As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criação de um data lake do SDK do Amazon Chime
O data lake de análise de chamadas do SDK do Amazon Chime permite que você transmita os insights baseados em machine learning e todos os metadados do Amazon Kinesis Data Stream para o bucket do Amazon S3. Por exemplo, usando o data lake URLs para acessar as gravações. Para criar o data lake, você implanta um conjunto de AWS CloudFormation modelos do console do Amazon Chime SDK ou programaticamente usando o. AWS CLI O data lake permite que você consulte seus metadados de chamadas e dados de análise de voz fazendo referência às tabelas de dados do AWS Glue no Amazon Athena.
Tópicos
Pré-requisitos
Você deve ter os seguintes itens para criar um lake do SDK do Amazon Chime:
-
Um Amazon Kinesis data stream. Para obter mais informações, consulte Como criar um stream por meio do Console de Gerenciamento da AWS no Guia do desenvolvedor do Amazon Kinesis Streams.
-
Um bucket do S3. Para obter mais informações, consulte Criar seu primeiro bucket do Amazon S3 no Guia do usuário do Amazon S3.
Terminologia e conceitos de data lake
Use os termos e conceitos a seguir para entender como funciona o data lake.
- Amazon Kinesis Data Firehose
-
Um serviço de extração, transformação e carregamento (ETL) que captura, transforma e fornece dados de streaming de forma confiável para data lakes, data stores e serviços de análise. Para obter mais informações, consulte O que é o Amazon Kinesis Data Firehose?
- Amazon Athena
-
O Amazon Athena é um serviço de consulta interativa que permite analisar dados no Amazon S3 usando o SQL padrão. Como o Athena é uma tecnologia sem servidor, não há infraestrutura para ser gerenciada e você paga apenas pelas consultas que executar. Para usar o Athena, aponte para seus dados no Amazon S3, defina o esquema e use consultas SQL padrão. Você também pode usar grupos de trabalho para agrupar usuários e controlar os recursos aos quais eles têm acesso quando executam consultas. Os grupos de trabalho permitem gerenciar a simultaneidade de consultas e priorizar a execução de consultas em diferentes grupos de usuários e workloads.
- Glue Data Catalog
-
No Amazon Athena, as tabelas e os bancos de dados contêm os metadados que detalham um esquema para os dados de origem subjacente. Para cada conjunto de dados, é necessário existir uma tabela no Athena. Os metadados na tabela informam o Athena a localização do seu bucket do Amazon S3. Também especificam a estrutura de dados, como nomes de colunas, tipos de dados e o nome da tabela. Os bancos de dados contêm apenas os metadados e as informações do esquema de um conjunto de dados.
Criação de vários data lakes
Vários data lakes podem ser criados fornecendo um nome de banco de dados Glue exclusivo para especificar onde armazenar os insights de chamadas. Para uma determinada AWS conta, pode haver várias configurações de análise de chamadas, cada uma com um data lake correspondente. Isso significa que a separação de dados pode ser aplicada a determinados casos de uso sobre como os dados são armazenados, como a personalização da política de retenção e a política de acesso. Podem ser aplicadas diferentes políticas de segurança para acesso a insights, gravações e metadados.
Disponibilidade regional do data lake
O data lake do SDK do Amazon Chime está disponível nas regiões a seguir.
Region |
Tabela Glue |
QuickSight |
|---|---|---|
us-east-1 |
Available (Disponível) |
Available (Disponível) |
us-west-2 |
Available (Disponível) |
Available (Disponível) |
eu-central-1 |
Available (Disponível) |
Available (Disponível) |
Arquitetura de data lake
O diagrama a seguir mostra a arquitetura de data lake. Os números no desenho correspondem ao texto numerado abaixo.
