As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Tutorial: usar um caderno do SageMaker com seu endpoint de desenvolvimento
No AWS Glue, você pode criar um endpoint de desenvolvimento e, depois, criar um caderno do SageMaker para ajudar a desenvolver os scripts de ETL e machine learning. Um bloco de anotações do SageMaker é uma instância de computação de machine learning totalmente gerenciada que executa o aplicativo Jupyter Notebook.
-
No console do AWS Glue, escolha Dev endpoints para navegar até a lista de endpoints de desenvolvimento.
-
Marque a caixa de seleção ao lado do nome de um endpoint de desenvolvimento que você deseja usar e, no menu Action (Ação), escolha Create SageMaker notebook (Criar bloco de anotações do SageMaker).
-
Preencha a página Create and configure a notebook (Criar e configurar um bloco de anotações) da seguinte forma:
-
Insira um nome de bloco de anotações.
-
Em Attach to development endpoint (Anexar ao endpoint de desenvolvimento), verifique o endpoint de desenvolvimento.
-
Crie ou escolha uma função do AWS Identity and Access Management (IAM).
A criação de uma função é recomendada. Se você usar uma função existente, verifique se ela tem as permissões necessárias. Para ter mais informações, consulte Etapa 6: criar uma política do IAM para cadernos do SageMaker.
-
(Opcional) Escolha uma VPC, uma sub-rede e um ou mais grupos de segurança.
-
(Opcional) Escolha uma chave de criptografia do AWS Key Management Service.
-
(Opcional) Adicione tags para a instância do bloco de anotações.
-
-
Escolha Criar caderno. Na página Notebooks (Blocos de anotações), escolha o ícone de atualização no canto superior direito e continue até que o Status seja
Ready. -
Marque a caixa de seleção ao lado do nome do novo bloco de anotações e escolha Open notebook (Abrir bloco de anotações).
-
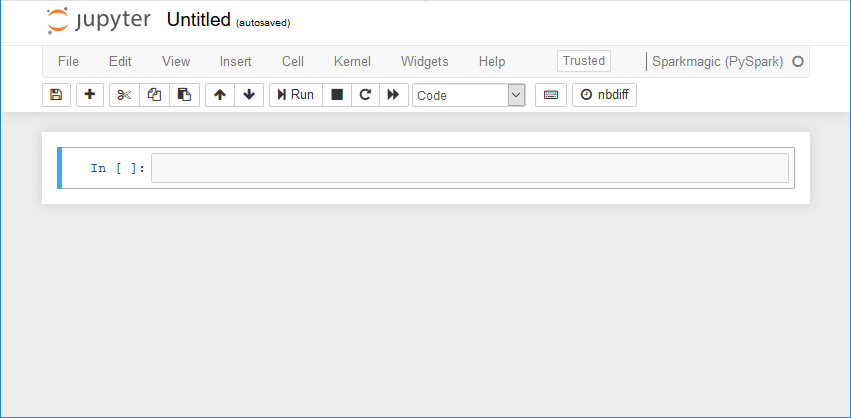
Criar um novo bloco de anotações: na página jupyter, escolha New (Novo) e Sparkmagic (PySpark).
Sua tela agora deve ser semelhante ao seguinte:
-
(Opcional) Na parte superior da página, escolha Untitled (Sem título) e dê um nome ao bloco de anotações.
-
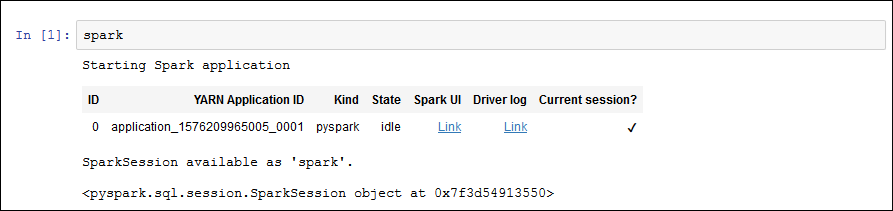
Para iniciar um aplicativo do Spark, digite o seguinte comando no bloco de anotações e, na barra de ferramentas, escolha Run (Executar).
sparkApós um pequeno atraso, você deve ver a seguinte resposta:
-
Criar um quadro dinâmico e executar uma consulta: copie, cole e execute o seguinte código, que gera a contagem e o esquema da tabela
persons_json.import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * glueContext = GlueContext(SparkContext.getOrCreate()) persons_DyF = glueContext.create_dynamic_frame.from_catalog(database="legislators", table_name="persons_json") print ("Count: ", persons_DyF.count()) persons_DyF.printSchema()
