu tipo deve corresponder ao tipo de dados do esquema de chaves do índice. No caso de LastPostIndex, a chave de classificação de LastPostDateTime no índice é definida como um tipo de dados String. Se você tentar adicionar um item à tabela Thread e especificar um tipo de dados diferente para LastPostDateTime (como Number), o DynamoDB retornará uma ValidationException devido à inconsistência do tipo de dados.
Não há necessidade de um relacionamento de um para um entre os itens em uma tabela-base e os itens em um índice secundário local. Na verdade, esse comportamento pode ser vantajoso para muitas aplicações.
Os custos das atividades de gravação em uma tabela com muitos índices secundários serão mais altos do que em uma tabela com um número menor de índices. Para obter mais informações, consulte Considerações sobre throughput provisionado para índices secundários locais.
Importante
Para tabelas com índices secundários locais, há um limite de tamanho de 10 GB para cada valor de chave de partição. Uma tabela com índices secundários locais pode armazenar qualquer número de itens, desde que o tamanho total de qualquer valor de chave de partição não exceda 10 GB. Para obter mais informações, consulte Limite de tamanho de conjunto de itens.
Considerações sobre throughput provisionado para índices secundários locais
Ao criar uma tabela no DynamoDB, você provisiona unidades de capacidade de leitura e gravação para a workload esperada na tabela. Essa workload inclui a atividade de leitura e gravação nos índices secundários locais da tabela.
Para visualizar as taxas atuais da capacidade de throughput provisionado, acesse Preços do Amazon DynamoDB
Unidades de capacidade de leitura
Quando você consulta um índice secundário local, o número de unidades de capacidade de leitura consumidas depende de como os dados são acessados.
Assim como ocorre com as consultas de tabela, uma consulta de índice pode usar leituras fortemente consistentes ou eventualmente consistentes, dependendo do valor de ConsistentRead. Uma leitura fortemente consistente consome uma unidade de capacidade de leitura, uma leitura eventualmente consistente consome apenas metade disso. Assim, escolhendo leituras eventualmente consistentes, você pode reduzir seus encargos de unidade de capacidade de leitura.
Para consultas do índice que solicitam apenas chaves de índice e atributos projetados, o DynamoDB calcula a atividade de leitura provisionada da mesma forma que para consultas em tabelas. A única diferença é que o cálculo é baseado no tamanho das entradas de índice, em vez do tamanho do item na tabela-base. O número de unidades de capacidade de leitura é a soma de todos os tamanhos de atributos projetados em todos os itens retornados; o resultado é, então, arredondado para o próximo limite de 4 KB. Para obter mais informações sobre como o DynamoDB calcula a utilização de throughput provisionado, consulte Modo de capacidade provisionada do DynamoDB.
Para consultas de índice que leem atributos que não estão projetados no índice secundário local, o DynamoDB precisa buscar esses atributos na tabela-base, além de ler os atributos projetados no índice. Essas buscas ocorrem quando você inclui quaisquer atributos não projetados nos parâmetros Select ou ProjectionExpression da operação Query. A busca causa latência adicional nas respostas da consulta, e também incorre em um custo mais alto de throughput provisionado: além das leituras do índice secundário local descritas acima, você é cobrado pelas unidades de capacidade de leitura de cada item buscado na tabela-base. Essa cobrança é para ler cada item inteiro da tabela, não apenas os atributos solicitados.
O tamanho máximo dos resultados retornados por uma operação Query é 1 MB. Isso inclui os tamanhos de todos os nomes e valores de atributos de todos os itens retornados. No entanto, se uma consulta em um índice secundário local fizer o DynamoDB buscar atributos de item na tabela-base, o tamanho máximo dos dados no resultado poderá ser menor. Neste caso, o tamanho do resultado é a soma de:
-
O tamanho dos itens correspondentes no índice, arredondado para os próximos 4 KB.
-
O tamanho de cada item correspondente na tabela-base, com cada item individualmente arredondado para os próximos 4 KB.
Usando esta fórmula, o tamanho máximo dos resultados retornados por uma operação Query ainda é 1 MB.
Por exemplo, considere uma tabela na qual o tamanho de cada item é 300 bytes. Há um índice secundário local nessa tabela, mas apenas 200 bytes de cada item são projetados no índice. Agora, suponha que você use a operação Query nesse índice, que a consulta requer buscas de tabela para cada item e que a consulta retorne 4 itens. O DynamoDB soma o seguinte:
-
O tamanho dos itens correspondentes no índice: 200 bytes × 4 itens = 800 bytes; isso é, então, arredondado para 4 KB.
