Conceitos avançados de streaming do AWS Glue
Em aplicações contemporâneas orientadas a dados, a importância dos dados diminui ao longo do tempo e o seu valor passa de preditivo a reativo. Como resultado, os clientes desejam processar dados em tempo real para tomar decisões mais rápidas. Ao lidar com feeds de dados em tempo real, como os provenientes de sensores de IoT, os dados podem ser apresentados de forma desordenada ou sofrer atrasos no processamento devido à latência da rede e outras falhas relacionadas à fonte durante a ingestão. Como parte da plataforma do AWS Glue, o AWS Glue Streaming aproveita essas funcionalidades para fornecer ETL de streaming escalável e com tecnologia sem servidor, com base no streaming estruturado do Apache Spark, capacitando os usuários com processamento de dados em tempo real.
Neste tópico, exploraremos as funcionalidades e os conceitos avançados de streaming do AWS Glue Streaming.
Considerações sobre o tempo ao processar fluxos
Existem quatro noções de tempo no momento do processamento de fluxos:

-
Horário do evento: o horário em que o evento ocorreu. Na maioria dos casos, este campo está incorporado aos próprios dados do evento, na fonte.
-
Janela de horário do evento: o intervalo entre dois horários de eventos. Conforme mostrado no diagrama acima, W1 é uma janela de horário do evento das 17h às 17h10. Cada janela de horário do evento corresponde a um agrupamento de vários eventos.
-
Horário do acionamento: o horário do acionamento controla a frequência com que ocorre o processamento dos dados e a atualização dos resultados. Este é o horário em que o processamento do micro lote foi iniciado.
-
Horário da ingestão: o horário em que os dados de fluxo foram ingeridos no serviço de streaming. Se o horário do evento não estiver incorporado no próprio evento, esse horário poderá ser usado para a geração de janelas em alguns casos.
Geração de janelas
A geração de janelas é uma técnica em que você agrupa e agrega vários eventos por janela de horário do evento. Exploraremos, nos exemplos a seguir, os benefícios da geração de janelas e quando você poderia usá-la.
Dependendo do caso de uso de negócio, existem três tipos de janelas de horários com suporte do Spark.
-
Janela em cascata: uma série de janelas de horário do evento com tamanho fixo e não sobrepostas sobre as quais você realiza agregações.
-
Janela deslizante: semelhante às janelas em cascata em relação a terem um “tamanho fixo”, mas as janelas podem se sobrepor ou deslizar desde que a duração do deslizamento seja menor que a duração da própria janela.
-
Janela de sessão: começa com um evento de dados de entrada e continua a se expandir enquanto recebe entradas dentro de um intervalo ou período de inatividade. Uma janela de sessão pode ter um tamanho estático ou dinâmico da dimensão da janela, dependendo das entradas.
Janela em cascata
A janela em cascata corresponde a uma série de janelas de horário do evento com tamanho fixo e não sobrepostas sobre as quais você realiza agregações. Vamos entender isso com um exemplo real.
A empresa ABC Auto deseja realizar uma campanha de marketing para uma nova marca de carros esportivos. Eles desejam escolher uma cidade na qual haja um grande número de fãs de carros esportivos. Para atingir esse objetivo, a empresa mostra um pequeno anúncio de 15 segundos apresentando o carro em seu site. Todos os “cliques” e a “cidade” correspondente são registrados e transmitidos para o Amazon Kinesis Data Streams. Desejamos contabilizar o número de cliques em uma janela de dez minutos e agrupá-los por cidade para visualizar qual cidade tem a maior demanda. Veja a seguir a saída da agregação.
| window_start_time | window_end_time | city | total_clicks |
|---|---|---|---|
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | Dallas | 75 |
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | Chicago | 10 |
| 2023-07-10 17:20:00 | 2023-07-10 17:30:00 | Dallas | 20 |
| 2023-07-10 17:20:00 | 2023-07-10 17:30:00 | Chicago | 50 |
Conforme explicado acima, essas janelas de horário do evento são diferentes dos intervalos de horário do acionamento. Por exemplo, mesmo que o horário do acionamento seja a cada minuto, os resultados de saída mostrarão somente janelas de agregação não sobrepostas de dez minutos. Para obter otimização, é melhor ter o intervalo de acionamento alinhado com a janela de horário do evento.
Na tabela acima, Dallas realizou 75 cliques na janela das 17h às 17h10, enquanto Chicago realizou dez cliques. Além disso, não há dados para a janela das 17h10 às 17h20 para nenhuma cidade; portanto, essa janela é omitida.
Agora, é possível executar análise aprofundadas nesses dados na aplicação de analytics downstream para determinar a cidade mais exclusiva para executar a campanha de marketing.
Uso de janelas em cascata no AWS Glue
-
Crie um DataFrame do Amazon Kinesis Data Streams e faça a leitura nesse serviço. Exemplo:
parsed_df = kinesis_raw_df \ .selectExpr('CAST(data AS STRING)') \ .select(from_json("data", ticker_schema).alias("data")) \ .select('data.event_time','data.ticker','data.trade','data.volume', 'data.price') -
Processe dados em uma janela em cascata. No exemplo abaixo, os dados são agrupados com base no campo de entrada “event_time” em janelas em cascata de dez minutos e a saída é gravada em um data lake do Amazon S3.
grouped_df = parsed_df \ .groupBy(window("event_time", "10 minutes"), "city") \ .agg(sum("clicks").alias("total_clicks")) summary_df = grouped_df \ .withColumn("window_start_time", col("window.start")) \ .withColumn("window_end_time", col("window.end")) \ .withColumn("year", year("window_start_time")) \ .withColumn("month", month("window_start_time")) \ .withColumn("day", dayofmonth("window_start_time")) \ .withColumn("hour", hour("window_start_time")) \ .withColumn("minute", minute("window_start_time")) \ .drop("window") write_result = summary_df \ .writeStream \ .format("parquet") \ .trigger(processingTime="10 seconds") \ .option("checkpointLocation", "s3a://bucket-stock-stream/stock-stream-catalog-job/checkpoint/") \ .option("path", "s3a://bucket-stock-stream/stock-stream-catalog-job/summary_output/") \ .partitionBy("year", "month", "day") \ .start()
Janela deslizante
As janelas deslizantes são semelhantes às janelas em cascata em relação a terem um “tamanho fixo”, mas as janelas podem se sobrepor ou deslizar desde que a duração do deslizamento seja menor que a duração da própria janela. Devido à natureza do deslizamento, uma entrada pode ser vinculada a múltiplas janelas.
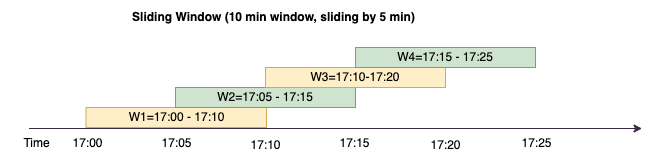
Para uma melhor compreensão, vamos considerar o exemplo de um banco que deseja detectar possíveis fraudes relacionadas a cartões de crédito. Uma aplicação de streaming poderia monitorar um fluxo contínuo de transações de cartões de crédito. Essas transações poderiam ser agregadas em janelas de dez minutos de duração e, a cada cinco minutos, a janela avançaria, eliminando os cinco minutos de dados mais antigos e adicionando os cinco minutos de novos dados mais recentes. Dentro de cada janela, as transações poderiam ser agrupadas por país, verificando padrões suspeitos, como uma transação nos Estados Unidos imediatamente seguida por outra na Austrália. Para simplificar, categorizaremos essas transações como fraude quando o valor total das transações for superior a USD 100. Se esse padrão for detectado, uma possível fraude será sinalizada e o cartão poderá ser congelado.