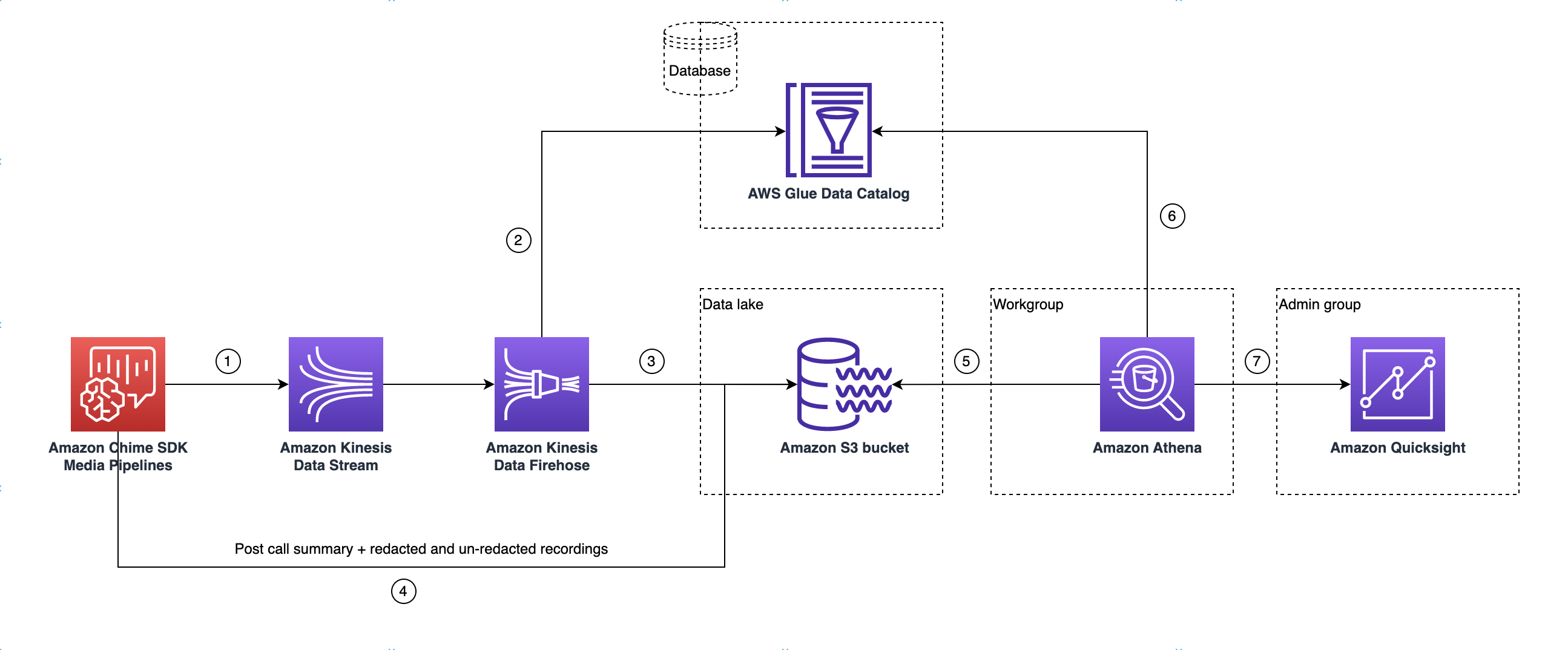
No diagrama, depois de usar o AWS console para implantar o CloudFormation modelo do fluxo de trabalho de configuração do pipeline de mídia Insights, os seguintes dados fluem para o bucket do Amazon S3:
-
A análise de chamadas do SDK do Amazon Chime começará a transmitir dados em tempo real para o fluxo de dados do Kinesis do cliente.
-
O Amazon Kinesis Firehose armazena esses dados em tempo real até que eles acumulem 128 MB, ou 60 segundos, o que ocorrer primeiro. Em seguida, o Firehose usa o
amazon_chime_sdk_call_analytics_firehose_schemano Glue Data Catalog para compactar os dados e transformar os registros JSON em um arquivo parquet. -
O arquivo parquet reside no bucket do Amazon S3, em um formato particionado.
-
Além dos dados em tempo real, os arquivos resumidos .wav do Amazon Transcribe Call Analytics pós-chamada (editados e não editados, se especificados na configuração) e os arquivos .wav de gravação de chamadas também são enviados para o bucket do Amazon S3.
-
É possível usar o Amazon Athena e o SQL padrão para consultar os dados no bucket do Amazon S3.
-
O CloudFormation modelo também cria um Glue Data Catalog para consultar esses dados resumidos pós-chamada por meio do Athena.
-
Todos os dados no bucket do Amazon S3 também podem ser visualizados usando. QuickSight QuickSight cria uma conexão com um bucket do Amazon S3 usando o Amazon Athena.
A tabela do Amazon Athena usa os seguintes atributos para otimizar o desempenho da consulta:
- Particionamento de dados
-
O particionamento divide a tabela em partes e mantém os dados relacionados juntos com base em valores de coluna, como data, país ou região. As partições funcionam como colunas virtuais. Nesse caso, o CloudFormation modelo define partições na criação da tabela, o que ajuda a reduzir a quantidade de dados digitalizados por consulta e melhora o desempenho. Também é possível filtrar por partição para restringir a quantidade de dados digitalizados por consulta. Para mais informações, consulte Particionamento de dados no Athena no Guia do usuário do Amazon Athena.
Este exemplo mostra a estrutura de particionamento com data de 1º de janeiro de 2023:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
em que
DETAIL_TYPEé dos itens a seguir:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- Otimizar a geração de armazenamento de dados colunares
-
O Apache Parquet usa compactação em colunas, compactação com base no tipo de dado e passagem de predicados para armazenar dados. Com melhores taxas de compactação ou ao ignorar blocos de dados significa ler menos bytes do bucket do Amazon S3. Isso leva a um melhor desempenho de consulta e a um menor custo. Para essa otimização, é ativada a conversão de dados de JSON para parquet no Amazon Kinesis Data Firehose.
