As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Modelagem personalizada no AWS Clean Rooms ML
Do ponto de vista técnico, o diagrama a seguir descreve como a modelagem personalizada de ML funciona no AWS Clean Rooms ML.
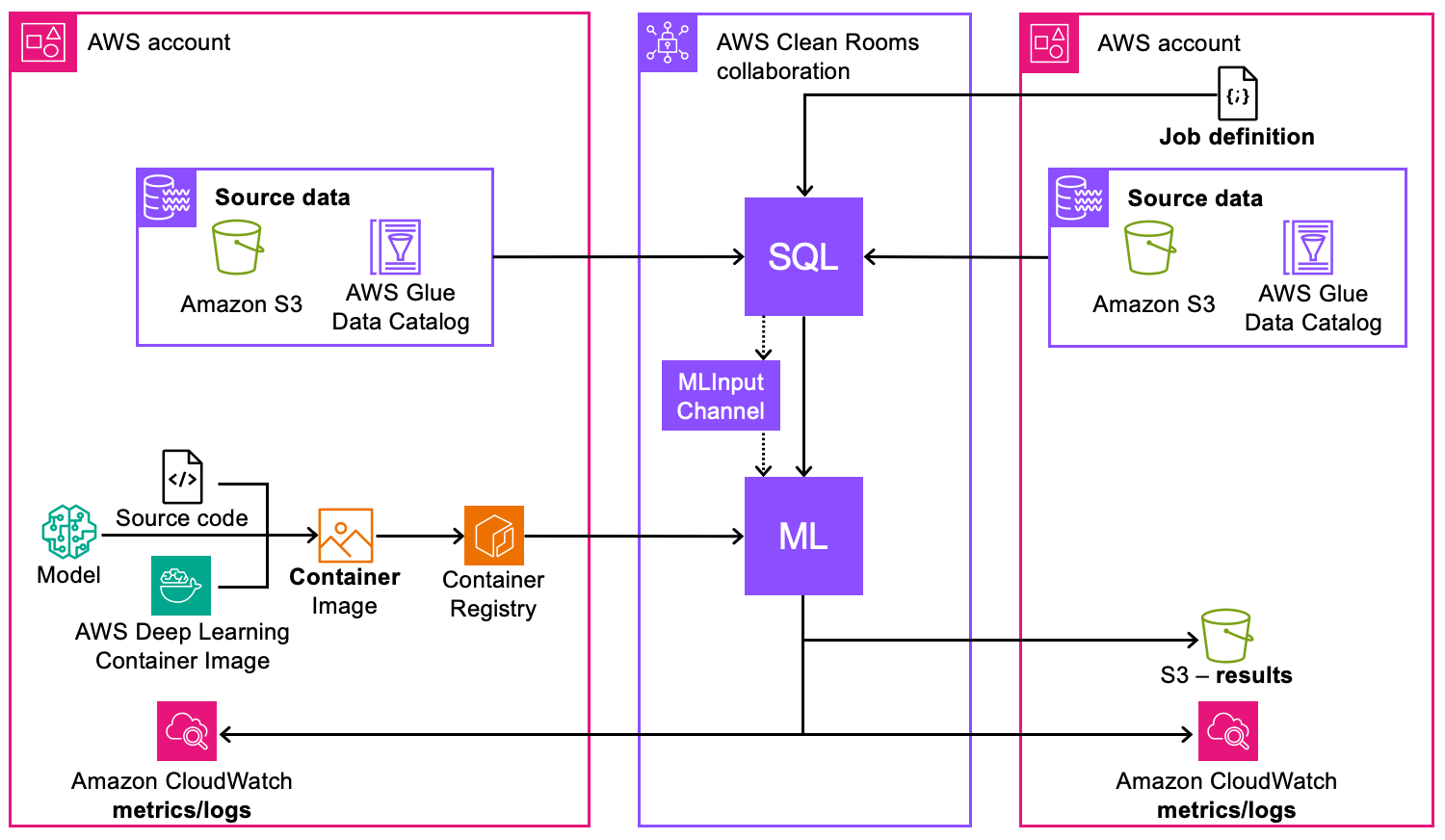
Veja como a modelagem personalizada de ML funciona no Clean Rooms ML:
-
Configuração da fonte de dados
-
Os dados de origem podem ser armazenados no catálogo do Amazon S3, no, ou no AWS Glue Data Catalog Snowflake
-
AWS Glue Data Catalog é usado para organizar e catalogar
-
Dados de vários Contas da AWS podem ser usados na mesma colaboração
-
-
Consulta SQL e processamento de dados
-
As consultas SQL são usadas para acessar e processar os dados de origem
-
As consultas são executadas dentro dos limites da AWS Clean Rooms colaboração
-
Os dados processados são alimentados nos canais de entrada de ML para treinamento de modelos
-
-
Desenvolvimento do modelo de ML
-
O código-fonte do modelo pode ser desenvolvido usando imagens de contêiner de aprendizado AWS profundo
-
Imagens de contêiner personalizadas devem ser criadas e armazenadas no Amazon Elastic Container Registry
-
-
Componentes de infraestrutura
-
O Amazon Elastic Container Registry armazena e gerencia os contêineres do modelo ML
-
O processamento de ML ocorre dentro do ambiente de AWS Clean Rooms colaboração seguro
-
-
Monitoramento e registro em log
-
A Amazon CloudWatch fornece métricas e registros para ambas as partes colaboradoras
-
O monitoramento está disponível para todos os Contas da AWS envolvidos na colaboração
-
As métricas de desempenho e os registros operacionais estão acessíveis às partes relevantes
-
-
Gestão de resultados
-
O acesso aos resultados é controlado de acordo com as permissões de colaboração
-
Antes de começar, consulte Pré-requisitos de modelagem de ML personalizada e Diretrizes de criação de modelos para o contêiner de treinamento para obter mais informações.
Tópicos
