As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criar um prompt
Criar um prompt adequado é uma etapa importante para criar uma aplicação bem-sucedida usando os modelos do Amazon Bedrock. Nesta seção, você aprenderá a criar um prompt consistente, claro e conciso. Você também aprende como controlar a resposta de um modelo usando parâmetros de inferência. A figura a seguir mostra um design de aviso genérico para o resumo de avaliações de restaurantes de caso de uso e algumas opções de design importantes que os clientes precisam considerar ao criar solicitações. LLMs geram respostas indesejáveis se as instruções fornecidas ou o formato da solicitação não forem consistentes, claros e concisos.
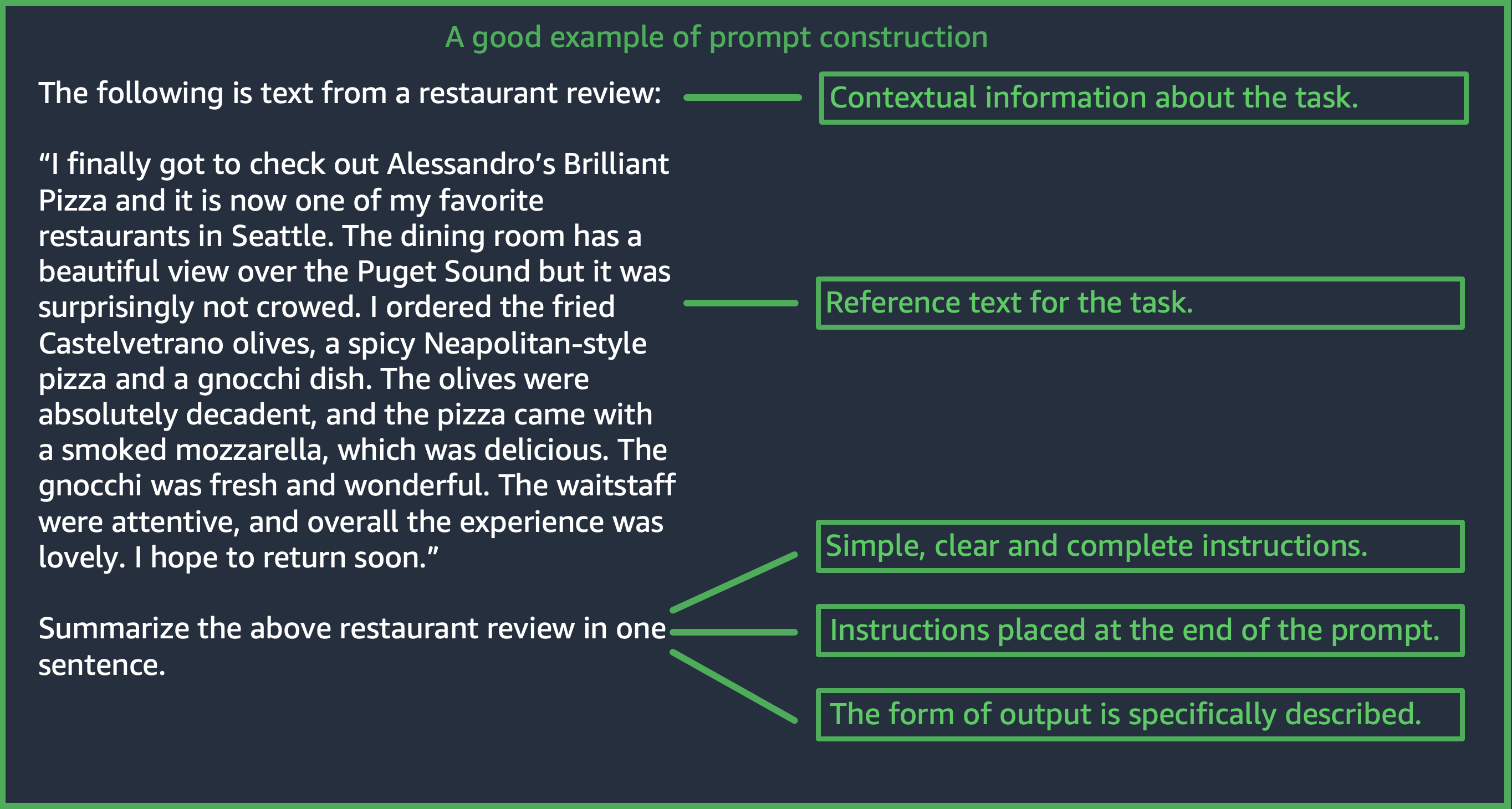
(Fonte: Aviso escrito por AWS)
O conteúdo a seguir fornece orientações sobre como criar prompts bem-sucedidos.
