As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Recuperação de desastres e clusters globais do Amazon DocumentDB
Tópicos
Ao usar um cluster global, você pode se recuperar rapidamente de desastres, como falhas na região. A recuperação de desastres é normalmente medida usando valores de RTO e RPO.
-
Objetivo de tempo de recuperação (RTO): tempo que um sistema leva para retornar a um estado de trabalho após um desastre. Em outras palavras, o RTO mede o tempo de inatividade. Para um cluster global, RTO em minutos.
-
Objetivo de ponto de recuperação (RPO): quantidade de dados que podem ser perdidos (medidos no tempo). Para um cluster global, o RPO é normalmente medido em segundos.
-
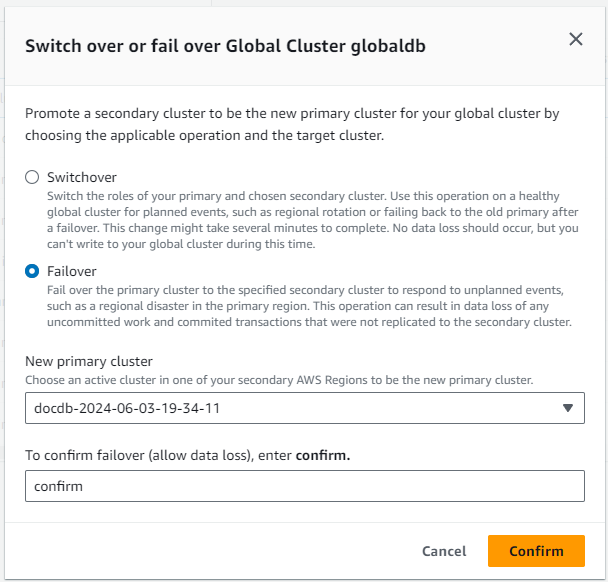
Para recuperar de uma paralisação não planejada, você pode executar um failover entre regiões para um dos secundários em seu cluster global. Quando o cluster global tem várias regiões secundárias, lembre-se de desanexar todas as regiões secundárias que quiser promover a primárias. Em seguida, promova uma dessas regiões secundárias para ser a nova Região da AWS primária. Por fim, crie novos clusters em cada uma das outras regiões secundárias e anexe esses clusters ao seu cluster global.
Realizar um failover gerenciado para um cluster global do Amazon DocumentDB
Essa abordagem destina-se à continuidade dos negócios no caso de um desastre regional real ou de uma interrupção completa do nível de serviço.
Durante um failover gerenciado, o cluster primário sofre failover para que você escolha a região secundária, enquanto a topologia de replicação existente do cluster global do Amazon DocumentDB é mantida. O cluster secundário escolhido promove um dos nós somente leitura ao status de gravador completo. Essa etapa permite que o cluster assuma a função de cluster primário. O banco de dados ficará indisponível por um curto período enquanto o cluster estiver assumindo a nova função. Os dados que não foram replicados do cluster primário antigo para o cluster secundário escolhido são perdidos quando esse secundário se torna o novo primário. O volume primário antigo faz o possível para tirar um snapshot antes de sincronizar com o novo primário, para que os dados não replicados sejam preservados no instantâneo.
nota
Você só pode realizar um failover gerenciado de cluster entre regiões em um cluster global do Amazon DocumentDB se os clusters primário e todos os secundários tiverem as mesmas versões de mecanismo. Se as versões do mecanismo forem incompatíveis, você poderá executar o failover manualmente seguindo as etapas em Realizar um failover manual para um cluster global do Amazon DocumentDB.
Se as versões do motor da região não corresponderem, o failover será bloqueado. Verifique se há atualizações pendentes e aplique-as para garantir que todas as versões do mecanismo da região correspondam e que o failover global do cluster seja desbloqueado. Para obter mais informações, consulte Desbloqueando a alternância ou o failover de um cluster global.
Para minimizar a perda de dados, recomendamos que você faça o seguinte antes de usar esse recurso:
Deixe as aplicações off-line para evitar que as gravações sejam enviadas para o cluster primário do cluster global do Amazon DocumentDB.
