As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Monitoramento com a Amazon CloudWatch
Você pode monitorar o Amazon DynamoDB CloudWatch usando, que coleta e processa dados brutos do DynamoDB em métricas legíveis e quase em tempo real. Essas estatísticas são mantidas por um período, para que você possa acessar informações históricas para obter uma perspectiva melhor sobre o desempenho de sua aplicação Web ou serviço. Por padrão, os dados métricos do DynamoDB são enviados automaticamente para. CloudWatch Para obter mais informações, consulte O que é a Amazon CloudWatch? e retenção de métricas no Guia do CloudWatch usuário da Amazon.
Tópicos
Como usar as métricas do DynamoDB?
As métricas relatadas pelo DynamoDB fornecem informações que você pode analisar de diferentes maneiras. A lista a seguir mostra alguns usos comuns para as métricas. Essas são sugestões para você começar, e não uma lista abrangente.
|
Como? |
Métricas relevantes |
|---|---|
How can I monitor the rate of TTL deletions on my
table?
|
Você pode monitorar |
How can I determine how much of my provisioned throughput is
being used?
|
Você pode monitorar |
How can I determine which requests exceed the provisioned
throughput quotas of a table?
|
|
How can I determine if any system errors occurred?
|
Você pode monitorar notaVocê pode encontrar erros de servidor internos enquanto trabalha com itens. Esses são esperados durante a vida útil de uma tabela. Todas as solicitações com falha podem ser repetidas imediatamente. |
Noções básicas sobre tempos de resposta do DynamoDB
Ao analisar a latência, geralmente é melhor verificar a média. Picos ocasionais na latência não são motivo de preocupação. No entanto, se a latência média for alta, poderá haver um problema estrutural.
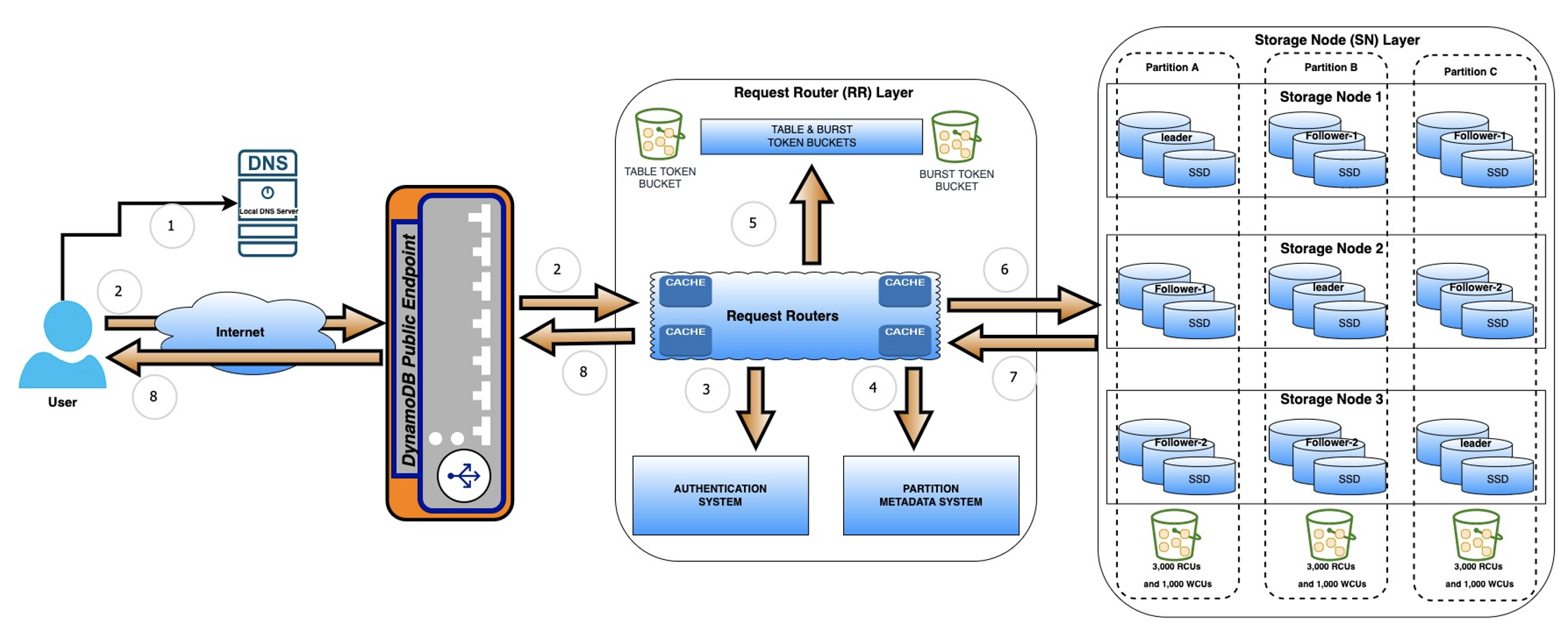
Há duas categorias de latência: latência da API e latência do serviço. A latência da API do DynamoDB é medida da etapa 1 à etapa 11 do processo abaixo. A latência do serviço é medida desde o momento em que uma API chega ao roteador de solicitação (etapa 4) até o momento em que o RR leva para enviar um resultado de volta ao usuário da aplicação (etapa 11). Você pode analisar a latência do lado do serviço com a CloudWatch métrica SuccessfulRequestLatency da Amazon.