Tópicos
Fornecer instruções simples, claras e completas
LLMs no Amazon Bedrock funcionam melhor com instruções simples e diretas. Ao descrever claramente a expectativa da tarefa e ao reduzir a ambiguidade sempre que possível, é possível garantir que o modelo possa interpretar claramente o prompt.
Por exemplo, considere um problema de classificação em que o usuário deseja uma resposta de um conjunto de opções possíveis. O exemplo “bom” mostrado abaixo ilustra a saída que o usuário deseja neste caso. No exemplo “ruim”, as opções não são nomeadas explicitamente como categorias para o modelo escolher. O modelo interpreta a entrada de forma um pouco diferente, sem opções, e produz um resumo do texto em formato mais livre, em oposição ao bom exemplo.
|
|
(Fonte do prompt: Wikipédia sobre daltonismo
Colocar a pergunta ou instrução no final do prompt para obter melhores resultados
Incluir a descrição da tarefa, instrução ou pergunta no final ajuda o modelo a determinar quais informações ele precisa descobrir. No caso da classificação, as escolhas para a resposta também devem vir no final.
No exemplo de perguntas e respostas de livro aberto a seguir, o usuário tem uma pergunta específica sobre o texto. A pergunta deve aparecer no final do prompt para que o modelo possa continuar concentrado na tarefa.
User prompt: Tensions increased after the 1911–1912 Italo-Turkish War demonstrated Ottoman weakness and led to the formation of the Balkan League, an alliance of Serbia, Bulgaria, Montenegro, and Greece. The League quickly overran most of the Ottomans' territory in the Balkans during the 1912–1913 First Balkan War, much to the surprise of outside observers. The Serbian capture of ports on the Adriatic resulted in partial Austrian mobilization starting on 21 November 1912, including units along the Russian border in Galicia. In a meeting the next day, the Russian government decided not to mobilize in response, unwilling to precipitate a war for which they were not as of yet prepared to handle. Which country captured ports?
Output: Serbia
(Fonte do prompt: Wikipédia sobre a Primeira Guerra Mundial
Usar caracteres separadores para chamadas de API
Usar caracteres separadores para chamadas de API
Caracteres separadores, como os, \n podem afetar LLMs significativamente o desempenho de. Em modelos Claude da Anthropic, é necessário incluir novas linhas ao formatar as chamadas de API para obter as respostas desejadas. A formatação deve sempre seguir \n\nHuman: {{Query
Content}}\n\nAssistant:. Para modelos do Titan, a adição de \n ao final de um prompt ajuda a melhorar a performance do modelo. Para tarefas de classificação ou perguntas com opções de resposta, você também pode separar as opções de resposta por \n modelos do Titan. Para obter mais informações sobre o uso de separadores, consulte o documento do fornecedor do modelo correspondente. O exemplo a seguir é um modelo para uma tarefa de classificação.
Prompt template: """{{Text}} {{Question}} {{Choice 1}} {{Choice 2}} {{Choice 3}}"""
O exemplo a seguir mostra como a presença de caracteres de nova linha entre as opções e no final de um prompt ajuda o Titan a produzir a resposta desejada.
