As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
JDBCgeração automática de esquemas
O Amazon DocumentDB é um banco de dados de documentos e, portanto, não tem o conceito de tabelas e esquemas. No entanto, ferramentas de BI, como o Tableau, esperam que o banco de dados conectado apresente um esquema. Especificamente, quando a conexão do JDBC driver precisar obter o esquema da coleção no banco de dados, ela pesquisará todas as coleções no banco de dados. O driver determinará se já existe uma versão em cache do esquema dessa coleção. Se uma versão em cache não existir, ela fará uma amostra da coleção para documentos e criará um esquema com base no comportamento a seguir.
Tópicos
Limitações de geração de esquemas
O JDBC driver DocumentDB impõe um limite no tamanho dos identificadores em 128 caracteres. O gerador de esquema pode truncar o comprimento dos identificadores gerados (nomes de tabelas e nomes de colunas) para garantir que eles se encaixem nesse limite.
Opções do método de verificação
O comportamento da amostragem pode ser modificado usando as opções de cadeia de conexão ou fonte de dados.
-
scanMethod= <option>
-
random - (padrão) - Os documentos de amostra são retornados em ordem aleatória.
-
idForward- Os documentos de amostra são devolvidos em ordem de identificação.
-
idReverse- Os documentos de amostra são devolvidos na ordem inversa da identificação.
-
tudo - Faça uma amostra de todos os documentos da coleção.
-
-
scanLimit= <n>- O número de documentos a serem amostrados. O valor deve ser um inteiro positivo. O valor padrão é 1000. Se scanMethodestiver definido como tudo, essa opção será ignorada.
Tipos de dados do Amazon DocumentDB
O servidor Amazon DocumentDB suporta vários tipos de dados do MongoDB. Listados abaixo estão os tipos de dados compatíveis e seus tipos de JDBC dados associados.
| Tipos de dados MongoDB | Compatível com o DocumentDB | JDBCTipo de dados |
|---|---|---|
| Dados binários | Sim | VARBINARY |
| Booleano | Sim | BOOLEAN |
| Double | Sim | DOUBLE |
| 32-bit Integer | Sim | INTEGER |
| 64-bit Integer | Sim | BIGINT |
| String | Sim | VARCHAR |
| ObjectId | Sim | VARCHAR |
| Data | Sim | TIMESTAMP |
| Null | Sim | VARCHAR |
| Expressão Regular | Sim | VARCHAR |
| Timestamp | Sim | VARCHAR |
| MinKey | Sim | VARCHAR |
| MaxKey | Sim | VARCHAR |
| Objeto | Sim | tabela virtual |
| Array | Sim | tabela virtual |
| Decimal128 | Não | DECIMAL |
| JavaScript | Não | VARCHAR |
| JavaScript (com escopo) | Não | VARCHAR |
| Não definido | Não | VARCHAR |
| Símbolo | Não | VARCHAR |
| DBPointer(4.0+) | Não | VARCHAR |
Mapeamento de campos de documentos escalares
Ao digitalizar uma amostra de documentos de uma coleção, o JDBC motorista criará um ou mais esquemas para representar as amostras na coleção. Em geral, um campo escalar no documento é mapeado para uma coluna no esquema da tabela. Por exemplo, em uma coleção chamada team e em um único documento{ "_id" : "112233", "name" :
"Alastair", "age": 25 }, isso seria mapeado para o esquema:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| equipe | id da equipe | VARCHAR | PK |
| equipe | name | VARCHAR | |
| equipe | idade | INTEGER |
Promoção de conflitos de tipos de dados
Ao digitalizar os documentos de amostra, é possível que os tipos de dados de um campo não sejam consistentes de documento para documento. Nesse caso, o JDBC driver promoverá o tipo de JDBC dados a um tipo de dados comum que se adequará a todos os tipos de dados dos documentos amostrados.
Por exemplo:
{ "_id" : "112233", "name" : "Alastair", "age" : 25 } { "_id" : "112244", "name" : "Benjamin", "age" : "32" }
O campo de idade é do tipo inteiro de 32 bits no primeiro documento, mas string no segundo documento. Aqui, o JDBC driver promoverá o tipo de JDBC dados VARCHAR para lidar com qualquer tipo de dados quando encontrado.
