Práticas recomendadas para lidar com dados de séries temporais no DynamoDB
Os princípios gerais de design no Amazon DynamoDB recomendam manter o número mínimo de tabelas em uso. Para a maioria dos aplicativos, uma tabela única é tudo que você precisa. No entanto, no caso de dados de séries temporais, é possível lidar melhor com isso usando uma tabela por aplicativo por período.
Padrão de design para dados de séries temporais
Considere um cenário típico de séries temporais, em que você deseja monitorar um alto volume de eventos. O padrão de acesso de gravação é que todos os eventos sendo registrados tenham a data de hoje. O padrão de acesso de leitura pode ser: ler os eventos de hoje com mais frequência, os eventos de ontem com menos frequência e, então, os eventos mais antigos com muito menos frequência. Uma forma de lidar com isso é por meio da criação de data e hora atuais na chave primária.
O seguinte padrão de design normalmente lida com esse tipo de cenário de modo efetivo:
-
Crie uma tabela por período, provisionada com a capacidade de leitura e gravação necessária e os índices necessários.
-
Antes do final de cada período, crie previamente a tabela para o próximo período. Assim que o período atual terminar, direcione o tráfego de eventos para a nova tabela. É possível atribuir nomes a essas tabelas que especifiquem os períodos em que foram registradas.
-
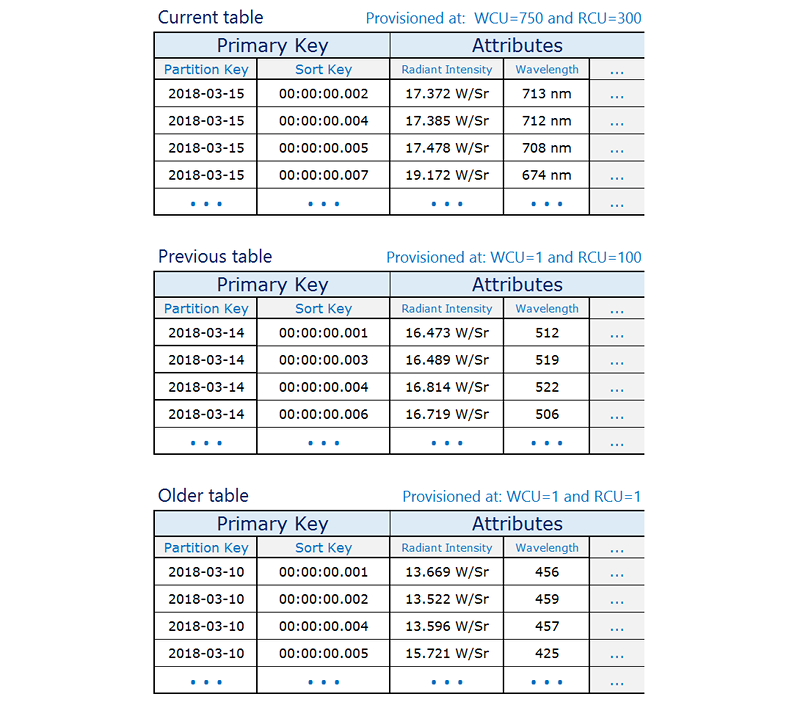
Quando uma tabela não estiver mais sendo gravada, reduza sua capacidade de gravação provisionada para um valor mais baixo (por exemplo, 1 WCU) e provisione a capacidade de leitura que for mais apropriada. Reduz a capacidade de leitura provisionada de tabelas anteriores conforme elas envelhecem. Você pode optar por arquivamento ou exclusão das tabelas cujo conteúdo raramente ou nunca é necessário.
A ideia é alocar os recursos necessários para o período atual que receberá o maior volume de tráfego e diminui o provisionamento para tabelas mais velhas que não são usadas ativamente, diminuindo assim os custos. Dependendo das necessidades de seus negócios, você pode considerar estilhaçar a gravação para distribuir o tráfego de forma uniforme para a chave de partição lógica. Para ter mais informações, consulte Usar a fragmentação de gravação para distribuir workloads uniformemente em uma tabela do DynamoDB.
Exemplos de tabelas de séries temporais
Veja a seguir um exemplo de dados de séries temporais no qual a tabela atual é provisionada com uma capacidade mais alta de leitura/gravação e as tabelas mais antigas são reduzidas porque não são acessadas com frequência: