As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Plug-in Apache Spark
O Amazon EMR integrou o EMR RecordServer para fornecer controle de acesso refinado para o SparkSQL. O EMR RecordServer é um processo privilegiado executado em todos os nós em um cluster habilitado para Apache Ranger. Quando um driver ou executor do Spark executa uma instrução SparkSQL, todos os metadados e solicitações de dados passam pelo. RecordServer Para saber mais sobre o EMR RecordServer, consulte a Componentes do Amazon EMR página.
Tópicos
Atributos compatíveis
| Instrução SQL/ação do Ranger | STATUS | Versão do EMR compatível |
|---|---|---|
|
SELECT |
Compatível |
A partir da 5.32 |
|
SHOW DATABASES |
Compatível |
A partir da 5.32 |
|
SHOW COLUMNS |
Compatível |
A partir da 5.32 |
|
SHOW TABLES |
Compatível |
A partir da 5.32 |
|
SHOW TABLE PROPERTIES |
Compatível |
A partir da 5.32 |
|
DESCRIBE TABLE |
Compatível |
A partir da 5.32 |
|
INSERT OVERWRITE |
Compatível |
A partir da 5.34 e 6.4 |
| INSERT INTO | Compatível | A partir da 5.34 e 6.4 |
|
ALTER TABLE |
Compatível |
A partir da 6.4 |
|
CRIAR TABELA |
Compatível |
A partir da 5.35 e 6.7 |
|
CREATE DATABASE |
Compatível |
A partir da 5.35 e 6.7 |
|
DESCARTAR TABELA |
Compatível |
A partir da 5.35 e 6.7 |
|
DROP DATABASE |
Compatível |
A partir da 5.35 e 6.7 |
|
DROP VIEW |
Compatível |
A partir da 5.35 e 6.7 |
|
CREATE VIEW |
Sem suporte |
Os seguintes atributos são compatíveis com o uso do SparkSQL:
-
Controle de acesso refinado em tabelas dentro do Hive Metastore, e é possível criar políticas em nível de banco de dados, tabela e coluna.
-
As políticas do Apache Ranger podem incluir políticas de concessão e políticas de negação para usuários e grupos.
-
Os eventos de auditoria são enviados para o CloudWatch Logs.
Reimplantar a definição de serviço para usar instruções INSERT, ALTER ou DDL
nota
A partir do Amazon EMR 6.4, é possível usar o Spark SQL com as instruções: INSERT INTO, INSERT OVERWRITE ou ALTER TABLE. A partir do Amazon EMR 6.7, é possível usar o Spark SQL para criar ou eliminar bancos de dados e tabelas. Se você já tiver uma instalação no servidor Apache Ranger com definições de serviço Apache Spark implantadas, use o código a seguir para reimplantar as definições de serviço.
# Get existing Spark service definition id calling Ranger REST API and JSON processor curl --silent -f -u<admin_user_login>:<password_for_ranger_admin_user>\ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id # Download the latest Service definition wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json # Update the service definition using the Ranger REST API curl -u<admin_user_login>:<password_for_ranger_admin_user>-X PUT -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef/<Spark service definition id from step 1>'
Instalação da definição de serviço
A instalação da definição de serviço Apache Spark do EMR exige que o servidor Ranger Admin esteja configurado. Consulte Configurar o servidor do Ranger Admin.
Siga estas etapas para instalar a definição de serviço Apache Spark:
Etapa 1: SSH no servidor Apache Ranger Admin
Por exemplo: .
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
Etapa 2: baixar a definição de serviço e o plug-in do servidor Apache Ranger Admin
Em um diretório temporário, baixe a definição de serviço. Essa definição de serviço é compatível com as versões Ranger 2.x.
mkdir /tmp/emr-spark-plugin/ cd /tmp/emr-spark-plugin/ wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
Etapa 3: instalar o plug-in Apache Spark para Amazon EMR
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
Etapa 4: registrar a definição de serviço Apache Spark para Amazon EMR
curl -u *<admin users login>*:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -k 'https://*<RANGER SERVER ADDRESS>*:6182/service/public/v2/api/servicedef'
Se esse comando for executado com êxito, você verá um novo serviço na interface de usuário do Ranger Admin chamado “AMAZON-EMR-SPARK”, conforme mostrado na imagem a seguir (a versão 2.0 do Ranger é exibida).
