Programar crawls incrementais para adicionar novas partições
É possível configurar crawls incrementais de uma execução do Crawler do AWS Glue para adicionar somente novas partições ao esquema da tabela. Quando o crawler é executado pela primeira vez, ele executa um crawl completo para processar toda a fonte de dados para registrar o esquema completo e todas as partições existentes no AWS Glue Data Catalog.
Os crawls subsequentes após o crawl completo inicial serão incrementais, em que o crawler identifica e adiciona somente as novas partições que foram introduzidas desde o crawl anterior. Essa abordagem resulta em tempos de crawl mais rápidos, pois o crawler não precisa mais processar toda a fonte de dados para cada execução, mas se concentra apenas nas novas partições.
nota
Os crawls incrementais não detectam modificações ou exclusões de partições existentes. Essa configuração é mais adequada para fontes de dados com um esquema estável. Se ocorrer uma única alteração importante no esquema, é recomendável configurar temporariamente o crawler para realizar um crawl completo a fim de capturar o novo esquema com precisão e, em seguida, voltar ao modo de crawling incremental.
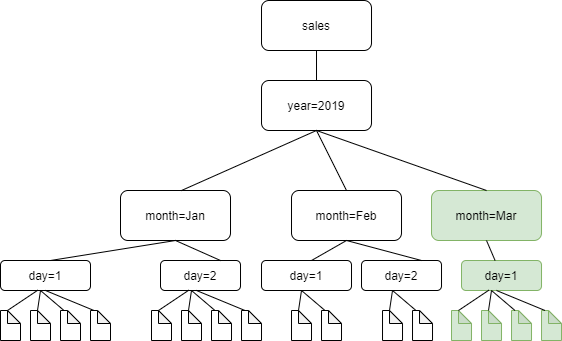
O diagrama a seguir mostra que, com a configuração de crawl incremental ativada, o crawler detectará e adicionará somente a pasta recém-adicionada, month=March, ao catálogo.
Siga estas etapas para atualizar seu crawler para realizar crawls incrementais:
Notas e restrições
Quando essa opção está ativada, não é possível alterar os armazenamentos de dados de destino do Amazon S3 ao editar o crawler. Essa opção afeta determinadas definições de configuração do crawler. Quando ativada, ela força o comportamento de atualização e de exclusão do crawler para LOG. Isto significa que:
-
Se descobrir objetos nos quais os esquemas não são compatíveis, o crawler não adicionará os objetos no Catálogo de Dados e adicionará esse detalhe como um log no CloudWatch Logs.
-
Ele não atualizará objetos excluídos no Catálogo de dados.
