As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Eficiência do nó e da carga de trabalho
Ser eficiente com nossas cargas de trabalho e nós reduz complexity/cost ao mesmo tempo que aumenta o desempenho e a escala. Há muitos fatores a serem considerados ao planejar essa eficiência, e é mais fácil pensar em termos de compensações versus uma configuração de melhores práticas para cada recurso. Vamos explorar essas compensações em profundidade na seção a seguir.
Seleção de nós
Usar tamanhos de nós um pouco maiores (4-12xlarge) aumenta o espaço disponível que temos para executar pods, pois reduz a porcentagem do nó usado para “sobrecarga”, como DaemonSets
nota
Como o k8s é dimensionado horizontalmente como regra geral, para a maioria dos aplicativos, não faz sentido considerar o impacto no desempenho dos nós de tamanhos NUMA, daí a recomendação de uma faixa abaixo desse tamanho de nó.
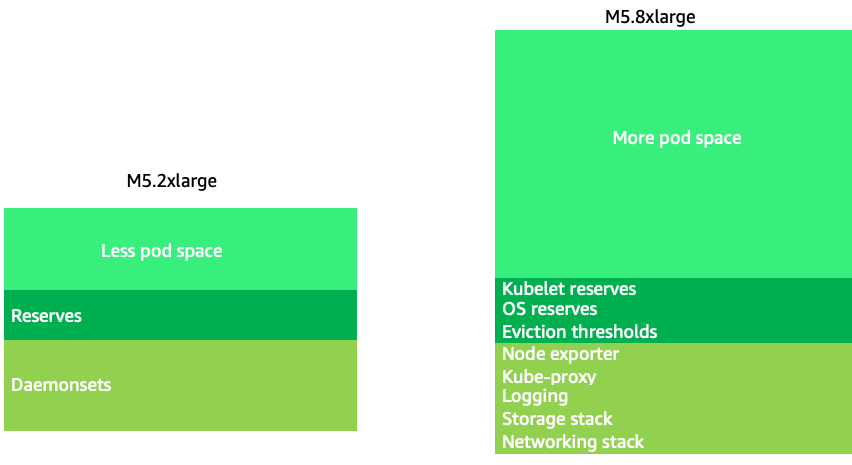
Tamanhos grandes de nós nos permitem ter uma porcentagem maior de espaço útil por nó. No entanto, esse modelo pode ser levado ao extremo ao empacotar o nó com tantos pods que causa erros ou satura o nó. O monitoramento da saturação dos nós é fundamental para o uso bem-sucedido de nós de tamanhos maiores.
A seleção de nós raramente é uma one-size-fits-all proposta. Geralmente, é melhor dividir as cargas de trabalho com taxas de rotatividade dramaticamente diferentes em grupos de nós diferentes. Cargas de trabalho em lotes pequenos com uma alta taxa de rotatividade seriam melhor atendidas pela família de instâncias de 4 vezes maior, enquanto um aplicativo de grande escala, como o Kafka, que usa 8 vCPUs e tem uma baixa taxa de rotatividade, seria melhor atendido pela família de 12 vezes maior.

nota
Outro fator a ser considerado com tamanhos de nós muito grandes é que os CGROUPS não ocultam o número total de vCPUs do aplicativo em contêineres. Os tempos de execução dinâmicos geralmente geram um número não intencional de threads de sistema operacional, criando uma latência difícil de solucionar. Para esses aplicativos, é recomendável fixar a CPU
Embalagem Node Bin
Regras do Kubernetes versus Linux
Há dois conjuntos de regras que precisamos considerar ao lidar com cargas de trabalho no Kubernetes. As regras do Kubernetes Scheduler, que usa o valor da solicitação para programar pods em um nó e, em seguida, o que acontece depois que o pod é agendado, que é o reino do Linux, não do Kubernetes.
Depois que o agendador do Kubernetes é concluído, um novo conjunto de regras assume o controle, o Linux Completely Fair Scheduler (CFS). A principal conclusão é que o Linux CFS não tem o conceito de núcleo. Discutiremos por que pensar em núcleos pode causar grandes problemas na otimização de cargas de trabalho para escalabilidade.
Pensando em núcleos
A confusão começa porque o programador do Kubernetes tem o conceito de núcleos. Do ponto de vista do programador do Kubernetes, se analisássemos um nó com 4 pods NGINX, cada um com uma solicitação de um conjunto principal, o nó ficaria assim.
