Usar índices secundários globais para consultas de agregação materializadas no DynamoDB
Manter as agregações quase em tempo real e as métricas de chaves relacionadas aos dados em constante mudança é uma operação cada vez mais valiosa para a rápida tomada de decisões na empresa. Por exemplo, uma biblioteca de músicas pode querer apresentar suas músicas que mais foram obtidas por download quase em tempo real.
Considere o seguinte layout de tabela da biblioteca de músicas:
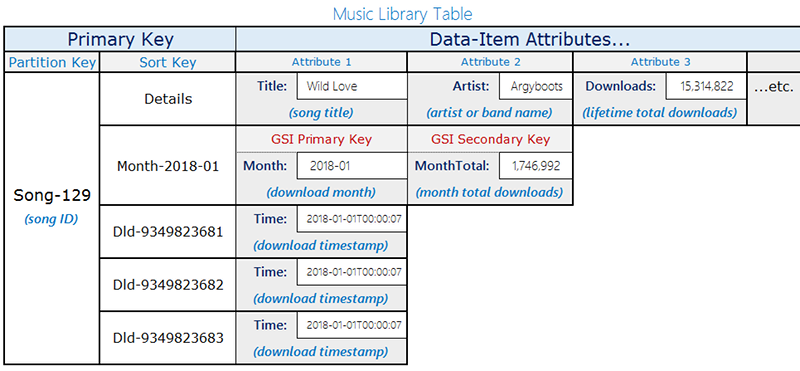
A tabela neste exemplo armazena músicas com songID como a chave de partição. Você pode habilitar Amazon DynamoDB Streams nessa tabela e conectar uma função do Lambda aos fluxos de modo que, à medida que o download de cada música for feito, uma entrada seja adicionada à tabela com Partition-Key=SongID e Sort-Key=DownloadID. Conforme essas atualizações são feitas, elas ativam uma função do Lambda nos DynamoDB Streams. A função do Lambda pode agregar e agrupar os downloads por songID e atualizar o item de nível superior, Partition-Key=songID e Sort-Key=Month. Tenha em mente que se uma execução do Lambda falhar logo após escrever o novo valor agregado, ela pode ser repetida e agregar o valor mais de uma vez, deixando você com um valor aproximado.
Para ler as atualizações quase em tempo real, com latência de milissegundo de um único dígito, use o índice secundário global com condições de consulta Month=2018-01, ScanIndexForward=False, Limit=1.
Outra otimização de chave usada aqui é que o índice secundário global é um índice esparso e está disponível somente nos itens que precisam ser consultados para recuperar os dados em tempo real. O índice secundário global pode atender aso fluxos de trabalho adicionais que precisam de informações sobre as 10 primeiras músicas que eras populares, ou qualquer música transferida naquele mês.