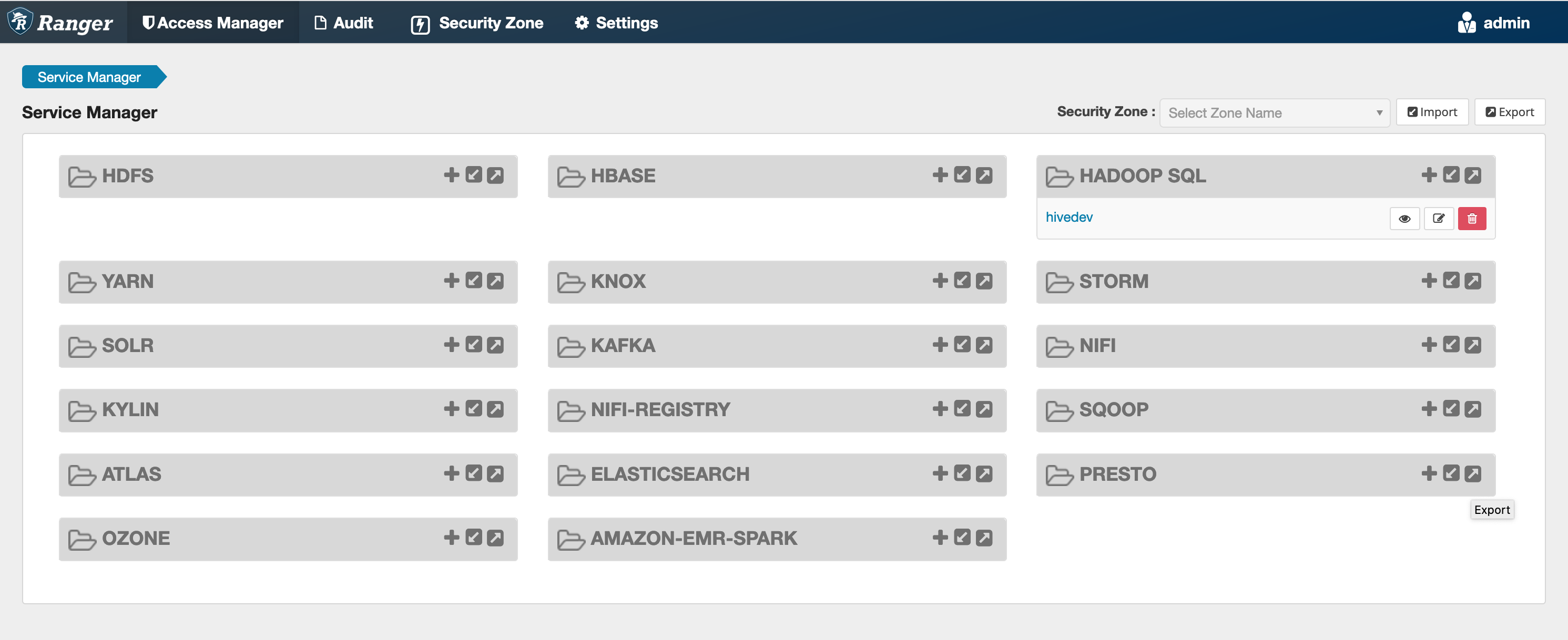
Etapa 5: criar uma instância da aplicação AMAZON-EMR-SPARK
Nome do serviço (se for exibido): o nome do serviço que será usado. O valor sugerido é amazonemrspark. Anote esse nome de serviço, pois ele será necessário ao criar uma configuração de segurança do EMR.
Nome de exibição: o nome a ser exibido para a instância. O valor sugerido é amazonemrspark.
Nome comum para certificado: o campo CN dentro do certificado usado para se conectar ao servidor de administração com base em um plug-in cliente. Esse valor deve corresponder ao campo CN do certificado TLS que foi criado para o plug-in.
