As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
HBase no Amazon S3 (modo de armazenamento Amazon S3)
Ao executar HBase no Amazon EMR versão 5.2.0 ou posterior, você pode habilitar no Amazon HBase S3, que oferece as seguintes vantagens:
O diretório HBase raiz é armazenado no Amazon S3, incluindo arquivos de HBase armazenamento e metadados de tabelas. Esses dados são persistentes fora do cluster, disponíveis nas zonas de EC2 disponibilidade da Amazon, e você não precisa se recuperar usando snapshots ou outros métodos.
Com arquivos de armazenamento no Amazon S3, você pode dimensionar seu cluster do Amazon EMR para suas necessidades de computação em vez de requisitos de dados, com replicação de 3x no HDFS.
Usando o Amazon EMR versão 5.7.0 ou posterior, você pode configurar um cluster de réplica de leitura, que permite manter cópias somente leitura dos dados no Amazon S3. Você pode acessar os dados do cluster de réplica de leitura para realizar operações de leitura simultaneamente e no evento de o cluster primário se tornar indisponível.
No Amazon EMR versão 6.2.0 a 7.3.0, o HFile rastreamento persistente usa uma tabela HBase do sistema chamada
hbase:storefilepara rastrear diretamente os HFile caminhos usados para operações de leitura. Esse atributo é habilitado por padrão e não exige que a migração manual seja executada. Nas versões superiores à 7.3.0, HFile os caminhos são rastreados usando um rastreador de arquivos, armazenando HFile os caminhos diretamente em um meta-arquivo, dentro do diretório de armazenamento.
nota
Usuários que estão usando uma versão do Amazon EMR anterior à 7.4.0 e estão migrando para o EMR-7.4.0 e posterior, consulte Migração de HBase versões anteriores e siga a documentação de atualização disponível para garantir uma transição tranquila.
A ilustração a seguir mostra os HBase componentes relevantes HBase no Amazon S3.
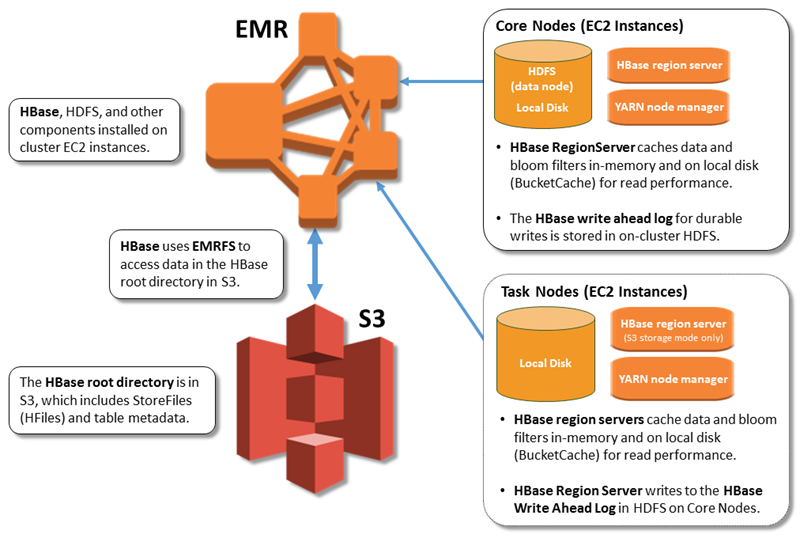
Habilitando HBase no Amazon S3
Você pode habilitar HBase no Amazon S3 usando o console do Amazon EMR, o AWS CLI ou a API do Amazon EMR. A configuração é uma opção durante a criação do cluster. Ao usar o console, você escolhe a configuração usando Advanced options (Opções avançadas). Quando você usa a AWS CLI, use a opção --configurations para fornecer um objeto de configuração JSON. As propriedades do objeto de configuração especificam o modo de armazenamento e o local do diretório raiz no Amazon S3. O local do Amazon S3 que você especificar deve estar na mesma região que seu cluster do Amazon EMR. Somente um cluster ativo por vez pode usar o mesmo diretório HBase raiz no Amazon S3. Para ver as etapas do console e um exemplo detalhado de criação de cluster usando o AWS CLI, consulte. Criação de um cluster com HBase Um objeto de configuração de exemplo é mostrado no seguinte trecho de código JSON.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
nota
Se você usar um bucket do Amazon S3 como forma HBase, deverá adicionar uma barra no final do URI do Amazon S3. rootdir Por exemplo, é necessário usar "hbase.rootdir: s3://amzn-s3-demo-bucket/", em vez de "hbase.rootdir: s3://amzn-s3-demo-bucket", para evitar problemas.
