As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como um crawler determina quando criar partições?
Quando um crawler do AWS Glue examina o Amazon S3 e detecta várias pastas em um bucket, ele determina a raiz de uma tabela na estrutura de pastas e quais pastas são partições de uma tabela. O nome da tabela é baseado no prefixo do Amazon S3 ou no nome da pasta. Você fornece um Include path (caminho de inclusão) que indica o nível da pasta a ser rastreada. Quando a maioria dos esquemas em um nível de pasta é semelhante, o crawler cria partições de uma tabela em vez de duas tabelas separadas. Para influenciar o crawler a criar tabelas separadas, adicione a pasta raiz de cada tabela como um repositório de dados separado ao definir o crawler.
Por exemplo, considere a seguinte estrutura de pastas do Amazon S3.
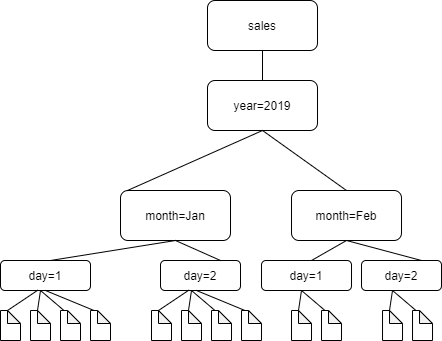
Os caminhos para as quatro pastas de nível mais baixo são os seguintes:
S3://sales/year=2019/month=Jan/day=1 S3://sales/year=2019/month=Jan/day=2 S3://sales/year=2019/month=Feb/day=1 S3://sales/year=2019/month=Feb/day=2
Suponha que o destino do crawler esteja definido em Sales e que todos os arquivos no day=n têm o mesmo formato (por exemplo, JSON, não criptografado) e têm os mesmos esquemas, ou esquemas muito semelhantes. O crawler criará uma única tabela com quatro partições, com chaves de partição year, month e day.
No exemplo a seguir, considere a seguinte estrutura do Amazon S3:
s3://bucket01/folder1/table1/partition1/file.txt s3://bucket01/folder1/table1/partition2/file.txt s3://bucket01/folder1/table1/partition3/file.txt s3://bucket01/folder1/table2/partition4/file.txt s3://bucket01/folder1/table2/partition5/file.txt
Se os esquemas para arquivos em table1 e table2 forem semelhantes e um único armazenamento de dados estiver definido no crawler com Include path (Caminho de inclusão) s3://bucket01/folder1/, o crawler cria uma única tabela com duas colunas de chave de partição. A primeira coluna de chave de partição contém table1 e table2, e a segunda coluna de chave de partição contém partition1 a partition3 para a partição da table1 e partition4 e partition5 para a partição da table2. Para criar duas tabelas separadas, defina o crawler com dois armazenamentos de dados. Neste exemplo, defina o primeiro Include path (Caminho de inclusão) como s3://bucket01/folder1/table1/, e o segundo como s3://bucket01/folder1/table2.
nota
No Amazon Athena, cada tabela corresponde a um prefixo do Amazon S3 com todos os objetos nele. Se os objetos têm diferentes esquemas, o Athena não reconhece os objetos diferentes no mesmo prefixo como tabelas separadas. Isso pode acontecer se um crawler criar várias tabelas a partir do mesmo prefixo do Amazon S3. Isso pode levar a consultas no Athena que retornam zero resultados. Para que o Athena reconheça e consulte corretamente as tabelas, crie o crawler com um Include path (Caminho de inclusão) separado para cada esquema de tabela diferente na estrutura de pastas do Amazon S3. Para obter mais informações, consulte Práticas recomendadas ao usar o Athena com o AWS Glue e este artigo da Central de Conhecimento da AWS