O sistema de processamento de cartões de crédito está enviando uma série de eventos de transação ao Kinesis para cada identificação de cartão em conjunto com o país. Um trabalho do AWS Glue executa a análise e produz a saída agregada apresentada a seguir.
| window_start_time | window_end_time | card_last_four | country | total_amount |
|---|---|---|---|---|
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | 6544 | EUA | 85 |
| 2023-07-10 17:00:00 | 2023-07-10 17:10:00 | 6544 | Austrália | 10 |
| 2023-07-10 17:05:45 | 2023-07-10 17:15:45 | 6544 | EUA | 50 |
| 2023-07-10 17:10:45 | 2023-07-10 17:20:45 | 6544 | EUA | 50 |
| 2023-07-10 17:10:45 | 2023-07-10 17:20:45 | 6544 | Austrália | 150 |
Com base na agregação acima, você pode visualizar a janela de dez minutos deslizando a cada cinco minutos, somada pelo valor da transação. A anomalia é detectada na janela das 17h10 às 17h20, na qual há um ponto fora da curva, que é uma transação de USD 150 na Austrália. O AWS Glue pode detectar essa anomalia e enviar um evento de alarme com a chave do infrator para um tópico do SNS usando o Boto3. Além disso, uma função do Lambda pode se inscrever nesse tópico e executar ações.
Processamento de dados em uma janela deslizante
A cláusula group-by e a função de janela são usadas para implementar a janela deslizante, conforme mostrado abaixo.
grouped_df = parsed_df \ .groupBy(window(col("event_time"), "10 minute", "5 min"), "country", "card_last_four") \ .agg(sum("tx_amount").alias("total_amount"))
Janela de sessão
Ao contrário das duas janelas apresentadas acima, que possuem tamanho fixo, a janela de sessão pode ter um tamanho estático ou dinâmico da dimensão da janela com base nas entradas. Uma janela de sessão começa com um evento de dados de entrada e continua a se expandir enquanto recebe entradas dentro de um intervalo ou período de inatividade.

Vamos analisar um exemplo. A empresa ABC Hotel deseja descobrir qual é o horário de maior movimento em uma semana e apresentar melhores ofertas para seus hóspedes. Assim que um hóspede realiza o check-in, uma janela de sessão é iniciada e o Spark mantém um estado com agregação para essa janela de horário do evento. Cada vez que um hóspede realiza o check-in, um evento é gerado e enviado ao Amazon Kinesis Data Streams. O hotel decide que se não houver realização de check-in por um período de 15 minutos, a janela de horário do evento poderá ser fechada. A próxima janela de horário do evento começará novamente quando houver uma nova realização de check-in. A saída é semelhante à apresentada a seguir.
| window_start_time | window_end_time | city | total_checkins |
|---|---|---|---|
| 2023-07-10 17:02:00 | 2023-07-10 17:30:00 | Dallas | 50 |
| 2023-07-10 17:02:00 | 2023-07-10 17:30:00 | Chicago | 25 |
| 2023-07-10 17:40:00 | 2023-07-10 18:20:00 | Dallas | 75 |
| 2023-07-10 18:50:45 | 2023-07-10 19:15:45 | Dallas | 20 |
A primeira realização de check-in ocorreu em event_time=17h02. A janela de horário do evento de agregação começará às 17h02. Essa agregação continuará enquanto recebermos eventos com intervalos de até 15 minutos. No exemplo acima, o último evento que recebemos foi às 17h15 e, em seguida, nos 15 minutos seguintes não houve eventos. Como resultado, o Spark fechou a janela de horário do evento às 17h15 e acrescentou os 15 minutos, totalizando 17h30, e a definiu como 17h02 a 17h30. Ele iniciou uma nova janela de horário do evento às 17h47, quando recebeu um novo evento de dados de realização de check-in.
Processamento de dados em uma janela de sessão
A cláusula group-by e a função de janela são usadas para implementar a janela deslizante.
grouped_df = parsed_df \ .groupBy(session_window(col("event_time"), "10 minute"), "city") \ .agg(count("check_in").alias("total_checkins"))
Modos de saída
O modo de saída corresponde ao modo no qual os resultados da tabela ilimitada são gravados no coletor externo. Existem três modos disponíveis. No exemplo apresentado a seguir, você está contabilizando as ocorrências de uma palavra à medida que as linhas de dados são transmitidas e processadas em cada micro lote.
-
Modo completo: toda a tabela de resultados será gravada no coletor após cada processamento de micro lote, mesmo que a contagem de palavras não tenha sido atualizada na janela de horário do evento atual.