Usar um cluster de réplica de leitura
Depois de configurar um cluster primário usando o HBase Amazon S3, você pode criar e configurar um cluster de réplica de leitura que fornece acesso somente de leitura aos mesmos dados do cluster primário. Isso é útil quando você precisa de acesso simultâneo para consultar dados ou de acesso ininterrupto caso o cluster primário se torne indisponível. O atributo de réplica de leitura está disponível no Amazon EMR 5.7.0 e versões posteriores.
O cluster primário e o cluster de réplica de leitura são configuradas da mesma maneira, com uma diferença importante. Ambos apontam para o mesmo local hbase.rootdir. No entanto, a classificação hbase para o cluster de réplica de leitura inclui a propriedade "hbase.emr.readreplica.enabled":"true".
O cluster de réplica de leitura foi projetado para operações somente de leitura, e nenhuma ação manual de compactação ou gravação deve ser executada nele. Para versões do Amazon EMR anteriores à 7.4.0, é recomendável desativar a compactação no cluster de réplica de leitura ao ativar o recurso de réplica de leitura. Essa precaução é necessária porque, com o recurso de HFile rastreamento persistente ativado no cluster primário, é possível que o cluster de réplica de leitura compacte as tabelas do sistema, o que pode causar uma falha FileNotFoundException no cluster primário. Desativar a compactação no cluster de réplica de leitura evita inconsistências de dados entre os clusters primário e de réplica de leitura.
Por exemplo, dada a classificação JSON para o cluster primário, conforme mostrado anteriormente neste tópico, a configuração de um cluster de réplica de leitura para versões do EMR anteriores à 7.4.0 é a seguinte:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
Para versões do Amazon EMR posteriores à 7.3.0, agora usamos o Acompanhamento de arquivos da loja recurso, portanto, não há necessidade de desativar as compactações.
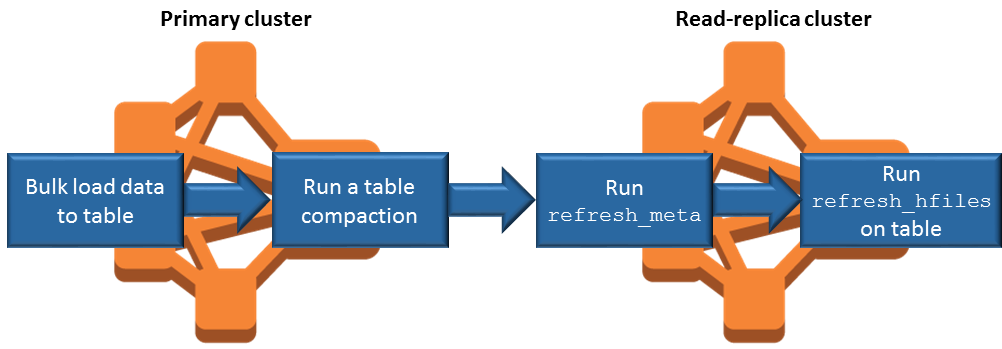
Sincronizar a réplica de leitura ao adicionar dados
Como a réplica de leitura usa HBase StoreFiles e os metadados que o cluster primário grava no Amazon S3, a réplica de leitura é tão atual quanto o armazenamento de dados do Amazon S3. A orientação a seguir pode ajudar a minimizar o tempo de retardo entre o cluster primário e a réplica de leitura quando você grava dados.
Carregue os dados em massa no cluster primário sempre que possível. Para obter mais informações, consulte Carregamento em massa
na HBase documentação do Apache. Uma liberação que grava arquivos de armazenamento no Amazon S3 deve ocorrer logo que possível após a adição dos dados. Faça a liberação manualmente ou ajuste configurações de liberação para minimizar o tempo de retardo.
Se compactações puderem ser executadas automaticamente, execute uma compactação manual para evitar inconsistências quando compactações forem acionadas.
No cluster de réplica de leitura, quando algum metadado for alterado, por exemplo, quando ocorrerem divisões ou compactações de HBase regiões, ou quando tabelas forem adicionadas ou removidas, execute o comando.
refresh_metaNo cluster de réplica de leitura, execute o comando
refresh_hfilesquando registros forem adicionados ou alterados em uma tabela.
HFile Monitoramento persistente
O HFile rastreamento persistente usa uma tabela HBase do sistema chamada hbase:storefile para rastrear diretamente os HFile caminhos usados para operações de leitura. Novos HFile caminhos são adicionados à tabela à medida que dados adicionais são adicionados HBase. Isso remove as operações de renomeação como um mecanismo de confirmação nas HBase operações críticas do caminho de gravação e melhora o tempo de recuperação ao abrir uma HBase região lendo a tabela do hbase:storefile sistema em vez da listagem de diretórios do sistema de arquivos. Esse recurso é ativado por padrão nas versões 6.2.0 a 7.3.0 do Amazon EMR e não exige nenhuma etapa de migração manual.
nota
O HFile rastreamento persistente usando a tabela do sistema HBase storefile não oferece suporte ao recurso de replicação da HBase região. Para obter mais informações sobre a replicação HBase da região, consulte Leituras de alta disponibilidade consistentes com a linha do tempo
Desativando o rastreamento persistente HFile
O HFile rastreamento persistente é ativado por padrão a partir da versão 6.2.0 do Amazon EMR. Para desativar o HFile rastreamento persistente, especifique a seguinte substituição de configuração ao iniciar um cluster:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
nota
Ao reconfigurar o cluster do Amazon EMR, todos os grupos de instâncias deverão ser atualizados.