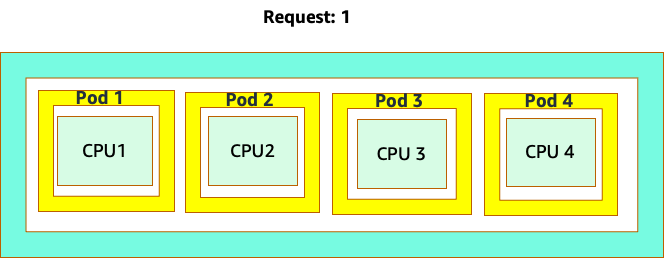
No entanto, vamos fazer um experimento mental sobre como isso parece diferente do ponto de vista do CFS do Linux. A coisa mais importante a lembrar ao usar o sistema Linux CFS é: contêineres ocupados (CGROUPS) são os únicos contêineres que contam para o sistema de compartilhamento. Nesse caso, somente o primeiro contêiner está ocupado, portanto, é permitido usar todos os 4 núcleos no nó.
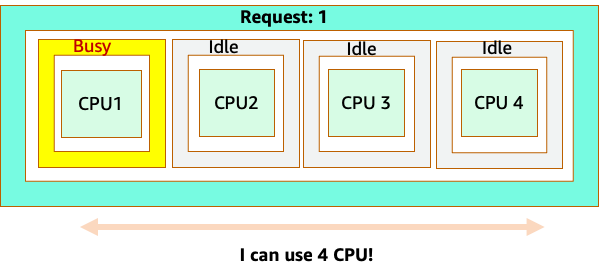
Por que isso importa? Digamos que executamos nosso teste de desempenho em um cluster de desenvolvimento em que um aplicativo NGINX era o único contêiner ocupado nesse nó. Quando movemos o aplicativo para produção, acontece o seguinte: o aplicativo NGINX quer 4 vCPUs de recursos, no entanto, como todos os outros pods no nó estão ocupados, o desempenho do nosso aplicativo é limitado.
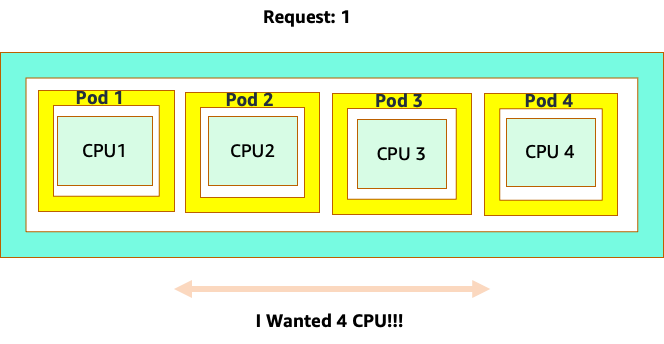
Essa situação nos levaria a adicionar mais contêineres desnecessariamente porque não estávamos permitindo que nossos aplicativos fossem escalados até seu “``ponto ideal"`. Vamos explorar esse importante conceito de a com "sweet spot" um pouco mais de detalhes.
Dimensionamento correto da aplicação
Cada aplicativo tem um certo ponto em que não pode receber mais tráfego. Ir acima desse ponto pode aumentar os tempos de processamento e até mesmo reduzir o tráfego quando ultrapassado esse ponto. Isso é conhecido como ponto de saturação do aplicativo. Para evitar problemas de escalabilidade, devemos tentar escalar o aplicativo antes que ele atinja seu ponto de saturação. Vamos chamar esse ponto de ponto ideal.

Precisamos testar cada um de nossos aplicativos para entender seu ponto ideal. Não haverá orientação universal aqui, pois cada aplicativo é diferente. Durante esse teste, estamos tentando entender a melhor métrica que mostra o ponto de saturação de nossos aplicativos. Muitas vezes, as métricas de utilização são usadas para indicar que um aplicativo está saturado, mas isso pode levar rapidamente a problemas de escalabilidade (exploraremos esse tópico em detalhes em uma seção posterior). Quando tivermos esse “`ponto ideal"`, podemos usá-lo para escalar com eficiência nossas cargas de trabalho.
Por outro lado, o que aconteceria se aumentássemos a escala bem antes do ponto ideal e criássemos frutos desnecessários? Vamos explorar isso na próxima seção.
Expansão de cápsulas
Para ver como a criação de cápsulas desnecessárias pode sair do controle rapidamente, vejamos o primeiro exemplo à esquerda. A escala vertical correta desse contêiner ocupa cerca de dois v CPUs de utilização ao lidar com 100 solicitações por segundo. No entanto, se subprovisionássemos o valor das solicitações definindo as solicitações para meio núcleo, agora precisaríamos de 4 pods para cada um dos pods realmente necessários. Para agravar ainda mais esse problema, se nosso HPA

Aumentando esse problema, podemos ver rapidamente como isso pode sair do controle. Uma implantação de dez pods cujo ponto ideal foi definido incorretamente poderia rapidamente chegar a 80 pods e a infraestrutura adicional necessária para operá-los.