Verifique os tempos de atraso de todos os clusters secundários do Amazon DocumentDB. Escolher a região secundária com o menor atraso de replicação pode minimizar a perda de dados na atual região primária com falha. Verifique os tempos de atraso de todos os clusters secundários do Amazon DocumentDB no cluster global visualizando a métrica
GlobalClusterReplicationLagna Amazon. CloudWatch Essa métrica informa a que distância (em milissegundos) está a replicação de um cluster secundário em relação ao cluster primário.Para obter mais informações sobre CloudWatch métricas do Amazon DocumentDB, consulte. Métricas do Amazon DocumentDB
Durante um failover gerenciado, o cluster secundário escolhido é promovido à sua nova função como primário. No entanto, ele não herda as várias opções de configuração do cluster primário. Uma incompatibilidade na configuração pode levar a problemas de performance, incompatibilidades de workload e outros comportamentos anômalos. Para evitar esses problemas, recomendamos que você resolva as diferenças entre os clusters globais do Amazon DocumentDB para o seguinte:
Configurar um grupo de parâmetros do cluster do Amazon DocumentDB para o novo primário, se necessário: você pode configurar seus grupos de parâmetros de cluster do Amazon DocumentDB independentemente para cada cluster no cluster global do Amazon DocumentDB. Por isso, quando você promove um cluster secundário para assumir a função primária, o grupo de parâmetros do secundário pode ser configurado diferentemente do primário. Em caso afirmativo, modifique o grupo de parâmetros do cluster secundário promovido para estar em conformidade com as configurações do cluster principal. Para saber como, consulte Modificando grupos de parâmetros de cluster do Amazon DocumentDB.
Configure ferramentas e opções de monitoramento, como CloudWatch eventos e alarmes da Amazon — Configure o cluster promovido com a mesma capacidade de registro, alarmes e assim por diante, conforme necessário para o cluster global. Tal como acontece com os parameter groups, a configuração desses recursos não é herdada do primário no processo de failover. Algumas CloudWatch métricas, como atraso na replicação, só estão disponíveis para regiões secundárias. Assim, um failover altera a forma de visualizar essas métricas e definir alarmes para elas, e pode exigir alterações em qualquer painel predefinido. Para obter mais informações sobre clusters e monitoramento do Amazon DocumentDB, consulte Monitoramento do Amazon DocumentDB.
Normalmente, o cluster secundário escolhido assume a função principal em um minuto. Assim que o nó de gravação da nova região principal estiver disponível, você poderá conectar suas aplicações a ele e retomar suas workloads. Depois que o Amazon DocumentDB promove o novo cluster primário, ele reconstrói automaticamente todos os clusters adicionais da região secundária.
Como os clusters globais do Amazon DocumentDB usam replicação assíncrona, o atraso na replicação em cada região secundária pode variar. O Amazon DocumentDB reconstrói essas regiões secundárias para ter exatamente os mesmos point-in-time dados do novo cluster da região primária. A duração da tarefa de reconstrução completa pode levar de alguns minutos a várias horas, dependendo do tamanho do volume de armazenamento e da distância entre as regiões. Quando os clusters da região secundária terminam de ser reconstruídos com base na nova região primária, eles ficam disponíveis para acesso de leitura. Assim que o novo gravador principal for promovido e disponibilizado, o cluster da nova região primária poderá lidar com operações de leitura e gravação no cluster global do Amazon DocumentDB.
