As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Plug-in do Apache Hive para integração do Ranger com Amazon EMR
O Apache Hive é um mecanismo de execução bastante usado dentro do ecossistema Hadoop. O Amazon EMR fornece um plug-in Apache Ranger para poder proporcionar controles de acesso refinados para o Hive. O plug-in é compatível com o servidor Apache Ranger Admin de código aberto versão 2.0 e posteriores.
Recursos compatíveis
O plug-in Apache Ranger para Hive no EMR oferece suporte a todas as funcionalidades do plug-in de código aberto, que inclui controles de acesso em nível de banco de dados, tabela e coluna, filtragem de linhas e mascaramento de dados. Para ver uma tabela dos comandos do Hive e das permissões associadas do Ranger, consulte Hive commands to Ranger permission mapping
Instalação da configuração de serviço
O plug-in Apache Hive é compatível com a definição de serviço Hive já existente no Apache Hive Hadoop SQL.
Caso não tenha uma instância de serviço no Hadoop SQL, como mostrado acima, você pode criar uma. Clique em + ao lado do Hadoop SQL.
-
Nome do serviço (se for exibido): insira o nome do serviço. O valor sugerido é
amazonemrhive. Anote esse nome de serviço, pois ele será necessário ao criar uma configuração de segurança do EMR. -
Nome de exibição: insira o nome a ser exibido para o serviço. O valor sugerido é
amazonemrhive.
As propriedades de configuração do Apache Hive são usadas para estabelecer uma conexão com seu servidor Apache Ranger Admin com um 2 HiveServer para implementar o preenchimento automático ao criar políticas. As propriedades abaixo não precisam ser precisas se você não tiver um processo persistente HiveServer 2 e puderem ser preenchidas com qualquer informação.
-
Nome de usuário: insira um nome de usuário para a conexão JDBC com uma instância de HiveServer 2 instâncias.