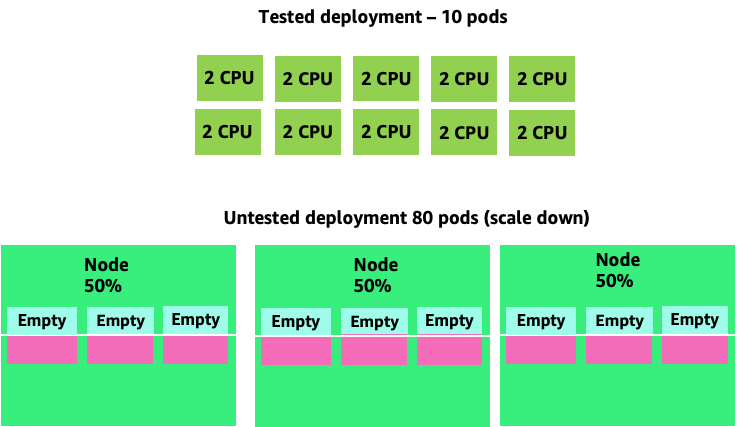
Agora que entendemos o impacto de não permitir que os aplicativos operem em seu ponto ideal, vamos voltar ao nível do nó e perguntar por que essa diferença entre o programador do Kubernetes e o CFS do Linux é tão importante?
Ao aumentar e diminuir a escala com o HPA, podemos ter um cenário em que temos muito espaço para alocar mais pods. Essa seria uma decisão ruim porque o nó representado à esquerda já está com 100% de utilização da CPU. Em um cenário irreal, mas teoricamente possível, poderíamos ter o outro extremo em que nosso nó está completamente cheio, mas nossa utilização de CPU é zero.
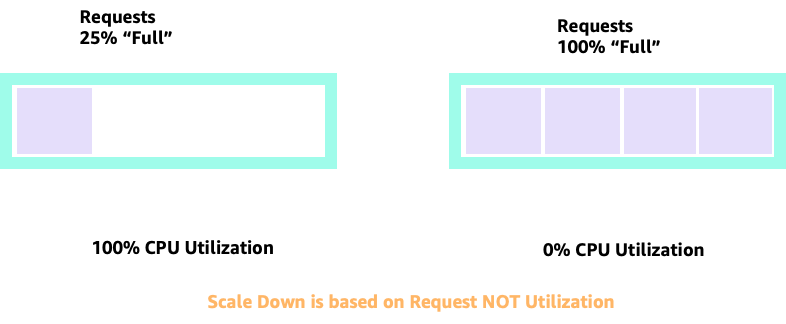
Solicitações de configuração
Seria tentador definir a solicitação no valor “ideal” desse aplicativo, mas isso causaria ineficiências, conforme ilustrado no diagrama abaixo. Aqui, definimos o valor da solicitação como 2 vCPUs, no entanto, a utilização média desses pods executa apenas 1 CPU na maioria das vezes. Essa configuração faria com que desperdiçássemos 50% de nossos ciclos de CPU, o que seria inaceitável.
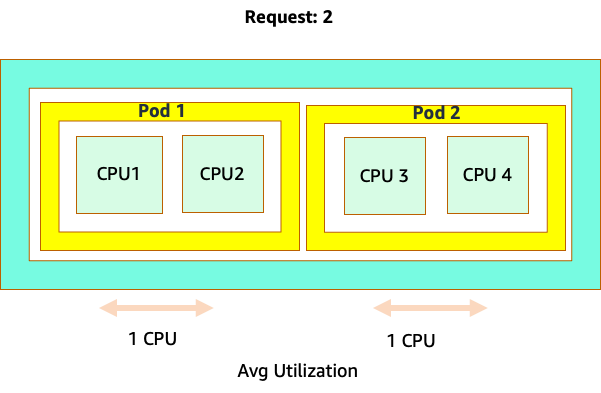
Isso nos leva à resposta complexa para o problema. A utilização do contêiner não pode ser considerada isoladamente; é preciso levar em consideração os outros aplicativos em execução no nó. No exemplo a seguir, contêineres que são intermitentes por natureza são misturados com dois contêineres de baixa utilização da CPU que podem ter restrições de memória. Dessa forma, permitimos que os contêineres atinjam seu ponto ideal sem sobrecarregar o nó.
