Primeiras passos para a modelagem de dados relacionais no DynamoDB
Importante
O design do NoSQL exige uma visão diferente daquela no design do RDBMS. Para um RDBMS, você pode criar um modelo de dados normalizado sem pensar nos padrões de acesso. Você poderá estendê-lo posteriormente quando surgirem novas perguntas e requisitos de consulta. Por outro lado, no Amazon DynamoDB, você não deve iniciar o design do seu esquema até saber quais perguntas ele precisará responder. Compreender os problemas de negócios e os casos de uso de aplicativo antecipadamente é absolutamente essencial.
Para iniciar o design de uma tabela do DynamoDB que poderá ser escalada com eficiência, é necessário realizar várias etapas primeiro para identificar os padrões de acesso exigidos pelos sistemas de suporte operacional e administrativo (OSS/BSS) que o design precisa comportar:
Para novos aplicativos, analise as histórias dos usuários referentes a atividades e objetivos. Documente os vários casos de uso identificados e analise os padrões de acesso que eles exigem.
Para aplicativos existentes, analise os logs de consulta para saber como as pessoas estão usando o sistema atualmente e quais são os principais padrões de acesso.
Após concluir esse processo, você deve encerrar com uma lista que pode ser semelhante à seguinte:
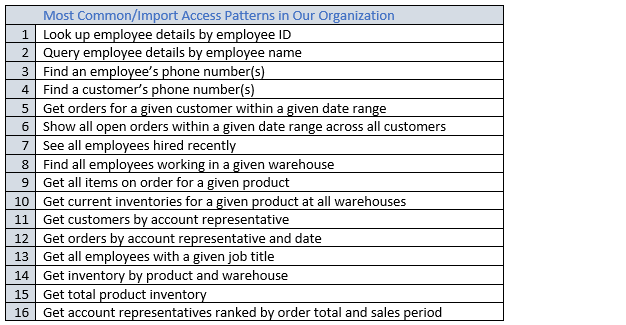
Em um aplicativo real, sua lista pode ser muito mais longa. Mas essa coleção representa a faixa de complexidade dos padrões de consulta que você pode encontrar em um ambiente de produção.
Uma abordagem comum ao design de esquemas do DynamoDB é identificar entidades da camada de aplicação e usar a desnormalização e a agregação de chaves compostas para reduzir a complexidade da consulta.
No DynamoDB, isso significa usar as chaves de classificação compostas, os índices secundários globais sobrecarregados, as tabelas/índices particionados e outros padrões de design. Você pode usar esses elementos para estruturar os dados, para que um aplicativo possa recuperar o que for necessário para um determinado padrão de acesso, usando uma única consulta em uma tabela ou um índice. O padrão principal que você pode usar para modelar o esquema normalizado, mostrado em Modelagem relacional, é o padrão da lista de adjacências. Outros padrões usados nesse design podem incluir a fragmentação de gravação do índice secundário global, a sobrecarga do índice secundário global, as chaves compostas e as agregações materializadas.
Importante
Em geral, você deve manter o mínimo de tabelas possível em uma aplicação do DynamoDB. As exceções incluem os casos que envolvem dados de séries temporais de alto volume ou conjuntos de dados que têm padrões muito diferentes de acesso. Uma única tabela com índices invertidos pode normalmente habilitar consultas simples para criar e recuperar estruturas de dados hierárquicas e complexas, exigidas pelo aplicativo.
Para usar o NoSQL Workbench para DynamoDB a fim de ajudar a visualizar o design da chave de partição, consulte Criar modelos de dados com o NoSQL Workbench.