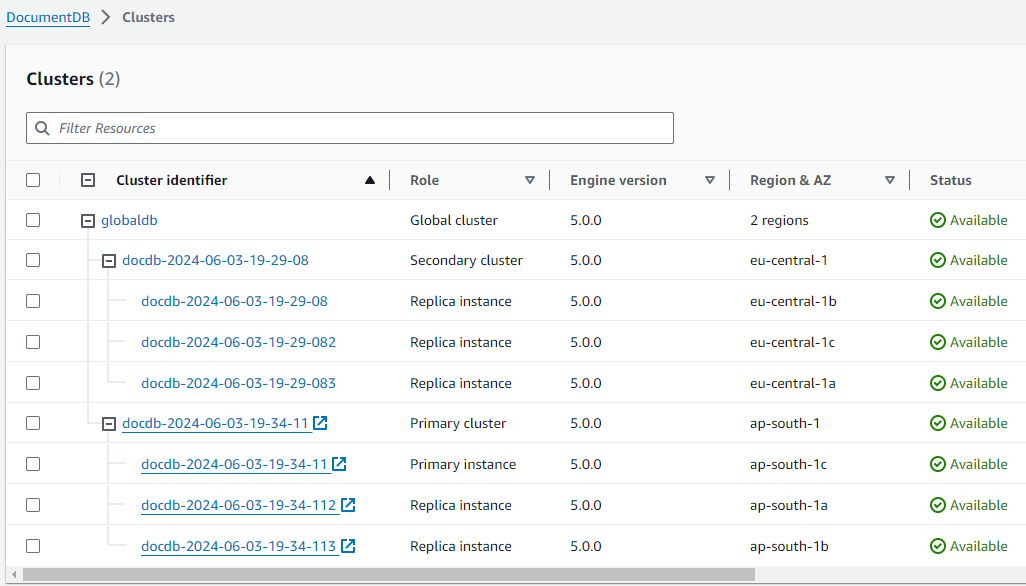
Para restaurar a topologia original do cluster global, o Amazon DocumentDB monitora a disponibilidade da antiga região primária. Assim que essa região estiver íntegra e disponível novamente, o Amazon DocumentDB a adicionará automaticamente ao cluster global como uma região secundária. Antes de criar o novo volume de armazenamento na antiga região primária, o Amazon DocumentDB tenta capturar um snapshot do volume de armazenamento antigo no ponto da falha. Ele faz isso para que você possa usá-lo para recuperar os dados perdidos. Se essa operação for bem-sucedida, o Amazon DocumentDB colocará esse snapshot chamado “rds: docdb-unplanned-global-failover - name-of-old-primary -db-cluster-timestamp” na seção de snapshot do. AWS Management Console Você também pode ver esse snapshot listado nas informações retornadas pela operação de API DescribeDBClusterSnapshots.
nota
O snapshot do volume de armazenamento antigo é um snapshot do sistema sujeito ao período de retenção de backup configurado no antigo cluster primário. Para preservar esse instantâneo fora do período de retenção, você pode copiá-lo para salvá-lo como um snapshot manual. Para saber mais sobre como copiar snapshots, incluindo os preços, consulte Cópia de um snapshot de cluster.
Depois que a topologia original for restaurada, você poderá fazer failback do clustert global para a região primária original executando uma operação de transição quando fizer mais sentido para seus negócios e sua workload. Para isso, siga as etapas em Como realizar uma transição para um cluster global do Amazon DocumentDB.
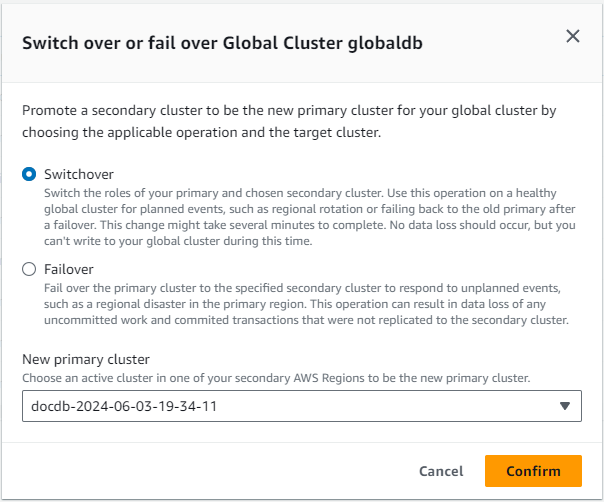
Você pode fazer o failover do seu cluster global do Amazon DocumentDB usando a AWS Management Console, a ou a AWS CLI API do Amazon DocumentDB.