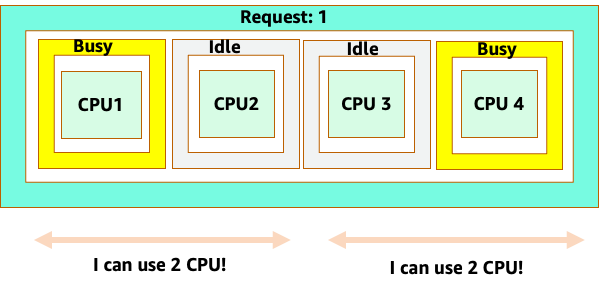
O conceito importante a ser extraído de tudo isso é que usar o conceito de núcleos do programador Kubernetes para entender o desempenho do contêiner Linux pode levar a uma tomada de decisão inadequada, pois eles não estão relacionados.
nota
O Linux CFS tem seus pontos fortes. Isso é especialmente verdadeiro para cargas de trabalho I/O baseadas. No entanto, se seu aplicativo usa núcleos completos sem cartões auxiliares e não tem I/O requisitos, a fixação da CPU pode remover uma grande complexidade desse processo e é incentivada com essas ressalvas.
Utilização versus saturação
Um erro comum no escalonamento de aplicativos é usar apenas a utilização da CPU para sua métrica de escalabilidade. Em aplicativos complexos, isso quase sempre é um indicador fraco de que um aplicativo está realmente saturado de solicitações. No exemplo à esquerda, vemos que todas as nossas solicitações estão realmente chegando ao servidor web, então a utilização da CPU está acompanhando bem a saturação.
Em aplicativos do mundo real, é provável que algumas dessas solicitações sejam atendidas por uma camada de banco de dados ou de autenticação, etc. Nesse caso mais comum, observe que a CPU não está rastreando com saturação, pois a solicitação está sendo atendida por outras entidades. Nesse caso, a CPU é um indicador muito ruim de saturação.
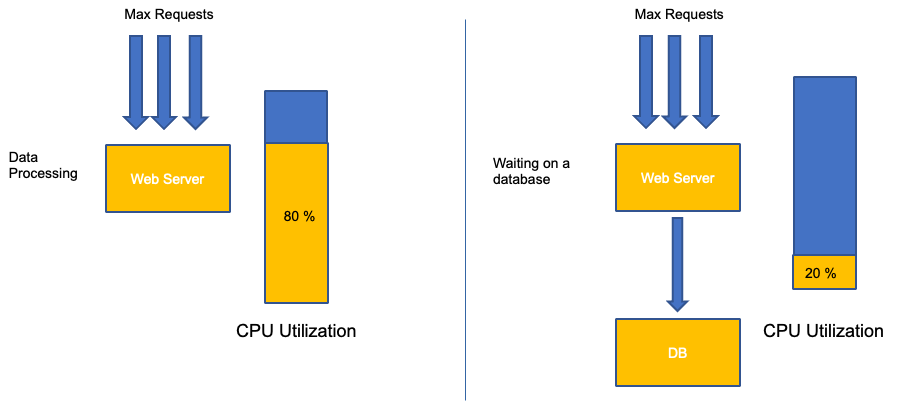
Usar a métrica errada no desempenho do aplicativo é o principal motivo para o escalonamento desnecessário e imprevisível no Kubernetes. É preciso ter muito cuidado ao escolher a métrica de saturação correta para o tipo de aplicativo que você está usando. É importante observar que não existe uma recomendação única que possa ser dada. Dependendo da linguagem usada e do tipo de aplicativo em questão, há um conjunto diversificado de métricas de saturação.
Podemos pensar que esse problema ocorre apenas com a utilização da CPU, no entanto, outras métricas comuns, como solicitação por segundo, também podem se enquadrar exatamente no mesmo problema discutido acima. Observe que a solicitação também pode ir para camadas de banco de dados, camadas de autenticação, não sendo atendida diretamente pelo nosso servidor web, portanto, é uma métrica ruim para a verdadeira saturação do próprio servidor web.