-
Modo de acréscimo: esse é o modo padrão, em que somente as novas palavras e as novas linhas adicionadas à tabela de resultados desde o último acionamento serão gravadas no coletor. Esse modo é bom para o streaming sem estado para consultas, por exemplo, as funções map, flatMap, filter etc.
-
Modo de atualização: somente as palavras e as linhas na Tabela de Resultados que foram atualizadas ou adicionadas desde o último acionamento serão gravadas no coletor.
nota
O modo de saída = “atualização” não é compatível com as janelas de sessão.
Tratamento de dados atrasados e de marcas d’água
Ao trabalhar com dados em tempo real, pode haver atrasos na chegada dos dados devido à latência da rede e falhas upstream e precisamos de um mecanismo para realizar a agregação novamente na janela de horário do evento perdido. No entanto, para fazer isso, o estado precisa ser mantido. Ao mesmo tempo, os dados mais antigos precisam ser limpos para limitar o tamanho do estado. A versão 2.1 do Spark adicionou suporte para um recurso, chamado marca d’água, que mantém o estado e permite ao usuário especificar o limite para os dados atrasados.
Com referência ao nosso exemplo de cotações da bolsa acima, consideraremos o limite permitido para os dados atrasados como não superior a dez minutos. Para simplificar, assumiremos uma janela deslizante em que as cotações serão marcadas como AMZ e as negociações como BUY.
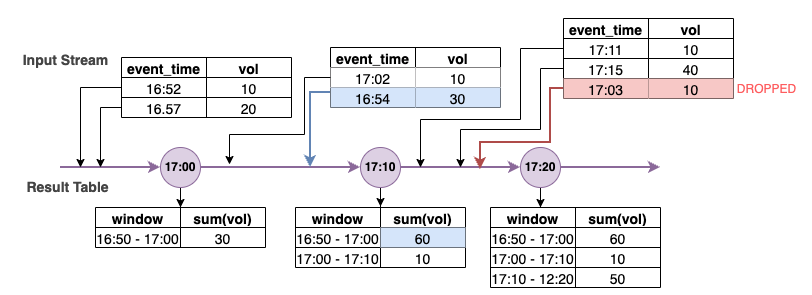
No diagrama acima, estamos calculando o volume total em uma janela deslizante de dez minutos. Temos o acionamento às 17h00, 17h10 e 17h20. Acima da seta da linha do tempo, temos o fluxo de dados de entrada e abaixo está a tabela ilimitada de resultados.
Na primeira janela deslizante de dez minutos, realizamos as agregações com base em event_time e o total_volume foi calculado como 30. Na segunda janela de horário do evento, o Spark obteve o primeiro evento de dados com event_time=17h02. Como esse é o event_time máximo obtido até o momento pelo Spark, o limite da marca d’água é definido 10 minutos atrás (ou seja, watermark_event_time=16h52). Qualquer evento de dados com um event_time após 16h52 será considerado para a agregação com limite de tempo e qualquer evento de dados anterior será descartado. Isso permite que o Spark mantenha um estado intermediário por mais dez minutos para acomodar dados atrasados. Por volta das 17h08, o Spark recebeu um evento com event_time=16h54, que estava dentro do limite. Como consequência, o Spark calculou novamente a janela de horário do evento de “16h50 a 17h00” e o volume total foi atualizado de 30 para 60.
No entanto, no horário de acionamento 17h20, quando o Spark recebeu o evento com event_time=17h15, ele definiu watermark_event_time=17h05. Como consequência, o evento de dados atrasado com event_time=17h03 foi considerado “tarde demais” e ignorado.
Watermark Boundary = Max(Event Time) - Watermark Threshold
Uso de marcas d’água no AWS Glue
O Spark só emitirá ou gravará os dados no coletor externo quando o limite da marca d’água for ultrapassado. Para implementar uma marca d’água no AWS Glue, consulte o exemplo abaixo.
grouped_df = parsed_df \ .withWatermark("event_time", "10 minutes") \ .groupBy(window("event_time", "5 minutes"), "ticker") \ .agg(sum("volume").alias("total_volume"))