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| equipe | id da equipe | VARCHAR | PK |
| equipe | name | VARCHAR | |
| equipe | idade | VARCHAR |
Promoção de conflitos escalar-escalares
O diagrama a seguir mostra a maneira pela qual os conflitos de tipo de dados escalar-escalar são resolvidos.
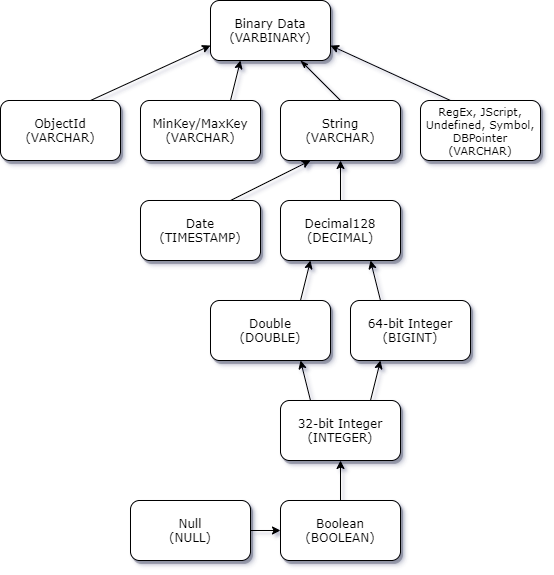
Promoção de conflitos do tipo complexo escalar
Assim como os conflitos do tipo escalar-escalar, o mesmo campo em documentos diferentes pode ter tipos de dados conflitantes entre complexos (matriz e objeto) e escalares (inteiro, booleano etc.). Todos esses conflitos são resolvidos (promovidos) VARCHAR para esses campos. Nesse caso, os dados da matriz e do objeto são retornados como JSON representação.
Matriz incorporada - Exemplo de conflito de campo de string:
{ "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] } { "_id":"112244", "name":"Joan Starr", "subscriptions":1 }
O exemplo acima mapeia o esquema da tabela customer2:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer2 | customer2 id | VARCHAR | PK |
| customer2 | name | VARCHAR | |
| customer2 | Assinatura | VARCHAR |
e a tabela virtual customer1_subscriptions:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer1_subscriptions | customer1 id | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | valor | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | região | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | Código | VARCHAR |
Manipulação de tipos de dados de objetos e matrizes
Até agora, descrevemos apenas como os tipos de dados escalares são mapeados. Os tipos de dados de objeto e matriz são (atualmente) mapeados para tabelas virtuais. O JDBC driver criará uma tabela virtual para representar campos de objetos ou matrizes em um documento. O nome da tabela virtual mapeada concatenará o nome da coleção original seguido pelo nome do campo separado pelo caractere sublinhado (“_”).
A chave primária da tabela base (“_id”) assume um novo nome na nova tabela virtual e é fornecida como uma chave externa para a tabela base associada.
Para campos do tipo matriz incorporada, as colunas de índice são geradas para representar o índice na matriz em cada nível da matriz.
Exemplo de campo de objeto incorporado
Para campos de objeto em um documento, um mapeamento para uma tabela virtual é criado pelo JDBC driver.
{ "Collection: customer", "_id":"112233", "name":"George Jackson", "address":{ "address1":"123 Avenue Way", "address2":"Apt. 5", "city":"Hollywood", "region":"California", "country":"USA", "code":"90210" } }
O exemplo acima mapeia o esquema da tabela de clientes:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer | customer id | VARCHAR | PK |
| customer | name | VARCHAR |
e a tabela virtual customer_address:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer_address | customer id | VARCHAR | PK/FK |
| customer_address | address1 | VARCHAR | |
| customer_address | address2 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | região | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | Código | VARCHAR |
Exemplo de campo de matriz incorporada
Para campos de matriz em um documento, um mapeamento para uma tabela virtual também é criado pelo JDBC driver.
{ "Collection: customer1", "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] }
O exemplo acima mapeia o esquema da tabela customer1:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer1 | customer1 id | VARCHAR | PK |
| customer1 | name | VARCHAR |
e a tabela virtual customer1_subscriptions:
| Nome da tabela | Nome da coluna | Tipo de dado | Chave |
|---|---|---|---|
| customer1_subscriptions | customer1 id | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | valor | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | região | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | Código | VARCHAR |