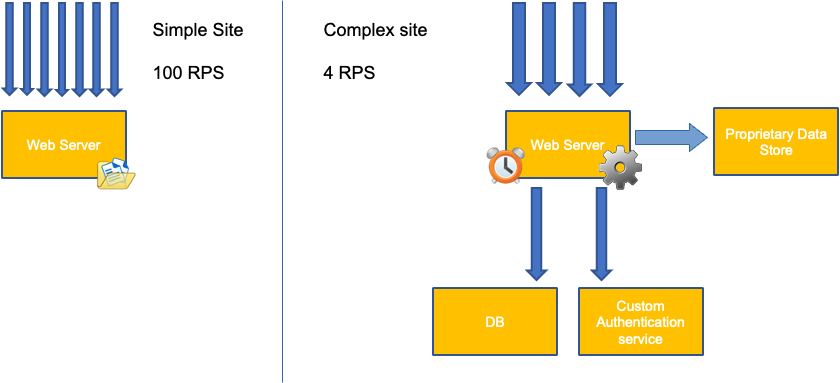
Infelizmente, não há respostas fáceis quando se trata de escolher a métrica de saturação correta. Aqui estão algumas diretrizes a serem levadas em consideração:
-
Entenda o tempo de execução da sua linguagem - linguagens com vários encadeamentos de sistema operacional reagirão de forma diferente dos aplicativos de um único encadeamento, afetando o nó de forma diferente.
-
Entenda a escala vertical correta: quanto buffer você quer na escala vertical de seus aplicativos antes de escalar um novo pod?
-
Quais métricas realmente refletem a saturação do seu aplicativo - A métrica de saturação para um produtor Kafka seria bem diferente de um aplicativo web complexo.
-
Como todos os outros aplicativos no nó afetam uns aos outros? O desempenho do aplicativo não é feito no vácuo; as outras cargas de trabalho no nó têm um grande impacto.
Para encerrar esta seção, seria fácil descartar o que foi dito acima como excessivamente complexo e desnecessário. Muitas vezes, podemos estar enfrentando um problema, mas não temos conhecimento da verdadeira natureza do problema porque estamos analisando as métricas erradas. Na próxima seção, veremos como isso pode acontecer.
Saturação do nó
Agora que exploramos a saturação de aplicativos, vamos analisar esse mesmo conceito do ponto de vista de um nó. Vamos pegar dois CPUs que são 100% utilizados para ver a diferença entre utilização e saturação.
A vCPU à esquerda é 100% utilizada, no entanto, nenhuma outra tarefa está esperando para ser executada nessa vCPU, portanto, em um sentido puramente teórico, isso é bastante eficiente. Enquanto isso, temos 20 aplicativos de thread único aguardando para serem processados por uma vCPU no segundo exemplo. Agora, todos os 20 aplicativos experimentarão algum tipo de latência enquanto aguardam sua vez de serem processados pela vCPU. Em outras palavras, a vCPU à direita está saturada.
Não só não veríamos esse problema se estivéssemos apenas analisando a utilização, mas poderíamos atribuir essa latência a algo não relacionado, como uma rede, que nos levaria ao caminho errado.
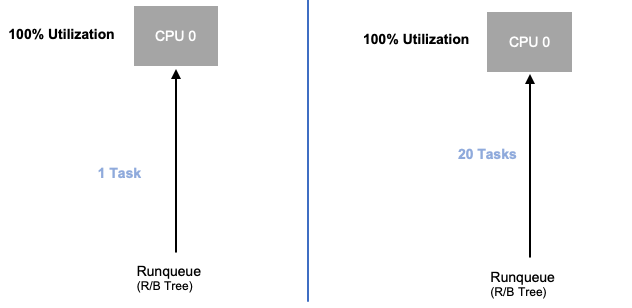
É importante visualizar as métricas de saturação, não apenas as métricas de utilização, ao aumentar o número total de pods em execução em um nó a qualquer momento, pois podemos facilmente ignorar o fato de termos saturado demais um nó. Para essa tarefa, podemos usar métricas de informações de parada de pressão, conforme mostrado no gráfico abaixo.