-
O tamanho de cada item correspondente na tabela-base: (300 bytes, arredondados para 4 KB) × 4 itens = 16 KB.
O tamanho total dos dados no resultado é, portanto, 20 KB.
Unidades de capacidade de gravação
Quando um item é adicionado, atualizado ou excluído de uma tabela, a atualização dos índices secundários locais consome unidades de capacidade de gravação provisionadas para a tabela. O custo total do throughput provisionado para uma gravação é a soma das unidades de capacidade de gravação consumidas pela gravação na tabela e aquelas consumidas pela atualização dos índices secundários locais.
O custo de gravar um item em um índice secundário local depende de vários fatores:
-
Se você gravar um novo item na tabela que define um atributo indexado, ou atualizar um item existente para definir um atributo indexado indefinido anteriormente, uma operação de gravação é necessária para inserir o item no índice.
-
Se uma atualização na tabela alterar o valor de um atributo de chave indexado (de A para B), duas gravações serão necessárias, uma para excluir o item anterior do índice e outra gravação para inserir o novo item no índice.
-
Se um item estava presente no índice, mas uma gravação na tabela fez com que o atributo indexado fosse excluído, uma gravação é necessária para excluir a projeção do item antigo do índice.
-
Se um item não estiver presente no índice antes ou depois que o item é atualizado, não haverá custo de gravação adicionais para o índice.
Todos esses fatores supõem que o tamanho de cada item no índice seja menor ou igual ao tamanho de item de 1 KB para calcular unidades de capacidade de gravação. Entradas de índice maiores exigirão unidades adicionais de capacidade de gravação. Você pode minimizar os custos de gravação considerando de quais atributos suas consultas precisam para retornar e projetar apenas esses atributos no índice.
Considerações sobre armazenamento para índices secundários locais
Quando uma aplicação grava um item em uma tabela, o DynamoDB copia automaticamente o subconjunto correto de atributos em todos os índices secundários locais nos quais esses atributos devem aparecer. Sua conta da AWS é cobrada pelo armazenamento do item na tabela-base e também pelo armazenamento dos atributos em todos os índices secundários locais nessa tabela.
A quantidade de espaço usada por um item do índice é a soma do seguinte:
-
O tamanho em bytes da chave primária da tabela-base (chave de partição e chave de classificação)
-
O tamanho em bytes do atributo de chave do índice
-
O tamanho em bytes dos atributos projetados (se houver)
-
100 bytes de sobrecarga por item de índice
Para estimar os requisitos de armazenamento de um índice secundário local, você pode estimar o tamanho médio de um item no índice e multiplicar pelo número de itens no índice.
Se uma tabela contiver um item em que um determinado atributo não está definido, mas esse atributo estiver definido como uma chave de classificação do índice, o DynamoDB não gravará nenhum dado desse item no índice.
Conjuntos de itens em índices secundários locais
nota
A seção refere-se apenas a tabelas que têm índices secundários locais.
No DynamoDB, uma coleção de itens é qualquer grupo de itens que têm o mesmo valor de chave de partição em uma tabela e todos os seus índices secundários locais. Nos exemplos usados nesta seção, a chave de partição da tabela Thread é ForumName, e a chave de partição de LastPostIndex também é ForumName. Todos os itens da tabela e do índice com o mesmo ForumName fazem parte da mesma coleção de itens. Por exemplo, na tabela Thread e no índice secundário local LastPostIndex, existe uma coleção de itens para o fórum do EC2 e uma coleção de itens diferente para o fórum do RDS.
O seguinte diagrama mostra a coleção de itens do fórum do S3.
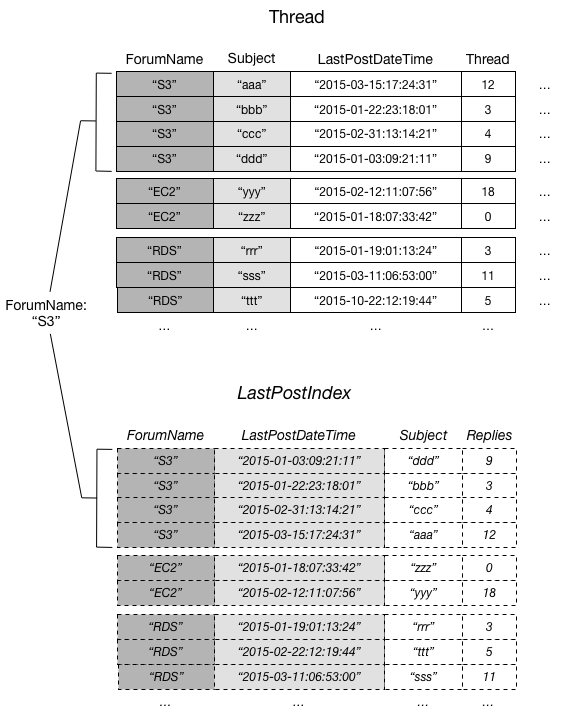
Neste diagrama, a coleção de itens consiste em todos os itens em Thread e LastPostIndex em que o valor da chave da partição ForumName é "S3". Se houver outros índices secundários locais na tabela, todos os itens nesses índices com ForumName igual a "S3" também farão parte da coleção de itens.