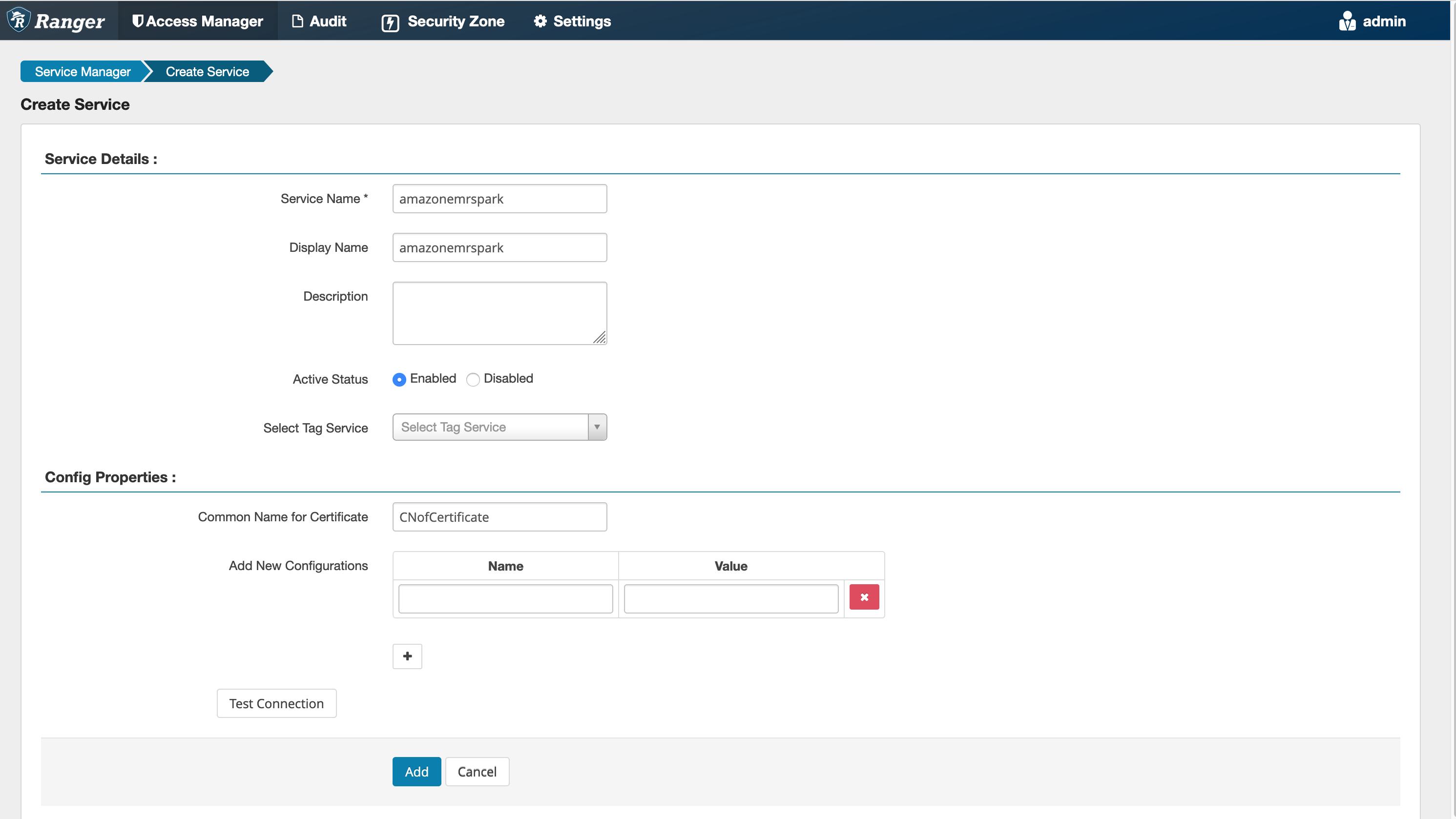
nota
O certificado TLS para o plug-in deveria ter sido registrado no armazenamento confiável do servidor Ranger Admin. Consulte Certificados TLS para obter mais detalhes.
Criar políticas SparkSQL
Ao criar uma nova política, os campos a serem preenchidos são:
Nome da política: o nome da política.
Rótulo de política: um rótulo que você pode colocar na política.
Banco de dados: o banco de dados ao qual a política se aplica. O caractere curinga “*” representa todos os bancos de dados.
Tabela: as tabelas às quais a política se aplica. O caractere curinga “*” representa todas as tabelas.
Coluna do EMR Spark: as colunas às quais a política se aplica. O caractere curinga “*” representa todas as colunas.
Descrição: uma descrição da política.