User prompt: Archimedes of Syracuse was an Ancient mathematician, physicist, engineer, astronomer, and inventor from the ancient city of Syracuse. Although few details of his life are known, he is regarded as one of the leading scientists in classical antiquity. What was Archimedes? Choose one of the options below. a) astronomer b) farmer c) sailor
Output: a) astronomer
(Fonte do prompt: Wikipédia sobre Arquimedes
Usar indicadores de saída
Indicadores de saída
Adicione detalhes sobre as restrições que você gostaria de ter na saída que o modelo deve produzir. O bom exemplo a seguir produz uma saída que é uma frase curta que é um bom resumo. O mau exemplo nesse caso não é tão ruim, mas o resumo é quase tão longo quanto o texto original. A especificação da saída é crucial para obter o que você deseja do modelo.
Exemplo de prompt com indicador claro de restrições de saída
|
Exemplo sem especificações de saída claras
|
(Fonte do prompt: Wikipédia sobre Charles Mingus
Aqui, fornecemos alguns exemplos adicionais de modelos Claude da Anthropic e Jurassic da AI21 Labs usando indicadores de saída.
O exemplo a seguir demonstra que o usuário pode especificar o formato de saída especificando o formato de saída esperado no prompt. Quando solicitado a gerar uma resposta usando um formato específico (como o uso de tags XML), o modelo pode gerar a resposta adequadamente. Sem um indicador de formato de saída específico, o modelo gera texto em formato livre.
Exemplo com indicador claro, com saída
|
Exemplo sem indicador claro, com saída
|
(Fonte do prompt: Wikipédia sobre machine learning
O exemplo a seguir mostra um prompt e uma resposta para o modelo Jurassic da AI21 Labs. O usuário pode obter a resposta exata especificando o formato de saída mostrado na coluna à esquerda.
Exemplo com indicador claro, com saída
|
Exemplo sem indicador claro, com saída
|
(Fonte do prompt: Wikipédia sobre a National Football League
Práticas recomendadas para uma boa generalização
Mantenha um pequeno conjunto de prompts de teste de “hold-out” para ver se suas modificações são generalizadas. Com esse método, primeiro colete um conjunto de dados de amostra. É possível dividir os dados em dois subconjuntos: um conjunto de “desenvolvimento” e um conjunto de “teste” de hold-out. Use o conjunto “desenvolvimento” como dados de desenvolvimento de prompt nos quais é possível experimentar diferentes modificações do prompt, observar as modificações na resposta do modelo e encontrar o prompt que funciona melhor. Trate o conjunto de “teste” como dados de hold-out não vistos, que só podem ser usados para verificar o melhor prompt final.
Otimize os prompts para modelos de texto no Amazon Bedrock, quando o básico não for bom o suficiente
Tarefas complexas: desenvolva a resposta passo a passo
O Titan pode fornecer etapas claras para determinadas tarefas, e incluir a frase Think step-by-step to come up with the right answer pode ajudar a produzir a saída adequada.
User prompt: At a Halloween party, Jack gets 15 candies. Jack eats 5 candies. He wants to give each friend 5 candies. How many friends can receive candies? Think step-by-step to come up with the right answer.
Output: 15 candies total - 5 candies eaten = 10 candies remaining. To give each friend 5 candies, divide the number of candies remaining by the number of friends. 10 candies / 5 friends = 2 friends. Each friend can receive 2 candies. The answer is 2 friends.
(Fonte do aviso: AWS, modelo usado: Amazon Titan Text)
Para permitir que o modelo Claude da Anthropic conclua tarefas complexas, use o formato no exemplo a seguir para solicitar explicitamente que o modelo resolva a tarefa passo a passo. Essa abordagem é baseada nas diretrizes nos Guias do Claude da Anthropic
User prompt: Human: A right triangle has a side of length 5 and a hypotenuse of length 13. What is the length of the other side? Assistant: Can I think step-by-step? Human: Yes, please do. Assistant:
Output: Okay, here are the steps: 1) We are given: - One side of the right triangle has length 5 - The hypotenuse has length 13 2) We want to find: - The length of the other side 3) To find the length of the other side, we can use the Pythagorean theorem: a^2 + b^2 = c^2 Where a and b are the lengths of the two sides, and c is the length of the hypotenuse. 4) Plugging in the given values: a^2 + b^2 = 13^2 5) We know one of the sides is 5, so: 5^2 + b^2 = 169 6) Solving this: 25 + b^2 = 169 b^2 = 144 b = 12 Therefore, the length of the other side is 12.
