Sobrecarga de índices secundários globais no DynamoDB
Embora o Amazon DynamoDB tenha uma cota padrão de 20 índices secundários globais por tabela, na prática é possível indexar muito mais do que 20 campos de dados. Ao contrário de uma tabela em um sistema de banco de dados relacional (RDBMS) em que o esquema é uniforme, uma tabela no DynamoDB pode guardar muitos tipos diferentes de itens de dados ao mesmo tempo. Além disso, os mesmos atributos em diferentes itens podem conter tipos de informações totalmente diferentes.
Considere o seguinte exemplo de um layout de tabela do DynamoDB que salva vários tipos diferentes de dados.
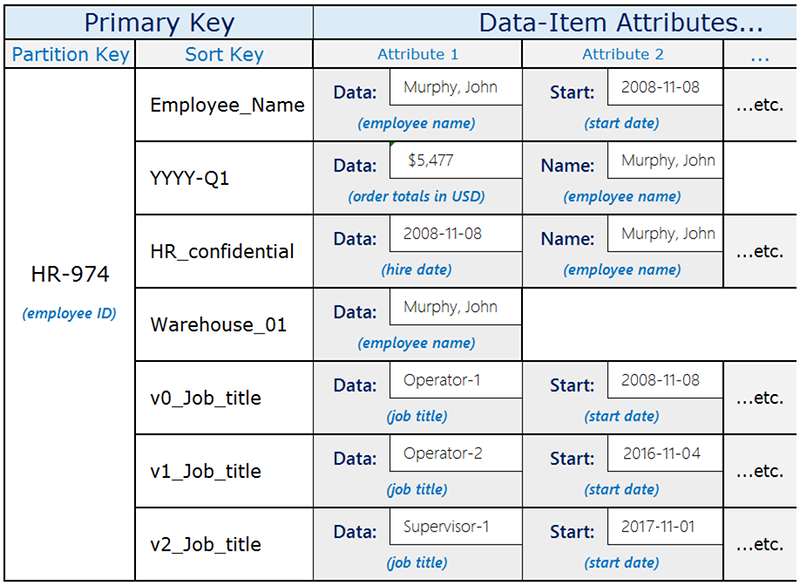
O atributo Data, que é comum para todos os itens, tem conteúdo diferente dependendo do item pai. Se você criar um índice secundário global para a tabela que usa a chave de classificação da tabela como sua chave de partição e o atributo Data como sua chave de classificação, poderá fazer uma variedade de consultas diferentes usando esse único índice secundário global. Essas consultas podem incluir o seguinte:
Procure um funcionário por nome no índice secundário global usando
Employee_Namecomo o valor da chave de partição e o nome do funcionário (por exemplo,Murphy, John) como valor de chave de classificação.Use o índice secundário global para encontrar todos os funcionários que trabalham em um determinado armazém procurando um ID de armazém (como
Warehouse_01).Obtenha uma lista de contratações recentes consultando o índice secundário global em
HR_confidentialcomo um valor de chave de partição e usando um intervalo de datas como o valor da chave de classificação.