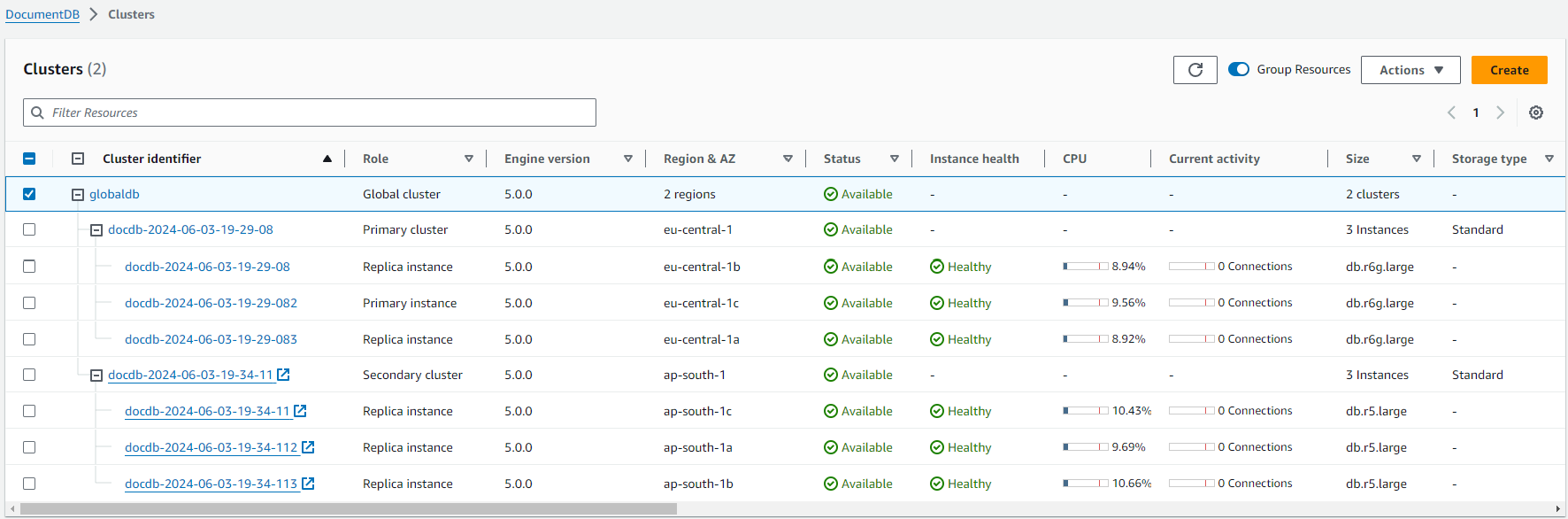
Realizar um failover manual para um cluster global do Amazon DocumentDB
Se um cluster inteiro em um Região da AWS ficar indisponível, você poderá promover outro cluster no cluster global para ter read/write capacidade.
Você pode ativar manualmente o mecanismo de failover do cluster global se um cluster em uma Região da AWS diferente seja uma opção melhor para ser o cluster primário. Por exemplo, você pode aumentar a capacidade de um dos clusters secundários e promovê-lo para ser o cluster primário. Ou o equilíbrio da atividade entre eles Regiões da AWS pode mudar, de modo que mudar o cluster primário para um diferente Região da AWS pode resultar em menor latência para as operações de gravação.
O procedimento a seguir descreve o que fazer para promover um dos clusters secundários em um cluster global do Amazon DocumentDB.
Como promover um cluster secundário:
-
Pare de emitir instruções DML e outras operações de gravação no cluster primário durante Região da AWS a interrupção.
-
Identifique um cluster de um secundário Região da AWS para usar como um novo cluster primário. Se você tiver dois (ou mais) secundários Regiões da AWS em seu cluster global, escolha o cluster secundário que tenha o menor tempo de espera.
-
Desanexe o cluster secundário escolhido do banco de dados global.