PromQL - E/S paralisada
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
nota
Para obter mais informações sobre as métricas de paralisação de pressão, consulte https://facebookmicrosites.github. io/psi/docs/overview
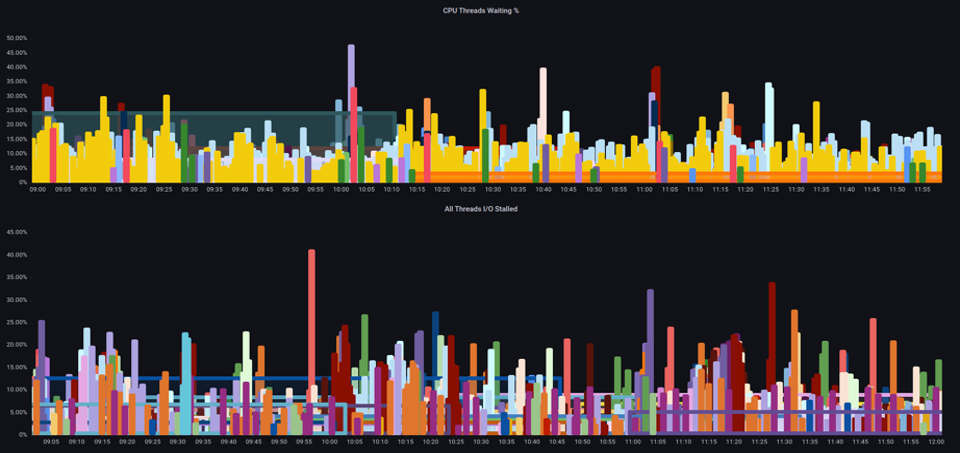
Com essas métricas, podemos dizer se os encadeamentos estão aguardando na CPU ou mesmo se todos os encadeamentos na caixa estão paralisados aguardando recursos, como memória, ou I/O. For example, we could see what percentage every thread on the instance was stalled waiting on I/O por um período de 1 min.
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Usando essa métrica, podemos ver no gráfico acima que cada thread na caixa ficou paralisado em 45% do tempo de espera I/O no limite máximo, o que significa que estávamos jogando fora todos esses ciclos de CPU naquele minuto. Entender que isso está acontecendo pode nos ajudar a recuperar uma quantidade significativa de tempo de vCPU, tornando o escalonamento mais eficiente.
HPA V2
É recomendável usar a versão autoscaling/v2 da API HPA. As versões mais antigas da API HPA podem travar o escalonamento em alguns casos extremos. Também foi limitado à duplicação de pods durante cada etapa de escalonamento, o que criou problemas para pequenas implantações que precisavam ser escaladas rapidamente.
O escalonamento automático/V2 nos permite mais flexibilidade para incluir vários critérios para escalar e nos permite uma grande flexibilidade ao usar métricas personalizadas e externas (não métricas K8s).
Como exemplo, podemos escalar o maior dos três valores (veja abaixo). Nós escalamos se a utilização média de todos os pods for superior a 50%, se as métricas personalizadas mostrarem os pacotes por segundo de entrada excederem a média de 1.000 ou se o objeto de entrada exceder 10.000 solicitações por segundo.
nota
Isso é apenas para mostrar a flexibilidade da API de auto-scaling, que não recomendamos regras excessivamente complexas que podem ser difíceis de solucionar na produção.
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
No entanto, aprendemos o perigo de usar essas métricas para aplicativos web complexos. Nesse caso, seria melhor usar métricas personalizadas ou externas que refletissem com precisão a saturação de nosso aplicativo versus a utilização. HPAv2 permite isso ao ter a capacidade de escalar de acordo com qualquer métrica, no entanto, ainda precisamos encontrar e exportar essa métrica para o Kubernetes para uso.
Por exemplo, podemos ver a contagem ativa de filas de threads no Apache. Isso geralmente cria um perfil de escala “mais suave” (falaremos mais sobre esse termo em breve). Se um encadeamento estiver ativo, não importa se esse encadeamento está aguardando em uma camada de banco de dados ou atendendo a uma solicitação localmente; se todos os encadeamentos do aplicativo estiverem sendo usados, é uma ótima indicação de que o aplicativo está saturado.
Podemos usar esse esgotamento de threads como um sinal para criar um novo pod com um pool de threads totalmente disponível. Isso também nos dá controle sobre o tamanho do buffer que queremos que o aplicativo absorva durante períodos de tráfego intenso. Por exemplo, se tivéssemos um pool total de 10 threads, o escalonamento em 4 threads usados versus 8 threads usados teria um grande impacto no buffer que temos disponível ao escalar o aplicativo. Uma configuração de 4 faria sentido para um aplicativo que precisa ser escalado rapidamente sob carga pesada, enquanto uma configuração de 8 seria mais eficiente com nossos recursos se tivéssemos tempo suficiente para escalar devido ao número de solicitações aumentando lentamente em vez de acentuadamente com o tempo.