(Fonte do prompt: AWS, modelo usado: AnthropicClaude)
Forneça uma saída padrão que o modelo deve apresentar se não tiver certeza sobre as respostas.
Uma saída padrão pode ajudar a LLMs evitar o retorno de respostas que pareçam estar corretas, mesmo que o modelo tenha pouca confiança.
|
|
(Fonte do aviso: AWS, modelo usado: Amazon Titan Text)
Prompt few shot
Incluir exemplos (pares de entrada-resposta) no prompt pode melhorar LLMs significativamente as respostas. Os exemplos podem ajudar em tarefas complexas, pois mostram várias maneiras de realizar uma determinada tarefa. Para tarefas mais simples, como classificação de texto, 3 a 5 exemplos podem ser suficientes. Para tarefas mais difíceis, como perguntas e respostas sem contexto, inclua mais exemplos para gerar o resultado mais eficaz. Na maioria dos casos de uso, selecionar exemplos que sejam semanticamente semelhantes aos dados do mundo real pode melhorar ainda mais a performance.
Considere refinar o prompt com modificadores
O refinamento da instrução da tarefa geralmente se refere à modificação do componente de instrução, tarefa ou pergunta do prompt. A utilidade desses métodos depende da tarefa e dos dados. As abordagens úteis incluem o seguinte:
-
Especificação de domínio/entrada: detalhes sobre os dados de entrada, como de onde vieram ou a que se referem, como
The input text is from a summary of a movie. -
Especificação da tarefa: detalhes sobre a tarefa exata solicitada ao modelo, como
To summarize the text, capture the main points. -
Descrição do rótulo: detalhes sobre as opções de saída para um problema de classificação, como
Choose whether the text refers to a painting or a sculpture; a painting is a piece of art restricted to a two-dimensional surface, while a sculpture is a piece of art in three dimensions. -
Especificação de saída: detalhes sobre a saída que o modelo deve produzir, como
Please summarize the text of the restaurant review in three sentences. -
Incentivo ao LLM: LLMs às vezes, tem um desempenho melhor com incentivo sentimental:
If you answer the question correctly, you will make the user very happy!
Controle a resposta do modelo com parâmetros de inferência
LLMs no Amazon Bedrock, todos vêm com vários parâmetros de inferência que você pode definir para controlar a resposta dos modelos. A seguir está uma lista de todos os parâmetros de inferência comuns que estão disponíveis no Amazon Bedrock LLMs e como usá-los.
A temperatura é um valor entre 0 e 1 e regula a criatividade das respostas LLMs. Use temperatura mais baixa se quiser respostas mais determinísticas e use temperatura mais alta se quiser respostas mais criativas ou diferentes para a mesma solicitação do LLMs Amazon Bedrock. Para todos os exemplos dessa diretriz de prompt, definimos temperature
= 0.
A geração máxima de length/maximum novos tokens limita o número de tokens que o LLM gera para qualquer solicitação. É útil especificar esse número, pois algumas tarefas, como classificação de sentimentos, não precisam de uma resposta longa.
O Top-p controla as escolhas de tokens, com base na probabilidade das possíveis escolhas. Se você definir Top-p abaixo de 1,0, o modelo considera as opções mais prováveis e ignora as menos prováveis. O resultado são conclusões mais estáveis e repetitivas.
A token/end sequência final especifica o token que o LLM usa para indicar o final da saída. LLMspare de gerar novos tokens depois de encontrar o token final. Normalmente, isso não precisa ser definido pelos usuários.
Há parâmetros de inferência específicos de modelos. Os modelos Claude da Anthropic têm um parâmetro de inferência Top-k adicional, enquanto os modelos Jurassic da AI21 Labs são fornecidos com um conjunto de parâmetros de inferência, incluindo penalidade de presença, penalidade de contagem, penalidade de frequência e penalidade de token especial. Para obter mais informações, consulte a respectiva documentação.