Sincronizar a tabela Storefile manualmente
A tabela do storefile é mantida atualizada à medida que novas HFile instâncias são criadas. No entanto, se a tabela de arquivos de armazenamento ficar fora de sincronia com os arquivos de dados por qualquer motivo, os comandos a seguir poderão ser usados para sincronizar manualmente os dados:
Sincronizar a tabela storefile em uma região on-line:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
Sincronizar a tabela do storefile em uma região off-line:
Remova o znode da tabela storefile.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]Atribua a região (execute em “hbase shell”).
hbase cli> assign '<region name>'Se a tarefa falhar.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
Escalar a tabela storefile
Por padrão, a tabela storefile é dividida em quatro regiões. Se a tabela storefile continuar sob carga de gravação pesada, a tabela ainda poderá ser dividida manualmente.
Para dividir uma região ativa específica, use o comando a seguir (executado em “hbase shell”).
hbase cli> split '<region name>'
Para dividir a tabela, use o comando a seguir (execute em “hbase shell”).
hbase cli> split 'hbase:storefile'
Acompanhamento de arquivos da loja
Por padrão, usamos a FileBasedStoreFileTrackerimplementação. Essa implementação cria novos arquivos diretamente no diretório da loja, evitando a necessidade de operações de renomeação. Ele mantém uma lista de instâncias de hfile confirmadas na memória, apoiada por meta-arquivos em cada diretório de armazenamento. Sempre que um novo arquivo hfile é confirmado, a lista de arquivos rastreados no armazenamento fornecido é atualizada e um novo meta-arquivo é gravado com o conteúdo da lista e descartando o meta-arquivo anterior, que contém uma lista desatualizada. Mais informações sobre o rastreamento de arquivos da loja podem ser encontradas em Rastreamento de arquivos da loja
A implementação do FileBasedStoreFile rastreador é ativada por padrão, começando com a versão 7.4.0 do Amazon EMR:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" }
Para desativar a FileBasedStoreFileTracker implementação, especifique a seguinte substituição de configuração ao iniciar um cluster:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" }
nota
Ao reconfigurar o cluster do Amazon EMR, todos os grupos de instâncias deverão ser atualizados.
Considerações operacionais
HBase os servidores regionais são usados BlockCache para armazenar leituras de dados na memória e BucketCache armazenar leituras de dados no disco local. Além disso, os servidores regionais usam MemStore para armazenar gravações de dados na memória e usam registros de gravação antecipada para armazenar gravações de dados no HDFS antes que os dados sejam gravados no Amazon HBase StoreFiles S3. O desempenho de leitura do seu cluster estão relacionado à frequência com a qual um registro pode ser recuperado dos caches na memória ou no disco. Uma perda de cache resulta na leitura do registro StoreFile no Amazon S3, que tem latência e desvio padrão significativamente maiores do que a leitura do HDFS. Além disso, as taxas máximas de solicitações para o Amazon S3 são menores do que as que podem ser obtidas no cache local e, portanto, o armazenamento de dados no cache pode ser importante para workload com uso intensivo de leitura. Para obter mais informações sobre a performance do Amazon S3, consulte Performance optimization, no Guia do usuário do Amazon Simple Storage Service.
Para melhorar o desempenho, recomendamos que você armazene em cache o máximo possível do seu conjunto de dados no armazenamento da EC2 instância. Como BucketCache usa o armazenamento de EC2 instâncias do servidor da região, você pode escolher um tipo de EC2 instância com um armazenamento de instâncias suficiente e adicionar armazenamento do Amazon EBS para acomodar o tamanho de cache necessário. Você também pode aumentar o BucketCache tamanho dos armazenamentos de instâncias anexados e dos volumes do EBS usando a hbase.bucketcache.size propriedade. A configuração padrão é 8.192 MB.