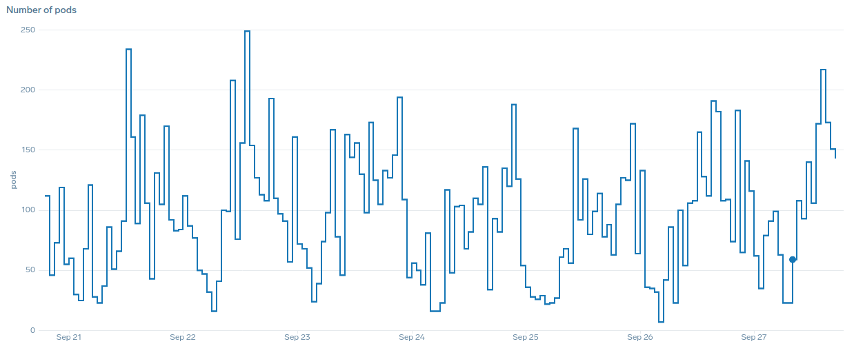
O que queremos dizer com o termo “suave” quando se trata de escalabilidade? Observe o gráfico abaixo em que estamos usando a CPU como métrica. Os pods nesta implantação estão aumentando em um curto período, de 50 pods até 250 pods, apenas para serem reduzidos imediatamente novamente. Isso é altamente ineficiente. O escalonamento é a principal causa de rotatividade em clusters.
Observe que, depois de mudarmos para uma métrica que reflete o ponto ideal correto de nosso aplicativo (parte central do gráfico), podemos escalar sem problemas. Nosso escalonamento agora é eficiente, e nossos pods podem ser totalmente escalados com o espaço disponível que fornecemos ajustando as configurações de solicitações. Agora, um grupo menor de cápsulas está fazendo o trabalho que centenas de cápsulas faziam antes. Dados do mundo real mostram que esse é o fator número um na escalabilidade dos clusters Kubernetes.
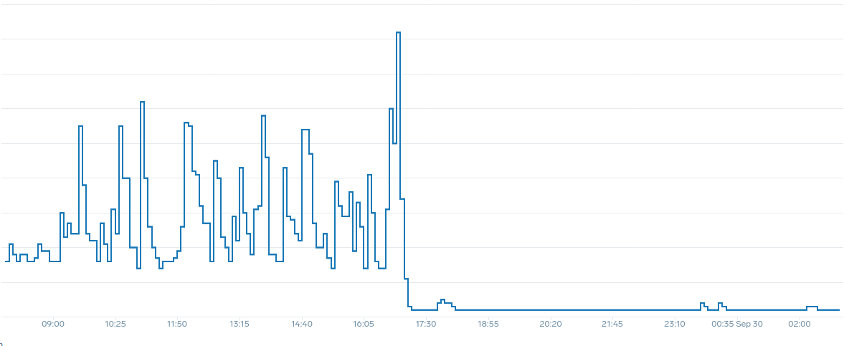
A principal conclusão é que a utilização da CPU é apenas uma dimensão do desempenho do aplicativo e do nó. Usar a utilização da CPU como um único indicador de integridade para nossos nós e aplicativos cria problemas de escalabilidade, desempenho e custo, todos conceitos estreitamente vinculados. Quanto maior o desempenho do aplicativo e dos nós, menos você precisa escalar, o que, por sua vez, reduz seus custos.
Encontrar e usar as métricas de saturação corretas para escalar seu aplicativo específico também permite monitorar e alertar sobre os verdadeiros gargalos desse aplicativo. Se essa etapa crítica for ignorada, os relatórios de problemas de desempenho serão difíceis, se não impossíveis, de entender.
Definindo limites de CPU
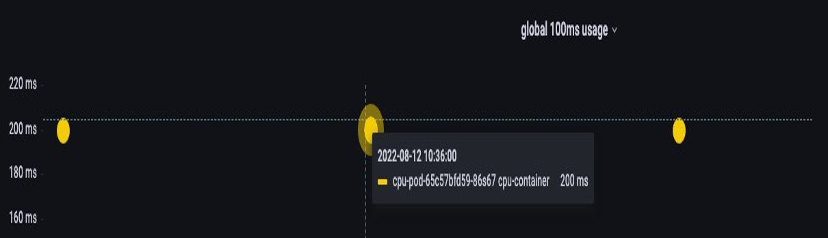
Para completar esta seção sobre tópicos incompreendidos, abordaremos os limites de CPU. Resumindo, os limites são metadados associados ao contêiner que tem um contador que é reiniciado a cada 100 ms. Isso ajuda o Linux a controlar quantos recursos da CPU são usados em todo o nó por um contêiner específico em um período de 100 ms.