Você pode usar qualquer uma das operações a seguir no DynamoDB para retornar informações sobre coleções de itens:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
Cada uma dessas operações é compatível com o parâmetro ReturnItemCollectionMetrics. Ao definir esse parâmetro como SIZE, você pode exibir informações sobre o tamanho de cada coleção de itens no índice.
exemplo
Este é um exemplo da saída de uma operação UpdateItem na tabela Thread, com ReturnItemCollectionMetrics definido como SIZE. O item que foi atualizado tinha um valor ForumName de "EC2", portanto, a saída inclui informações sobre essa coleção de itens.
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
O objeto SizeEstimateRangeGB mostra que o tamanho dessa coleção de itens está entre 0 e 1 GB. O DynamoDB atualiza periodicamente essa estimativa de tamanho, portanto, os números podem ser diferentes na próxima vez em que o item é modificado.
Limite de tamanho de conjunto de itens
O tamanho máximo de qualquer coleção de itens para uma tabela com um ou mais índices secundários locais é 10 GB. Isso não se aplica a coleções de itens em tabelas sem índices secundários locais e também não se aplica a coleções de itens em índices secundários globais. Apenas as tabelas que têm um ou mais índices secundários locais são afetadas.
Se uma coleção de itens exceder o limite de 10 GB, o DynamoDB pode retornar um ItemCollectionSizeLimitExceededException, e você não poderá adicionar mais itens à coleção de itens ou aumentar os tamanhos dos itens que estão na coleção de itens. (As operações de leitura e gravação que diminuem o tamanho da coleção de itens ainda são permitidas.) Você ainda pode adicionar itens a outras coleções de itens.
Para reduzir o tamanho de uma coleção de itens, você pode executar uma das seguintes ações:
-
Excluir todos os itens desnecessários com o valor da chave de partição em questão. Quando você exclui esses itens da tabela-base, o DynamoDB também remove todas as entradas do índice que têm o mesmo valor de chave de partição.
-
Atualize os itens, removendo atributos ou reduzindo o tamanho dos atributos. Se esses atributos forem projetados em qualquer índice secundário local, o DynamoDB também reduzirá o tamanho das entradas do índice correspondentes.
-
Crie uma nova tabela com a mesma chave de partição e chave de classificação e, em seguida, mova os itens da tabela antiga para a nova tabela. Essa pode ser uma boa abordagem, se uma tabela tiver dados históricos que são acessados com pouca frequência. Você também pode considerar arquivar esses dados históricos no Amazon Simple Storage Service (Amazon S3).
Quando o tamanho total da coleção de itens tornar-se inferior a 10 GB, você poderá adicionar itens novamente com o mesmo valor de chave de partição.
Recomendamos como uma melhor prática que você instrumente seu aplicativo para monitorar os tamanhos de suas coleções de itens. Uma maneira de fazer isso é definir o parâmetro ReturnItemCollectionMetrics como SIZE sempre que você usar BatchWriteItem, DeleteItem, PutItem ou UpdateItem. Seu aplicativo deve examinar o objeto ReturnItemCollectionMetrics na saída e gerar uma mensagem de erro sempre que uma coleção de itens exceder um limite definido pelo usuário (por exemplo, 8 GB). Configurar um limite menor que 10 GB oferece um sistema de aviso antecipado para que você saiba que uma coleção de itens está se aproximando do limite a tempo de resolver o problema.
Conjuntos de itens e partições
Em uma tabela com um ou mais índices secundários locais, uma coleção de itens é armazenada em uma partição. O tamanho total dessa coleção de itens é limitado à capacidade dessa partição: 10 GB. Para uma aplicação em que o modelo de dados inclui coleções de itens de tamanho ilimitado ou na qual a expectativa é de que algumas coleções de itens aumentem além de 10 GB no futuro, pense em usar um índice secundário global.
Você deve criar seus aplicativos para que os dados da tabela sejam distribuídos uniformemente entre diferentes valores de chave de partição. Para tabelas com índices secundários locais, seus aplicativos não devem criar pontos de atividade de leitura e gravação em uma única coleção de itens em uma única partição.