-
Senha: insira a senha do nome de usuário acima.
-
jdbc. driver. ClassName: insira o nome da classe JDBC para conectividade com o Apache Hive. O valor padrão pode ser usado.
-
jdbc.url: insira a string de conexão JDBC a ser usada ao se conectar a 2. HiveServer
-
Nome comum para certificado: o campo CN dentro do certificado usado para se conectar ao servidor de administração com base em um plug-in cliente. Esse valor deve corresponder ao campo CN do certificado TLS que foi criado para o plug-in.
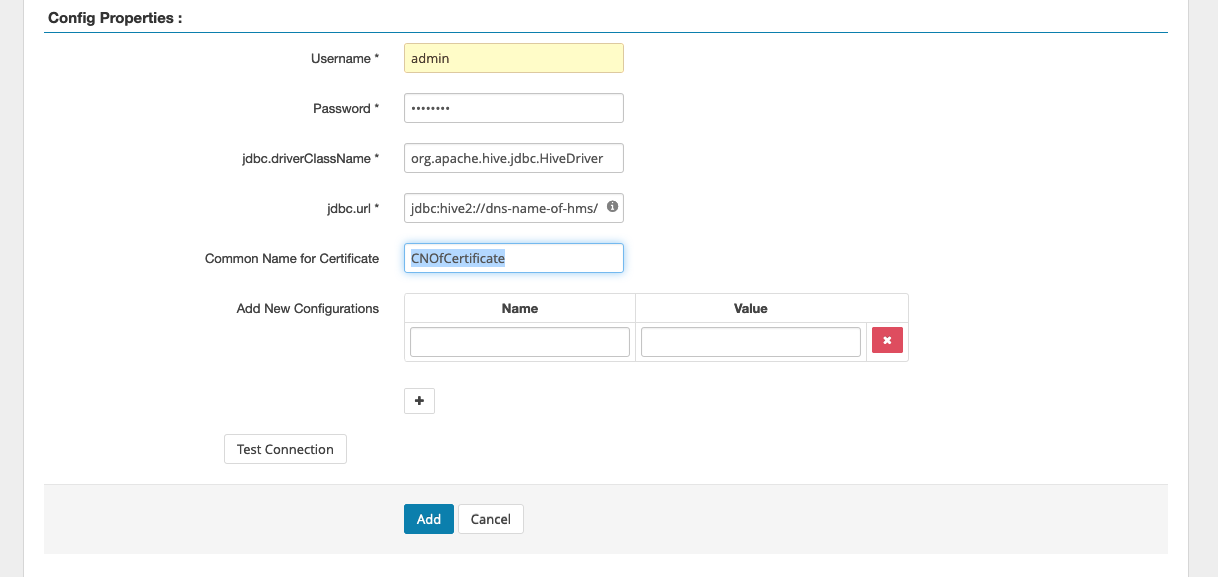
O botão Testar conexão testa se os valores acima podem ser usados para se conectar com êxito à instância HiveServer 2. Depois que o serviço for criado com êxito, o Service Manager deverá ficará semelhante a isto:
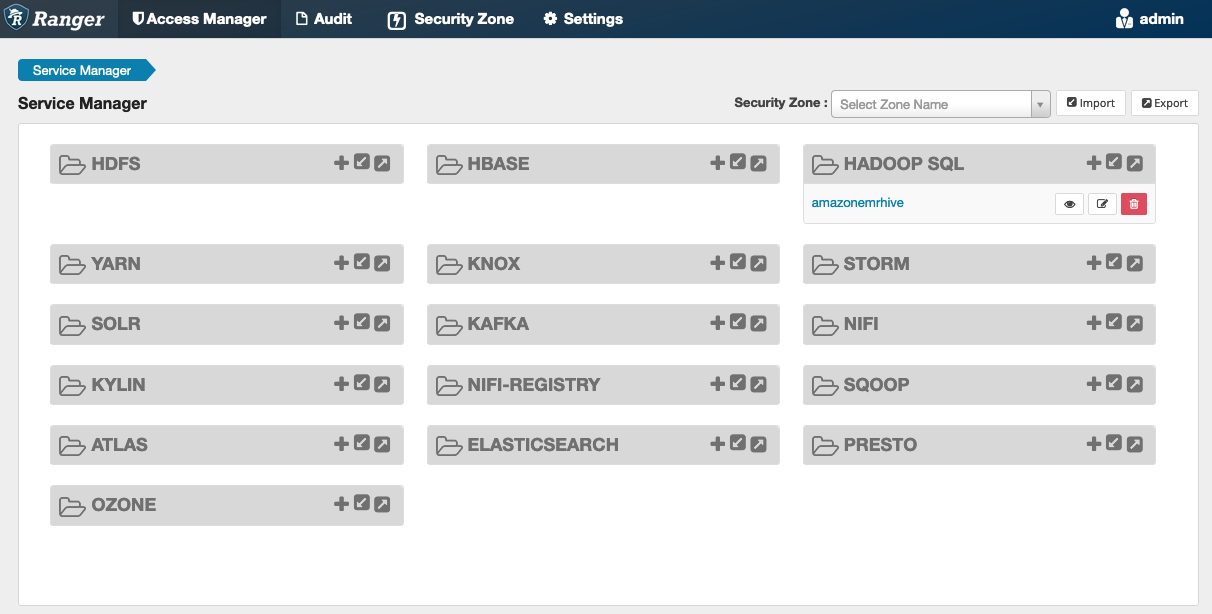
Considerações
Servidor de metadados Hive
O servidor de metadados Hive só pode ser acessado por mecanismos confiáveis, especificamente o Hive e emr_record_server, para proteção contra acesso não autorizado. O servidor de metadados Hive também é acessado por todos os nós do cluster. A porta 9083 necessária fornece acesso de todos os nós ao nó principal.
Autenticação
Por padrão, o Apache Hive está configurado para se autenticar usando Kerberos conforme configurado na configuração do EMR Security. HiveServer2 também pode ser configurado para autenticar usuários usando LDAP. Consulte Implementing LDAP authentication for Hive on a multi-tenant Amazon EMR cluster
Limitações
Estas são as limitações atuais do plug-in Apache Hive no Amazon EMR 5.x:
-
Não há suporte para perfis do Hive atualmente. Não há suporte para instruções Grant e Revoke.
-
A CLI do Hive não é suportada. JDBC/Beeline é a única forma autorizada de conectar o Hive.
-
hive.server2.builtin.udf.blacklista configuração deve ser preenchida com o UDFs que você considera inseguro.