A remoção de um cluster secundário de um cluster global interrompe imediatamente a replicação do primário para esse secundário e o transforma em um cluster provisionado autônomo com recursos completos. read/write Qualquer outro cluster secundário associado ao cluster primário na região com a interrupção ainda estará disponível e poderá aceitar chamadas do seu aplicativo. Eles também consomem recursos. Como você está recriando o cluster global para evitar problemas de cérebro dividido, entre outros, remova os outros clusters secundários antes de criar o cluster global nas etapas a seguir.
Para obter as etapas detalhadas para desanexar, consulte Remover um cluster de um cluster global do Amazon DocumentDB.
-
Esse cluster se torna o cluster principal de um novo cluster global quando você começa a adicionar Regiões a ele, na próxima etapa.
-
Adicione um Região da AWS ao cluster. Quando você faz isso, o processo de replicação de primário para secundário começa.
-
Adicione mais Regiões da AWS conforme necessário para recriar a topologia necessária para dar suporte ao seu aplicativo. Certifique-se de que as gravações de aplicações sejam enviadas para o cluster correto antes, durante e depois de fazer alterações como essas, para evitar inconsistências de dados entre os clusters do cluster global (problemas de cérebro dividido).
-
Quando a interrupção for resolvida e você estiver pronto para reatribuir a Região da AWS original como o cluster primário, siga as mesmas etapas em sentido inverso:
-
Remova um dos clusters secundários do cluster global. Isso permitirá que ele atenda ao read/write tráfego.
-
Redirecione todo o tráfego de leitura para o cluster primário na Região da AWS original.
-
Adicione um Região da AWS para configurar um ou mais clusters secundários da Região da AWS mesma forma que antes.
Os clusters globais do Amazon DocumentDB podem ser gerenciados usando AWS SDKs, permitindo que você crie soluções para automatizar o processo global de failover de clusters para casos de uso de recuperação de desastres e planejamento de continuidade de negócios. Uma dessas soluções é disponibilizada para nossos clientes sob o licenciamento do Apache 2.0 e pode ser acessada em nosso repositório de ferramentas aqui
Como realizar uma transição para um cluster global do Amazon DocumentDB
Ao usar transições, é possível alterar a região do cluster primário rotineiramente. Essa abordagem destina-se a ambientes controlados, como manutenção operacional e outros procedimentos operacionais planejados.
Há três casos de uso comuns para o uso de transições.
Para requisitos de “alternância regional” impostos a setores específicos. Por exemplo, os regulamentos de serviços financeiros podem querer que os sistemas de nível 0 mudem para uma região diferente por vários meses a fim de garantir que os procedimentos de recuperação de desastres sejam executados regularmente.
Para aplicativos follow-the-sun "” multirregionais. Por exemplo, uma empresa pode querer fornecer gravações de menor latência em diferentes regiões com base no horário comercial em diferentes fusos horários.
Como um zero-data-loss método para retornar à região primária original após um failover.
nota
As transições foram projetadas para serem usadas em um cluster global íntegro do Amazon DocumentDB. Para se recuperar de uma interrupção não planejada, siga o procedimento apropriado em Realizar um failover manual para um cluster global do Amazon DocumentDB.
Para realizar uma transição, todas as regiões secundárias devem estar executando exatamente a mesma versão de mecanismo que a primária. Se as versões do motor da região não corresponderem, a transição será bloqueada. Verifique se há atualizações pendentes e aplique-as para garantir que todas as versões do mecanismo da região correspondam e que a alternância global de cluster seja desbloqueada. Para obter mais informações, consulte Desbloqueando a alternância ou o failover de um cluster global.
Durante uma transição, o Amazon DocumentDB muda o cluster primário para a região secundária escolhida e mantém a topologia de replicação existente do cluster global. Antes de iniciar o processo de transição, o Amazon DocumentDB espera que todos os clusters da região secundária estejam totalmente sincronizados com o cluster da região primária. Em seguida, o cluster de banco de dados na região primária torna-se somente leitura e o cluster secundário escolhido promove um dos respectivos nós somente leitura ao status de gravador completo. A promoção desse nó a um gravador permite que esse cluster secundário assuma a função de cluster primário. Como todos os clusters secundários foram sincronizados com o primário no início do processo, o novo primário continua as operações para o cluster global do Amazon DocumentDB sem perder dados. Seu banco de dados fica indisponível por um curto período enquanto os clusters primários e secundários selecionados estão assumindo suas novas funções.