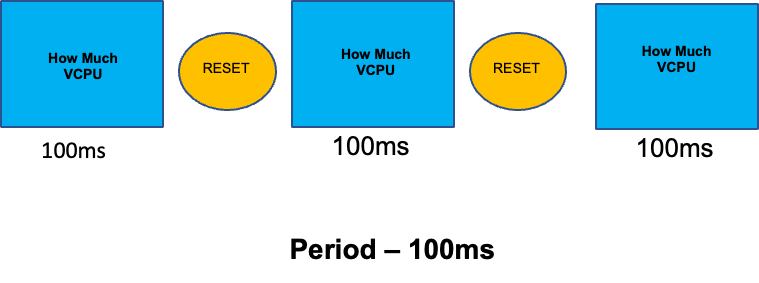
Um erro comum ao definir limites é presumir que o aplicativo é de thread único e está sendo executado somente em sua vCPU “`atribuída"`. Na seção acima, aprendemos que o CFS não atribui núcleos e, na realidade, um contêiner executando grandes pools de threads será programado em todas as vCPUs disponíveis na caixa.
Se 64 threads de sistema operacional estiverem sendo executados em 64 núcleos disponíveis (do ponto de vista do nó Linux), tornaremos a conta total de tempo de CPU usado em um período de 100 ms muito grande após a soma do tempo de execução de todos esses 64 núcleos. Como isso pode ocorrer apenas durante um processo de coleta de lixo, pode ser muito fácil perder algo assim. É por isso que é necessário usar métricas para garantir que tenhamos o uso correto ao longo do tempo antes de tentar definir um limite.
Felizmente, temos uma maneira de ver exatamente quanta vCPU está sendo usada por todos os threads em um aplicativo. Usaremos a métrica container_cpu_usage_seconds_total para essa finalidade.
Como a lógica de limitação ocorre a cada 100 ms e essa métrica é uma métrica por segundo, faremos o ProMQL para corresponder a esse período de 100 ms. Se você quiser se aprofundar nesse trabalho de declaração do PromQL, consulte o blog
Consulta PromQL:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

Quando sentirmos que temos o valor certo, podemos limitar a produção. Em seguida, torna-se necessário verificar se nosso aplicativo está sendo estrangulado devido a algo inesperado. Podemos fazer isso olhando para container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
Memória
A alocação de memória é outro exemplo em que é fácil confundir o comportamento de agendamento do Kubernetes com o comportamento do Linux. CGroup Este é um tópico com mais nuances, pois houve grandes mudanças na forma como a CGroup v2 lida com a memória no Linux e o Kubernetes mudou sua sintaxe para refletir isso; leia este blog para obter mais detalhes.
Diferentemente das solicitações de CPU, as solicitações de memória não são usadas após a conclusão do processo de agendamento. Isso ocorre porque não podemos compactar a memória na CGroup v1 da mesma forma que podemos com a CPU. Isso nos deixa apenas com limites de memória, que são projetados para funcionar como uma proteção contra vazamentos de memória ao encerrar completamente o pod. Esta é uma proposta de estilo tudo ou nada, no entanto, agora recebemos novas maneiras de resolver esse problema.
Primeiro, é importante entender que configurar a quantidade certa de memória para contêineres não é tão simples quanto parece. O sistema de arquivos no Linux usará memória como cache para melhorar o desempenho. Esse cache crescerá com o tempo, e pode ser difícil saber quanta memória é bom ter para o cache, mas pode ser recuperada sem um impacto significativo no desempenho do aplicativo. Isso geralmente resulta na interpretação incorreta do uso da memória.
Ter a capacidade de “compactar” a memória foi um dos principais fatores por trás da CGroup v2. Para saber mais sobre por que a CGroup V2 foi necessária, consulte a apresentação
Felizmente, o Kubernetes agora tem o conceito de memory.min e abaixo. memory.high requests.memory Isso nos dá a opção de liberar agressivamente essa memória em cache para uso de outros contêineres. Quando o contêiner atinge o limite máximo de memória, o kernel pode recuperar agressivamente a memória desse contêiner até o valor definido em. memory.min Isso nos dá mais flexibilidade quando um nó fica sob pressão de memória.
A questão chave é: qual valor memory.min definir? É aqui que as métricas de paralisação da pressão de memória entram em ação. Podemos usar essas métricas para detectar “perda” de memória no nível do contêiner. Então, podemos usar controladores como fbtaxmemory.min por essa perda de memória e definir dinamicamente o valor para essa configuração. memory.min
Resumo
Para resumir a seção, é fácil combinar os seguintes conceitos:
-
Utilização e saturação
-
Regras de desempenho do Linux com a lógica do Kubernetes Scheduler
É preciso ter muito cuidado para manter esses conceitos separados. Desempenho e escala estão interligados em um nível profundo. O escalonamento desnecessário cria problemas de desempenho, o que, por sua vez, cria problemas de escalabilidade.
