Aproveitar índices esparsos
Para qualquer item em uma tabela, o DynamoDB grava uma entrada de índice correspondente somente se o valor da chave de classificação do índice está presente no item. Se a chave de classificação não aparecer em todos os itens da tabela ou se a chave de partição do índice não estiver presente no item, o índice será considerado esparso.
Os índices esparsos são úteis para consultas em uma subseção pequena de uma tabela. Por exemplo, suponha que você tem uma tabela que armazene todos os pedidos de clientes, com os seguintes atributos chaves:
-
Chave de partição:
CustomerId -
Chave de classificação:
OrderId
Para acompanhar os pedidos em aberto, você poderá inserir um atributo chamado isOpen aos itens de pedidos que ainda não foram enviados. Então, quando o pedido for enviado, você poderá excluir o atributo. Se você criar um índice em CustomerId (chave de partição) e em isOpen (chave de cada), somente os pedidos definidos com isOpen serão exibidos. Quando você tem milhares de pedidos e apenas um pequeno número deles está em aberto, é mais rápido e barato consultar o índice de pedidos em aberto do que analisar a tabela inteira.
Em vez de usar um tipo booleano atributo como isOpen, você poderia usar um atributo com um valor que resulta em um pedido de classificação útil no índice. Por exemplo, você pode usar um atributo OrderOpenDate definido como a data em que cada pedido foi feito e excluí-lo após o atendimento do pedido. Dessa forma, quando você consulta o índice esparso, os itens são retornados classificados de acordo com a data na qual cada pedido foi feito.
Exemplos de índices esparsos no DynamoDB
Os índices secundários globais são esparsos por padrão. Ao criar um índice secundário global, você especifica uma chave de partição e, opcionalmente, uma chave de classificação. Somente os itens na tabela base que contenham esses atributos aparecem no índice.
Ao projetar um índice secundário global como esparso, você pode provisioná-lo com um throughput de gravação menor do que a da tabela base, ainda obtendo um excelente desempenho.
Por exemplo, um aplicativo de jogos pode acompanhar todas as pontuações de cada usuário, mas geralmente só precisa consultar algumas pontuações altas. O seguinte design lida com esse cenário de modo eficiente:

Aqui, Rick jogou três jogos e obteve o status Champ em um deles. Padma jogou quatro jogos e obteve o status Champ em dois deles. Observe que o atributo Award está presente apenas nos itens em que o usuário obteve um award. O índice secundário global associado é semelhante ao seguinte:
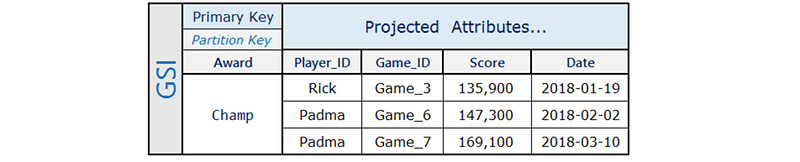
O índice secundário global contém apenas as pontuações altas que são consultadas com frequência e representadas por um pequeno subconjunto de itens na tabela base.