Quando uma aplicação faz uma chamada da API do DynamoDB para o DynamoDB, como emitir uma operação GetItem para uma tabela do DynamoDB, as etapas a seguir ocorrem.
A aplicação resolve o endpoint público do DynamoDB usando o servidor DNS local.
A aplicação conecta-se ao endereço IP resolvido na primeira etapa e faz uma chamada de API.
O endpoint público do DynamoDB recebe a solicitação e a encaminha para um componente chamado roteador de solicitação (RR).
Quando a solicitação da API chega no roteador de solicitação (RR), ele faz a autenticação e a autorização da chamada da API. O RR também faz as verificações de controle de utilização nessa fase.
Depois de concluir todas as verificações, o roteador de solicitação (RR) cria o hash do valor da chave de partição que ele recebe da solicitação da API. Com base no valor do hash, o roteador de solicitação (RR) encontra os detalhes das informações da partição (nó de armazenamento).
Os nós de armazenamento representam os servidores nos quais os dados de tabela do cliente são armazenados. Uma única partição (não confundir com chave primária ou chave de partição) consiste em um conjunto de três nós de armazenamento. Desses três nós de armazenamento, um atua como líder para essa partição e os dois restantes atuam como seguidores.
Se a chamada de API for uma solicitação de gravação ou se for uma solicitação de leitura altamente consistente, os roteadores de solicitação (RR) localizarão o nó líder dessa partição e encaminharão a solicitação de API a esse nó específico. No caso de uma solicitação de leitura final consistente, os roteadores de solicitação (RR) encaminham aleatoriamente a solicitação ao nó líder ou a qualquer um dos nós seguidores dessa partição.
Em circunstâncias normais, o roteador de solicitação alcança o nó de armazenamento na primeira tentativa. Se essa tentativa falhar, o RR tentará várias vezes alcançar o nó de armazenamento novamente. Ao se conectar ao nó de armazenamento, o RR sempre espera tempo suficiente para a tentativa atual, depois tenta se conectar a outro SN. Essa é uma nova tentativa interna de microsserviço, e não uma nova tentativa configurável do SDK.
Nesse estágio, a solicitação da API chega à camada do nó de armazenamento (SN) e o SN começa a processá-la, lendo ou gravando os dados, dependendo da chamada de API.
Depois de processar com êxito a solicitação da API, o nó de armazenamento (SN) retorna os resultados ou o código de resposta ao RR que originou a solicitação.
Por fim, o roteador de solicitação encaminha os resultados à aplicação do cliente.
nota
Para a maioria das operações atômicas, como
GetItemePutItem, você pode esperar uma latência média de um dígito de milissegundo. A latência para operações não atômicas comoQueryeScandepende de muitos fatores, incluindo o tamanho do conjunto de resultados e a complexidade das condições e dos filtros da consulta.O DynamoDB não mede o tempo que uma aplicação leva para se conectar ao endpoint público do DynamoDB nem mede o tempo que uma aplicação leva para baixar os resultados do endpoint público.
