Omitir o nome do catálogo em consultas do metastore externo do Hive
Ao executar consultas DML e DDL em metastores externos do Hive, você pode simplificar a sintaxe da consulta omitindo o nome do catálogo se esse nome estiver selecionado no editor de consulta. Certas restrições se aplicam a essa funcionalidade.
Instruções DML
Como executar consultas com catálogos registrados
-
Você pode colocar o nome da origem dos dados antes do banco de dados usando a sintaxe
[[, como no exemplo a seguir.data_source_name].database_name].table_nameselect * from "hms-catalog-1".hms_tpch.customer limit 10; -
Quando a origem dos dados que você deseja usar já estiver selecionada no editor de consultas, você poderá omitir o nome da consulta, como no exemplo a seguir.
select * from hms_tpch.customer limit 10: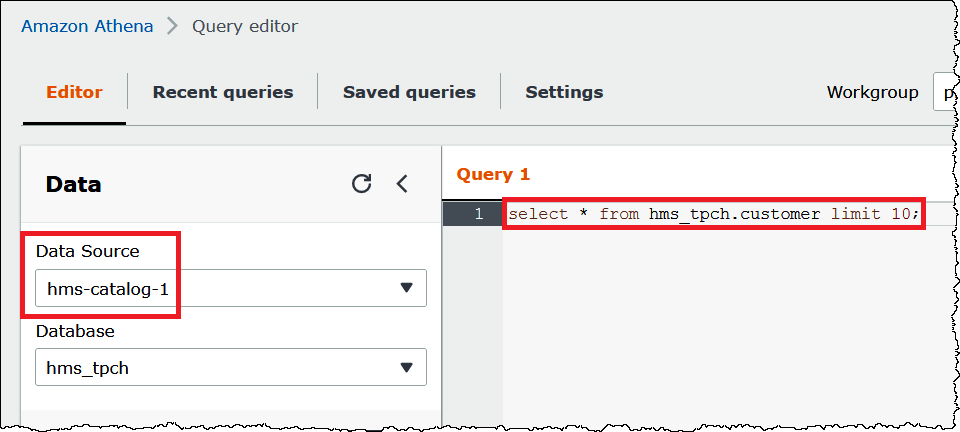
-
Quando você usa várias origens dos dados em uma consulta, pode omitir somente o nome da origem dos dados padrão e especificar o nome completo de qualquer origem dos dados não padrão.
Por exemplo, suponha que
AwsDataCatalogesteja selecionado como origem dos dados padrão no editor de consultas. A instruçãoFROMno trecho de consulta a seguir qualifica totalmente os nomes das duas primeiras origens dos dados, mas omite o nome da terceira porque ela está no catálogo de dados do AWS Glue.... FROM ehms01.hms_tpch.customer, "hms-catalog-1".hms_tpch.orders, hms_tpch.lineitem ...
Instruções DDL
As instruções DDL do Athena a seguir permitem prefixos de nome de catálogo. Prefixos de nome de catálogo em outras instruções DDL causam erros de sintaxe.
SHOW TABLES [IN [catalog_name.]database_name] ['regular_expression'] SHOW TBLPROPERTIES [[catalog_name.]database_name.]table_name [('property_name')] SHOW COLUMNS IN [[catalog_name.]database_name.]table_name SHOW PARTITIONS [[catalog_name.]database_name.]table_name SHOW CREATE TABLE [[catalog_name.][database_name.]table_name DESCRIBE [EXTENDED | FORMATTED] [[catalog_name.][database_name.]table_name [PARTITION partition_spec] [col_name ( [.field_name] | [.'$elem$'] | [.'$key$'] | [.'$value$'] )]
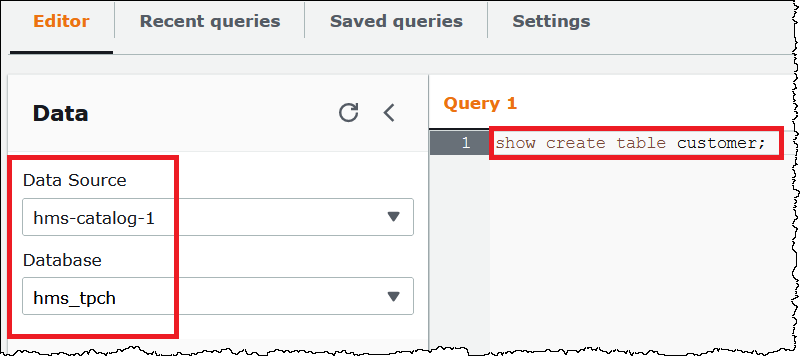
Assim como acontece com as instruções DML, você pode omitir a origem dos dados e os prefixos do banco de dados da consulta quando a origem dos dados e o banco de dados são selecionados no editor de consultas.
