AWS Data Pipeline não está mais disponível para novos clientes. Os clientes existentes do AWS Data Pipeline podem continuar usando o serviço normalmente. Saiba mais
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Iniciar um cluster usando a linha de comando
Se você executa regularmente um cluster do Amazon EMR para analisar logs da web ou realizar análises de dados científicos, você pode usá-lo AWS Data Pipeline para gerenciar seus clusters do Amazon EMR. Com AWS Data Pipeline, você pode especificar condições prévias que devem ser atendidas antes do lançamento do cluster (por exemplo, garantir que os dados de hoje sejam enviados para o Amazon S3). Este tutorial fornece o passo a passo para que você inicie um cluster que pode ser um modelo para um pipeline baseado em Amazon EMR simples ou como parte de um pipeline mais sofisticado.
Pré-requisitos
Antes de usar a CLI, é necessário executar as seguintes etapas:
-
Instale e configure a Interface da linha de comando (CLI). Para obter mais informações, consulte Acessando AWS Data Pipeline.
-
Certifique-se de que as funções do IAM tenham sido nomeadas DataPipelineDefaultRolee DataPipelineDefaultResourceRoleexistam. O AWS Data Pipeline console cria essas funções para você automaticamente. Se você não usou o AWS Data Pipeline console pelo menos uma vez, deverá criar essas funções manualmente. Para obter mais informações, consulte Funções do IAM para AWS Data Pipeline.
Tarefas
Criar o arquivo de definição de pipeline
O seguinte código é o arquivo de definição de pipeline para um cluster do Amazon EMR simples que é executado em um trabalho existente do Hadoop Streaming fornecido pelo Amazon EMR. Esse aplicativo de amostra é chamado WordCount e você também pode executá-lo usando o console do Amazon EMR.
Copie este código em um arquivo de texto e salve-o como MyEmrPipelineDefinition.json. Você deve substituir o local do bucket do Amazon S3 pelo nome de um bucket do Amazon S3 que você possui. Você também deve substituir as datas de início e término. Para iniciar clusters imediatamente, startDateTime defina uma data para um dia no passado e endDateTime para um dia no futuro. AWS Data Pipeline em seguida, começa a lançar os clusters “vencidos” imediatamente, na tentativa de resolver o que considera um acúmulo de trabalho. Esse preenchimento significa que você não precisa esperar uma hora para AWS Data Pipeline iniciar seu primeiro cluster.
{ "objects": [ { "id": "Hourly", "type": "Schedule", "startDateTime": "2012-11-19T07:48:00", "endDateTime": "2012-11-21T07:48:00", "period": "1 hours" }, { "id": "MyCluster", "type": "EmrCluster", "masterInstanceType": "m1.small", "schedule": { "ref": "Hourly" } }, { "id": "MyEmrActivity", "type": "EmrActivity", "schedule": { "ref": "Hourly" }, "runsOn": { "ref": "MyCluster" }, "step": "/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,s3n://elasticmapreduce/samples/wordcount/input,-output,s3://myawsbucket/wordcount/output/#{@scheduledStartTime},-mapper,s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate" } ] }
Este pipeline tem três objetos:
-
Hourly, que representa o agendamento do trabalho. Você pode definir uma programação como um dos campos em uma atividade. Quando você fizer isso, a atividade será executada de acordo com a programação, ou neste caso, de hora em hora. -
MyCluster, que representa o conjunto de EC2 instâncias da Amazon usadas para executar o cluster. Você pode especificar o tamanho e o número de EC2 instâncias a serem executadas como cluster. Se você não especificar o número de instâncias, o cluster será iniciado com duas, um nó principal e um nó de tarefa. Você pode especificar uma sub-rede para executar o cluster. Você pode acrescentar configurações adicionais ao cluster, como ações de bootstrap para carregar software adicional para a AMI fornecida pelo Amazon EMR. -
MyEmrActivity, que representa o cálculo para processar com o cluster. O Amazon EMR oferece suporte a vários tipos de clusters, incluindo o streaming, o Cascading e o Hive. OrunsOncampo se refere novamente a MyCluster, usando isso como especificação para os fundamentos do cluster.
Fazer upload e ativar a definição do pipeline
Você deve fazer o upload da definição do pipeline e ativá-lo. Nos comandos de exemplo a seguir, pipeline_name substitua por um rótulo para seu pipeline e pipeline_file pelo caminho totalmente qualificado para o arquivo de definição .json de pipeline.
AWS CLI
Para criar sua definição de pipeline e ativar seu pipeline, use o seguinte comando: create-pipeline. Observe a ID do seu pipeline, pois você usará esse valor com a maioria dos comandos da CLI.
aws datapipeline create-pipeline --name{ "pipelineId": "df-00627471SOVYZEXAMPLE" }pipeline_name--unique-idtoken
Para fazer o upload da definição do pipeline, use o put-pipeline-definitioncomando a seguir.
aws datapipeline put-pipeline-definition --pipeline-id df-00627471SOVYZEXAMPLE --pipeline-definition file://MyEmrPipelineDefinition.json
Se o pipeline for validado com êxito, o campo validationErrors estará vazio. Você deve revisar todos os avisos.
Para ativar o pipeline, use o seguinte comando: activate-pipeline.
aws datapipeline activate-pipeline --pipeline-id df-00627471SOVYZEXAMPLE
Você pode verificar se seu pipeline aparece na lista de pipeline usando o seguinte comando: list-pipelines.
aws datapipeline list-pipelines
Monitorar as execuções do pipeline
Você pode visualizar clusters lançados AWS Data Pipeline usando o console do Amazon EMR e pode visualizar a pasta de saída usando o console do Amazon S3.
Para verificar o progresso dos clusters lançados pelo AWS Data Pipeline
-
Abra o console do Amazon EMR.
-
Os clusters que foram gerados por AWS Data Pipeline têm um nome formatado da seguinte forma:
<pipeline-identifier><emr-cluster-name>_@ _.<launch-time>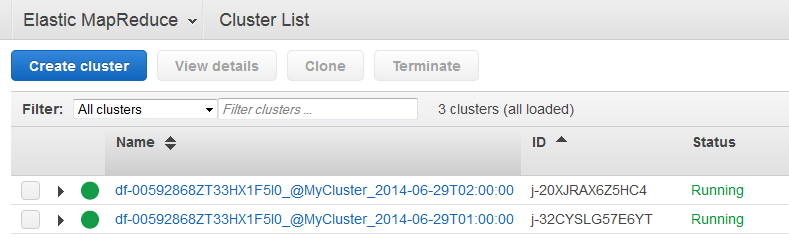
-
Depois que uma das execuções for concluída, abra o console do Amazon S3 e verifique se a data e hora da pasta de saída existe e contém os resultados esperados do cluster.