- Projeção de partições
-
Esse atributo do Athena cria partições automaticamente para cada dia para melhorar o desempenho das consultas baseadas em datas.
Configuração de data lake
Use o console do SDK do Amazon Chime para realizar as etapas a seguir.
-
Inicie o console do Amazon Chime SDK ( https://console.aws.amazon.com/chime-sdk/home
) e, no painel de navegação, em Call Analytics, escolha Configurações. -
Concluída a etapa 1, escolha Avançar e, na página etapa 2, marque a caixa de seleção Análise de voz.
-
Em Detalhes da saída, marque a caixa de seleção Data warehouse para realizar análise histórica e, em seguida, escolha o link Implantar CloudFormation pilha.
O sistema envia você para a página de criação rápida da pilha no CloudFormation console.
-
Insira um nome para a pilha e, em seguida, insira os seguintes parâmetros:
-
DataLakeType— Escolha Criar análise de chamadas DataLake. -
KinesisDataStreamName: escolha seu stream. Deve ser o stream usado para streaming de análise de chamadas. -
S3BucketURI: escolha o bucket do Amazon S3. O URI deve ter o prefixos3://bucket-name -
GlueDatabaseName: escolha um nome exclusivo do banco de dados do AWS Glue. Você não pode reutilizar um banco de dados existente na conta da AWS .
-
-
Marque a caixa de seleção de confirmação e, em seguida, escolha Criar data lake. Aguarde 10 minutos para que o sistema crie o data lake.
Configuração do data lake usando AWS CLI
Use AWS CLI para criar uma função com permissões para a pilha CloudFormation de criação da chamada. Siga o procedimento abaixo para criar e configurar os perfis do IAM. Para obter mais informações, consulte Criação de uma pilha no Guia do AWS CloudFormation usuário.
-
Crie uma função chamada AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role e anexe uma política de confiança à função, permitindo que você assuma a função. CloudFormation
-
Crie uma política de confiança do IAM usando o modelo a seguir e salve o arquivo no formato .json.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
Execute o comando aws iam create-role e passe a política de confiança como parâmetro.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
Anote o ARN da função retornado na resposta. Será necessário um ARN de função na próxima etapa.
-
-
Crie uma política com permissão para criar uma CloudFormation pilha.
-
Crie uma política do IAM usando o modelo a seguir e salve o arquivo no formato .json. Esse arquivo será necessário para chamar create-policy.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
Execute aws iam create-policy e passe a política de criação de pilha como parâmetro.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
Anote o ARN da função retornado na resposta. Será necessário um ARN de função na próxima etapa.
-
-
Anexe a política do aws iam attach-role-policy à função.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
Crie uma CloudFormation pilha e insira os parâmetros necessários:aws cloudformation create-stack.
Forneça valores de parâmetros para cada ParameterKey uso ParameterValue.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
Recursos criados pela configuração do data lake
A tabela a seguir lista os recursos criados quando um data lake é criado.
Tipo de recurso |
Nomes e descrição do recurso |
Nome do serviço |
|---|---|---|
Banco de dados do Catálogo de Dados do AWS Glue |
GlueDatabaseName— Agrupa logicamente todas as tabelas do AWS Glue Data pertencentes a insights de chamadas e análises de voz. |
Análise de chamadas, análise de voz |
|
Tabelas do Catálogo de Dados do AWS Glue |
amazon_chime_sdk_call_analytics_firehose_schema: esquema combinado para análise de chamadas e análise de voz que é fornecido ao Kinesis Firehose. |
Análise de chamadas, análise de voz |
call_analytics_metadata: esquema para metadados de análise de chamadas. Contém SIPmetadata OneTimeMetadata e. |
Análise de chamadas |
|
| call_analytics_recording_metadata: esquema para metadados de gravação e aprimoramento de voz | Análise de chamadas, análise de voz | |
transcribe_call_analytics — Esquema para a carga “UtteranceEvent” TranscribeCallAnalytics |
Análise de chamadas |
|
transcribe_call_analytics_category_events — Esquema para a carga “CategoryEvent” TranscribeCallAnalytics |
Análise de chamadas |
|
transcribe_call_analytics_post_call: esquema para carga de resumo de análise de chamada de transcrição pós-chamada |
Análise de chamadas |
|
transcribe: esquema para carga de transcrição |
Análise de chamadas |
|
voice_analytics_status: esquema para eventos prontos para análise de voz |
Análise de voz |
|
speaker_search_status: esquema para correspondências de identificação |
Análise de voz |
|
voice_tone_analysis_status: esquema para eventos de análise de tom de voz |
Análise de voz |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics- — Kinesis |
Análise de chamadas, análise de voz |
Grupo de trabalho do Amazon Athena |
GlueDatabaseName- AmazonChime SDKData Análise — Grupo lógico de usuários para controlar os recursos aos quais eles têm acesso ao executar consultas. |
Análise de chamadas, análise de voz |