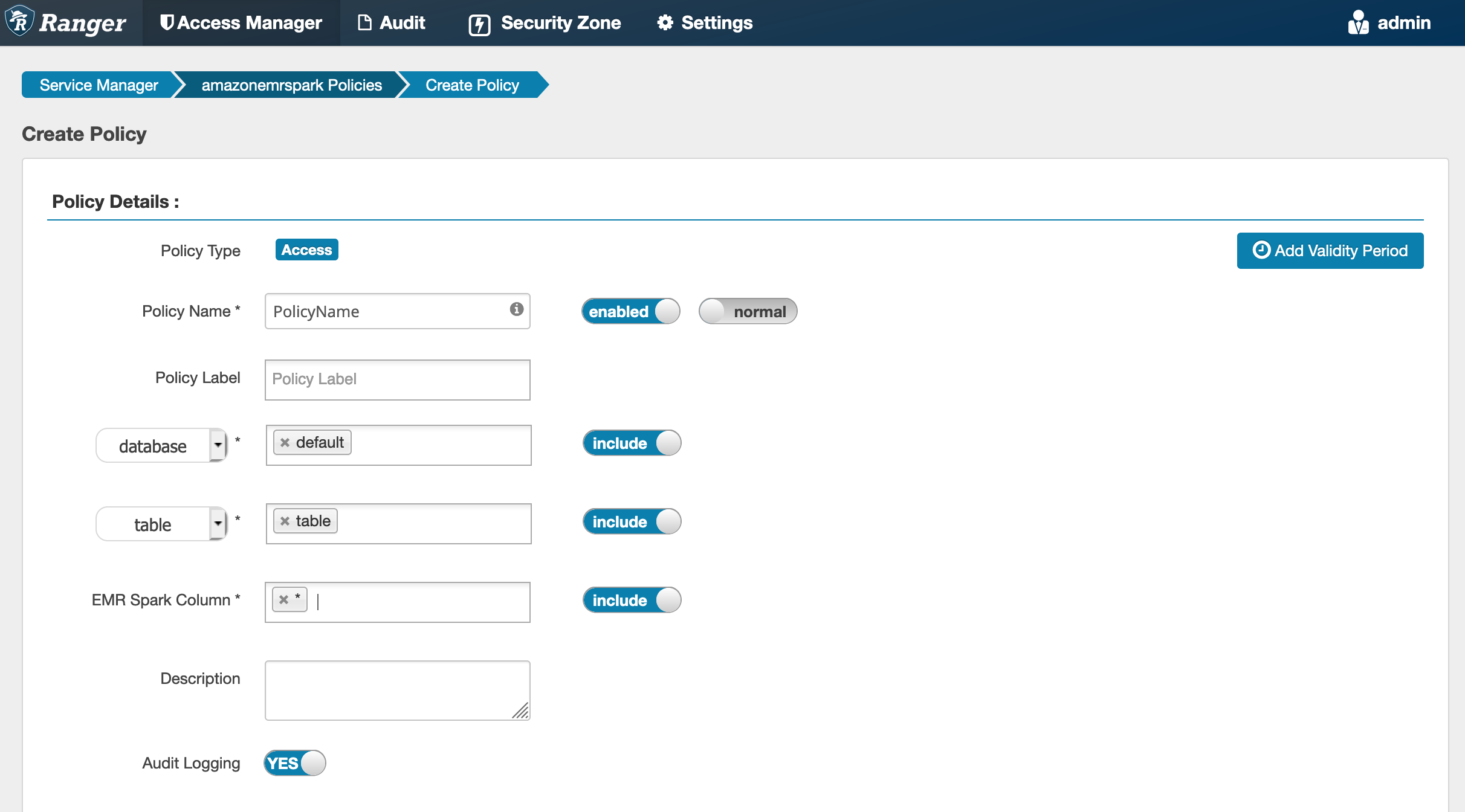
Para especificar usuários e grupos, insira os usuários e grupos abaixo para conceder permissões. Também é possível especificar exclusões para as condições de permissão e negação.