Para gravações, a frequência de MemStore descargas e o número de StoreFiles presentes durante compactações menores e maiores podem contribuir significativamente para um aumento nos tempos de resposta do servidor regional. Para um desempenho ideal, considere aumentar o tamanho do multiplicador de MemStore fluxo e HRegion bloco, o que aumenta o tempo decorrido entre as principais compactações, mas também aumenta o atraso na consistência se você usar uma réplica de leitura. Em alguns casos, você pode obter melhor performance usando tamanhos de blocos de arquivos maiores (porém inferiores a 5 GB) para acionar a funcionalidade do carregamento multiparte do Amazon S3 no EMRFS. O tamanho padrão do bloco do Amazon EMR é 128 MB. Para obter mais informações, consulte Configuração do HDFS. Raramente há clientes que excedem 1 GB de tamanho de bloco ao fazer a comparação do desempenho com liberações e compactações. Além disso, HBase as compactações e os servidores regionais funcionam de maneira ideal quando menos StoreFiles precisam ser compactados.
Tabelas podem demorar um tempo significativo para serem descartadas no Amazon S3, pois diretórios grandes precisam ser renomeados. Considere desabilitar tabelas em vez de as descartar.
Existe um processo de HBase limpeza que limpa arquivos WAL antigos e armazena arquivos. Com o Amazon EMR versão 5.17.0 e posterior, o agente de limpeza está habilitado globalmente, e as seguintes propriedades de configuração podem ser usadas para controlar o comportamento do agente de limpeza.
| Propriedade de configuração | Valor padrão | Descrição |
|---|---|---|
|
|
1 |
O número de segmentos alocados para limpar expirou muito. HFiles |
|
|
1 |
O número de segmentos alocados para limpar expirou pouco. HFiles |
|
|
Defina como um quarto de todos os núcleos disponíveis. |
O número de threads para verificar os WALs diretórios antigos. |
|
|
2 |
O número de threads a serem limpos no WALs WALs diretório antigo. |
Com o Amazon EMR 5.17.0 e versões anteriores, a operação do agente de limpeza pode afetar a performance de consultas ao executar workloads pesadas. Por isso, recomendamos que você ative o agente de limpeza apenas fora de horários de pico. O limpador tem os seguintes comandos de HBase shell:
cleaner_chore_enabledconsulta se o agente de limpeza está habilitado.cleaner_chore_runexecuta manualmente o agente de limpeza para remover arquivos.cleaner_chore_switchhabilita ou desabilita o agente de limpeza e retorna ao seu estado anterior. Por exemplo,cleaner_chore_switch truehabilita o agente de limpeza.
Propriedades para ajuste HBase de desempenho no Amazon S3
Os parâmetros a seguir podem ser ajustados para ajustar o desempenho da sua carga de trabalho quando você usa HBase no Amazon S3.
| Propriedade de configuração | Valor padrão | Descrição |
|---|---|---|
|
|
8,192 |
A quantidade de espaço em disco, em MB, reservada nos armazenamentos de EC2 instâncias da Amazon no servidor regional e nos volumes do EBS para BucketCache armazenamento. A configuração se aplica a todas as instâncias do servidor de regiões. BucketCache Tamanhos maiores geralmente correspondem a um desempenho aprimorado |
|
|
134217728 |
O limite de dados, em bytes, no qual uma liberação de memstore para o Amazon S3 é acionada. |
|
|
4 |
Um multiplicador que determina o limite MemStore superior no qual as atualizações são bloqueadas. Se os MemStore excedentes forem |
|
|
10 |
O número máximo StoreFiles que pode existir em uma loja antes que as atualizações sejam bloqueadas. |
|
|
10737418240 |
O tamanho máximo de uma região antes que ela seja dividida. |
Desativar e restaurar um cluster sem perda de dados
Para desligar um cluster do Amazon EMR sem perder dados que não foram gravados no Amazon S3, você deve liberar seu cache no Amazon S3 MemStore para gravar novos arquivos de armazenamento. Primeiro, é necessário desabilitar todas as tabelas. A seguinte configuração de etapas pode ser usada quando você adiciona uma etapa ao cluster. Para obter mais informações, consulte Work with steps using the AWS CLI and console no Guia de gerenciamento do Amazon EMR.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
Como alternativa, você pode executar o seguinte comando bash diretamente.
bash /usr/lib/hbase/bin/disable_all_tables.sh
Depois de desativar todas as tabelas, limpe a hbase:meta tabela usando o HBase shell e o comando a seguir.
flush 'hbase:meta'
Em seguida, você pode executar um script de shell fornecido no cluster do Amazon EMR para limpar o cache. MemStore Você pode adicioná-lo como uma etapa ou executá-lo diretamente, usando a AWS CLI no cluster. O script desativa todas as HBase tabelas, o que faz com que o servidor MemStore de cada região seja transferido para o Amazon S3. Se o script for concluído com êxito, os dados persistirão no Amazon S3, e o cluster poderá ser terminado.
Para reiniciar um cluster com os mesmos HBase dados, especifique a mesma localização do Amazon S3 do cluster anterior na propriedade de hbase.rootdir configuração AWS Management Console ou usando a propriedade.
