Práticas recomendadas para implementação de um sistema híbrido de banco de dados
Em algumas circunstâncias, migrar de um ou mais sistemas de gerenciamento de bancos de dados relacionais (RDBMS) para o Amazon DynamoDB talvez não seja vantajoso. Nesses casos, pode ser preferível criar um sistema híbrido.
Se você não quiser migrar tudo para o DynamoDB
Por exemplo, algumas organizações fazem grandes investimentos no código que produz inúmeros relatórios necessários para contabilidade e operações. O tempo necessário para gerar um relatório não é importante para elas. A flexibilidade de um sistema relacional é adequada para esse tipo de tarefa, e recriar todos os relatórios em um contexto NoSQL pode ser proibitivamente complicado.
Algumas organizações também mantêm uma variedade de sistemas relacionais herdados que adquiriram ou herdaram ao longo de décadas. A migração dos dados desses sistemas podem ser muito arriscada e cara para justificar o esforço.
Contudo, as mesmas organizações agora podem achar que suas operações dependem de sites de alto tráfego, voltados para os clientes, onde a resposta em milissegundo é essencial. Os sistemas relacionais não podem ser dimensionados para atender a esse requisito, exceto por uma despesa enorme (e frequentemente inaceitável).
Nessas situações, a resposta pode ser a criação de um sistema híbrido, em que o DynamoDB cria uma visualização materializada dos dados armazenados em um ou mais sistemas relacionais e lida com solicitações de alto tráfego nessa visualização. Esse tipo de sistema pode reduzir potencialmente os custos, ao eliminar as licenças de hardware de servidor, manutenção, e RDBMS que eram necessárias anteriormente para lidar com o tráfego voltado para o cliente.
Como um sistema híbrido pode ser implementado
O DynamoDB pode utilizar os DynamoDB Streams e o AWS Lambda para se integrar perfeitamente a um ou mais sistemas de bancos de dados relacionais existentes:
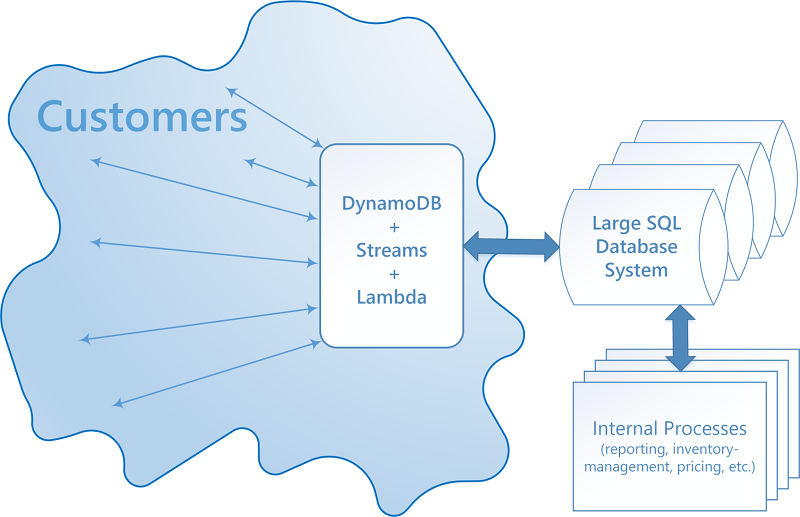
Um sistema que integra DynamoDB Streams e o AWS Lambda pode oferecer várias vantagens:
-
Ele pode funcionar como um cache persistente de visualizações materializadas.
-
Ele pode ser configurado para ser preenchido gradualmente com dados, à medida que esses dados forem consultados e modificados no sistema SQL. Isso significa que a visualização inteira não precisa ser pré-preenchida. Isso, por sua vez, significa que a capacidade de throughput provisionado é mais provável de ser usada de forma eficiente.
-
Ele tem baixos custos administrativos e é altamente disponível e confiável.
Para esse tipo de integração ser implementada, essencialmente três tipos de interoperação devem ser fornecidos.

-
Encher o cache do DynamoDB de modo incremental. Quando um item é consultado, procure-o primeiro no DynamoDB. Se ele não estiver lá, procure-o no sistema SQL e carregue-o no DynamoDB.
-
Gravar por meio de um cache do DynamoDB. Quando um cliente altera um valor no DynamoDB, uma função do Lambda é acionada para gravar o novo dado de volta no sistema SQL.
-
Atualize o DynamoDB do sistema SQL. Quando processos internos, como gerenciamento de inventário ou definição des preços, alteram um valor no sistema SQL, um procedimento armazenado é acionado para propagar a alteração para a visualização materializada do DynamoDB.
Essas operações são diretas, e nem todas são necessárias em todos os cenários.
Uma solução híbrida também pode ser útil quando você deseja confiar principalmente no DynamoDB, mas também deseja manter um pequeno sistema relacional para consultas únicas, ou para operações que necessitam de segurança especial ou que não são urgentes.