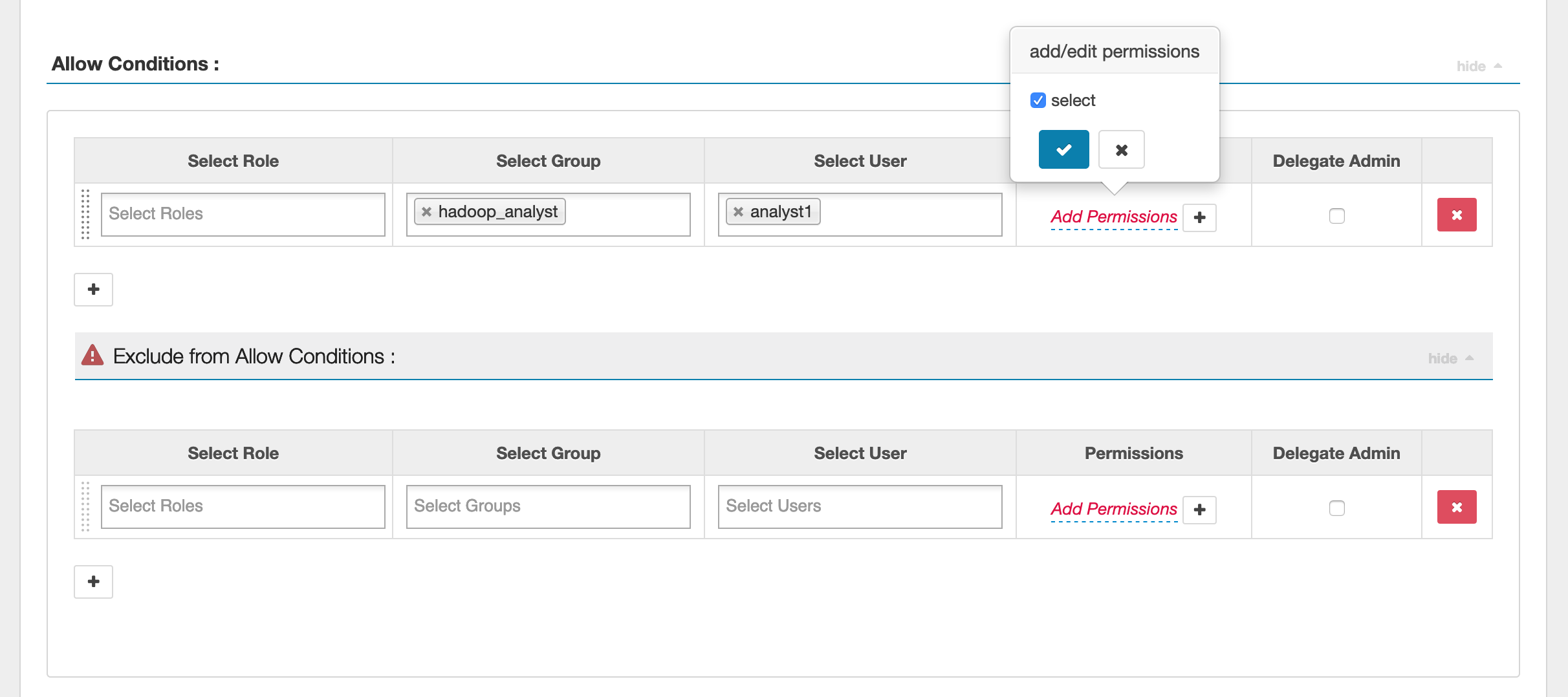
Após especificar as condições de permitir e negar, clique em Salvar.
Considerações
Cada nós do cluster do EMR deve ser capaz de se conectar ao nó principal na porta 9083.
Limitações
Estas são as limitações atuais do plug-in Apache Spark:
-
O Record Server sempre se conectará ao HMS que está em execução em um cluster do Amazon EMR. Configure o HMS para se conectar ao modo remoto, se necessário. Você não deve colocar valores de configuração no arquivo de configuração Hive-site.xml do Apache Spark.
-
As tabelas criadas usando fontes de dados do Spark em CSV ou Avro não podem ser lidas usando o EMR. RecordServer Utilize o Hive para criar e gravar dados e ler usando Record.
-
Não há suporte para tabelas Delta Lake e Hudi.
-
Os usuários precisam ter acesso ao banco de dados padrão. Esse é um requisito do Apache Spark.
-
O servidor Ranger Admin não oferece suporte ao preenchimento automático.
-
O plug-in SparkSQL para Amazon EMR não oferece suporte a filtros de linha ou a mascaramento de dados.
-
Ao ser usado ALTER TABLE com Spark SQL, o local da partição deve ser o diretório filho do local de uma tabela. Não há suporte para inserção de dados em uma partição em que a localização da partição seja diferente da localização da tabela.