Na imagem a seguir, a origem dos dados hms-catalog-1 e o banco de dados hms_tpch são selecionados no editor de consultas. A instrução show
create table customer é bem-sucedida mesmo que o prefixo hms-catalog-1 e o nome do banco de dados hms_tpch sejam omitidos da consulta em si.
Especificar uma origem de dados padrão em uma string de conexão JDBC
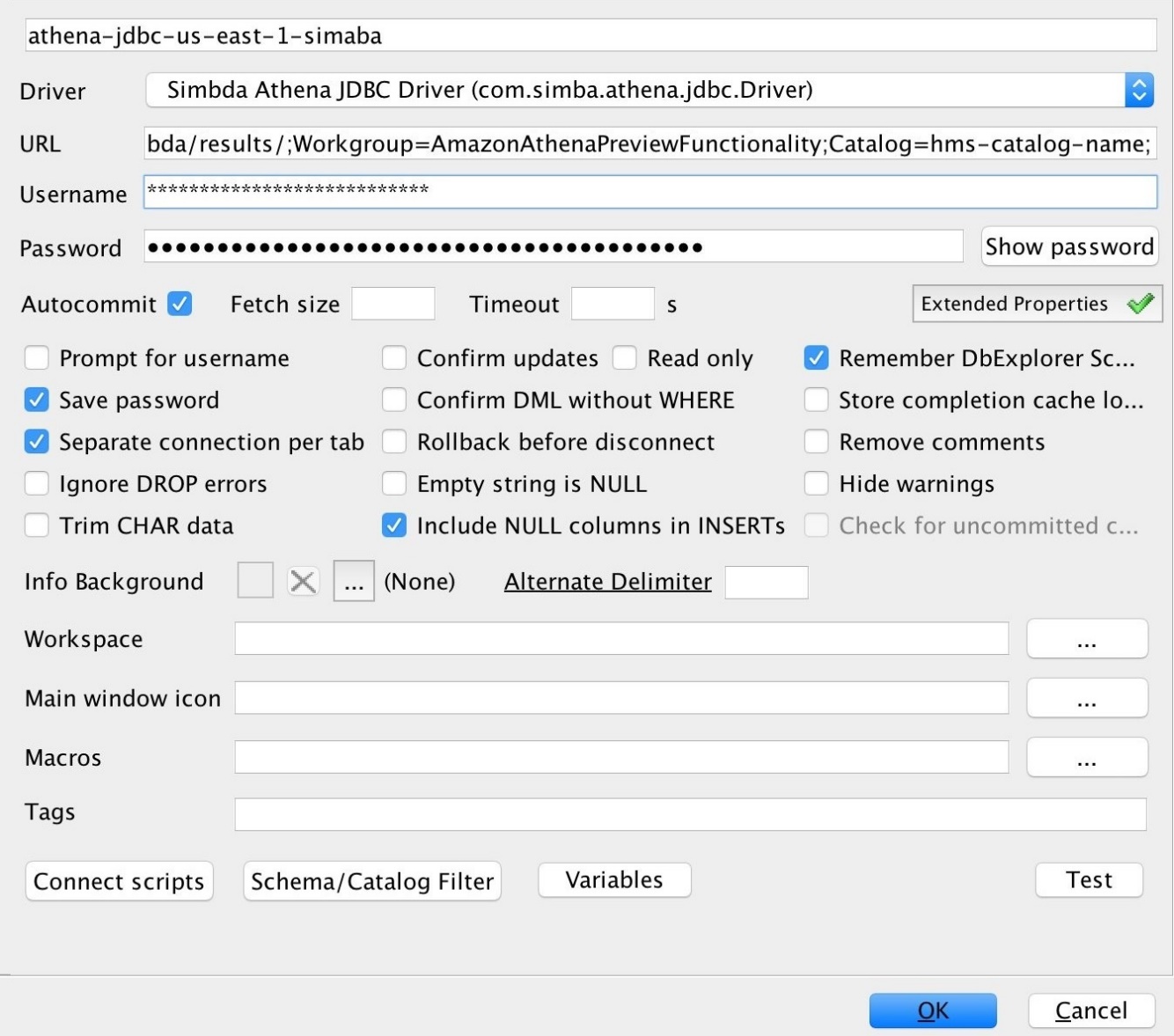
Ao usar o driver JDBC do Athena para conectar o Athena a um metastore externo do Hive, você pode usar o parâmetro Catalog para especificar o nome da origem de dados padrão na string de conexão em um editor SQL, como o SQL Workbench
nota
Para baixar os drivers JDBC do Athena mais recentes, consulte Usar o Athena com o driver JDBC.
A cadeia de conexão a seguir especifica a origem dos dados padrãohms-catalog-name.
jdbc:awsathena://AwsRegion=us-east-1;S3OutputLocation=s3://amzn-s3-demo-bucket/lambda/results/;Workgroup=AmazonAthenaPreviewFunctionality;Catalog=hms-catalog-name;
A imagem a seguir mostra um exemplo de URL de conexão JDBC como configurado no SQL Workbench.