Para otimizar a disponibilidade da aplicação, recomendamos que você faça o seguinte antes de usar esse recurso:
Execute essa operação em períodos de pouca demanda ou em outro momento quando as gravações no cluster primário forem mínimas.
Deixe as aplicações off-line para evitar que as gravações sejam enviadas para o cluster primário do cluster global do Amazon DocumentDB.
Verifique os tempos de atraso de todos os clusters secundários do Amazon DocumentDB no cluster global visualizando a métrica
GlobalClusterReplicationLagna Amazon. CloudWatch Essa métrica informa a que distância (em milissegundos) está a replicação de um cluster secundário em relação ao cluster primário. Esse valor é diretamente proporcional ao tempo que o Amazon DocumentDB levará para concluir a transição. Portanto, quanto maior o valor do atraso, mais tempo a transição levará.Para obter mais informações sobre CloudWatch métricas do Amazon DocumentDB, consulte. Métricas do Amazon DocumentDB
Durante uma transição, o cluster de banco de dados secundário escolhido é promovido à nova função como primário. No entanto, ele não herda as várias opções de configuração do cluster de banco de dados primário. Uma incompatibilidade na configuração pode levar a problemas de performance, incompatibilidades de workload e outros comportamentos anômalos. Para evitar esses problemas, recomendamos que você resolva as diferenças entre os clusters globais do Amazon DocumentDB para o seguinte:
Configurar um grupo de parâmetros do cluster do Amazon DocumentDB para o novo primário, se necessário: você pode configurar seus grupos de parâmetros de cluster do Amazon DocumentDB independentemente para cada cluster no cluster global do Amazon DocumentDB. Isso significa que quando você promove um cluster de banco de dados secundário para assumir a função primária, o parameter group do secundário pode ser configurado de forma diferente do que para o primário. Em caso afirmativo, modifique o parameter group do cluster de banco de dados secundário promovido para estar em conformidade com as configurações do cluster principal. Para saber como, consulte Gerenciando grupos de parâmetros de cluster do Amazon DocumentDB.
Configure ferramentas e opções de monitoramento, como Amazon CloudWatch Events e alarmes — Configure o cluster promovido com a mesma capacidade de registro, alarmes e assim por diante, conforme necessário para o cluster global. Tal como ocorre com os grupos de parâmetros, a configuração desses recursos não é herdada do primário no processo de transição. Algumas CloudWatch métricas, como atraso na replicação, só estão disponíveis para regiões primárias. Assim, uma transição altera a forma de visualizar essas métricas e definir alarmes para elas, e pode exigir alterações em qualquer painel predefinido. Para obter mais informações, consulte Monitoramento do Amazon DocumentDB.
nota
Normalmente, a transição de função pode levar alguns minutos.
Quando o processo de transição for concluído, o cluster de do Amazon DocumentDB promovido poderá lidar com operações de gravação para o cluster global.
Você pode alternar seu cluster global do Amazon DocumentDB usando o AWS Management Console ou o: AWS CLI
Desbloqueando a alternância ou o failover de um cluster global
As alternâncias e os failovers globais do cluster são bloqueados quando nem todos os clusters regionais no cluster global estão na mesma versão do mecanismo. Se as versões não corresponderem, você poderá ver esse erro em resposta ao chamar um switchover ou um failover: o cluster de banco de dados de destino especificado está executando uma versão de mecanismo com um nível de patch diferente do cluster de banco de dados de origem. Recomendamos aplicar rotineiramente as versões mais recentes do mecanismo para garantir que você esteja executando as atualizações mais recentes para manter seus clusters globais em bom estado.
Para resolver esse erro, atualize primeiro todas as regiões secundárias e depois a região primária para a mesma versão do mecanismo aplicando quaisquer itens de ação de manutenção pendentes. Para visualizar os itens de ação de manutenção pendentes e aplicar as alterações necessárias para corrigir o problema, execute as instruções em uma das seguintes guias:
