Tutorial: como criar uma transformação de machine learning com o AWS Glue
Este tutorial orienta você sobre as ações para criar e gerenciar uma transformação de machine learning (ML) usando o AWS Glue. Antes de usar este tutorial, você deverá familiarizar-se com o uso do console do AWS Glue para adicionar crawlers a trabalhos e editar scripts. Você também deve se familiarizar com a localização e o download de arquivos no console do Amazon Simple Storage Service (Amazon S3).
Neste exemplo, você vai criar uma transformação FindMatches para encontrar registros correspondentes, ensiná-la como identificar registros correspondentes e não correspondentes e usá-la em um trabalho do AWS Glue. O trabalho do AWS Glue grava um novo arquivo do Amazon S3 com uma coluna adicional chamada match_id.
Os dados de origem usados por este tutorial é um arquivo chamado dblp_acm_records.csv. Esse arquivo é uma versão modificada de publicações acadêmicas (DBLP e ACM) disponíveis no Conjunto de dados de DBLP ACMdblp_acm_records.csv é um arquivo de valores separados por vírgula (CSV) no formato UTF-8 sem marca de ordem de bytes (BOM).
Um segundo arquivo, dblp_acm_labels.csv, é um exemplo de arquivo de rotulagem que contém registros correspondentes e não correspondentes usados para ensinar a transformação como parte do tutorial.
Tópicos
Etapa 1: rastrear os dados de origem
Primeiro, rastreie o arquivo CSV de origem do Amazon S3 para criar uma tabela de metadados correspondente no Data Catalog.
Importante
Para direcionar o crawler a criar uma tabela somente para o arquivo CSV, armazene os dados de origem do CSV em uma pasta do Amazon S3 separada de outros arquivos.
Faça login no AWS Management Console e abra o console do AWS Glue em https://console.aws.amazon.com/glue/
. -
No painel de navegação, escolha Crawlers, Add crawler (Adicionar crawler).
-
Siga o assistente para criar e executar um crawler chamado
demo-crawl-dblp-acmcom a saída para o banco de dadosdemo-db-dblp-acm. Ao executar o assistente, crie o banco de dados,demo-db-dblp-acmse ele ainda não existir. Escolha um caminho de inclusão do Amazon S3 para os dados de exemplo na região da AWS atual. Por exemplo, paraus-east-1, o caminho de inclusão do Amazon S3 para o arquivo de origem serás3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Se for bem-sucedido, o crawler criará a tabela
dblp_acm_records_csvcom as seguintes colunas: id, título, autores, local, ano e origem.
Etapa 2: adicionar uma transformação de machine learning
Em seguida, adicione uma transformação de machine learning que se baseia no esquema da tabela de fonte de dados criada pelo crawler chamado demo-crawl-dblp-acm.
-
No console do AWS Glue, no painel de navegação em Integração de dados e ETL, escolha Ferramentas de classificação de dados > Correspondência de registros e depois Adicionar transformação. Siga o assistente para criar uma transformação
Find matchescom as propriedades a seguir.-
Em Transform name (Nome da transformação), insira
demo-xform-dblp-acm. Este é o nome da transformação que é usada para localizar correspondências nos dados de origem. -
Em IAM role (Função do IAM), escolha uma função do IAM que tenha permissão para os dados de origem do Amazon S3, o arquivo de rotulagem e as operações da API do AWS Glue. Para obter mais informações, consulte Criar uma função do IAM para o AWS Glue no Guia do desenvolvedor do AWS Glue.
-
Em Data source (Fonte de dados), escolha a tabela chamada dblp_acm_records_csv no banco de dados demo-db-dblp-acm.
-
Em Primary key (Chave primária), escolha a coluna de chave primária da tabela id.
-
No assistente, escolha Finish (Concluir) e retorne à lista ML transforms (Transformações de ML).
Etapa 3: ensinar sua transformação de machine learning
Em seguida, você ensina sua transformação de machine learning usando o arquivo de rotulagem de exemplo do tutorial.
Não é possível usar uma transformação de linguagem de máquina em um trabalho de extração, transformação e carga (ETL) até que o status dela seja Ready for use (Pronta para uso). Para que sua transformação fique pronta, você deve ensiná-la como identificar registros correspondentes e não correspondentes fornecendo exemplos desses registros. Para ensinar a transformação, você pode Generate a label file (Gerar um arquivo de rótulos), adicionar rótulos e Upload label file (Fazer upload do arquivo de rótulos). Neste tutorial, você poderá usar o arquivo de rotulagem de exemplo chamado dblp_acm_labels.csv. Para obter mais informações sobre o processo de rotulagem, consulte Rótulo.
-
No console do AWS Glue, no painel de navegação, escolha Correspondência de registros.
-
Escolha a transformação
demo-xform-dblp-acme escolha Action (Ação), Teach (Ensinar). Siga o assistente para ensinar a transformaçãoFind matches. Na página de propriedades da transformação, escolha I have labels (Tenho rótulos). Escolha um caminho do Amazon S3 para o arquivo de rotulagem de exemplo na região da AWS atual. Por exemplo, para
us-east-1, faça upload do arquivo de rotulagem fornecido no caminho do Amazon S3s3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvcom a opção de overwrite (substituir) os rótulos existentes. O arquivo de rotulagem deve estar localizado no Amazon S3 na mesma região que o console do AWS Glue.Quando você faz upload de um arquivo de rotulagem, uma tarefa é iniciada no AWS Glue para adicionar ou substituir os rótulos usados para ensinar a transformação como processar a fonte de dados.
Na página final do assistente, escolha Finish (Concluir) e retorne à lista de ML transforms (Transformações de ML).
Etapa 4: estimar a qualidade de sua transformação de machine learning
É possível estimar a qualidade de sua transformação de machine learning. A qualidade depende da quantidade de rotulagem que você tiver feito. Para obter mais informações sobre como estimar a qualidade, consulte Estimar qualidade.
-
No console do AWS Glue, no painel de navegação em Integração de dados e ETL, escolha Ferramentas de classificação de dados > Correspondência de registros.
-
Escolha a transformação
demo-xform-dblp-acme escolha a guia Estimate quality (Estimar qualidade). Essa guia exibe as estimativas de qualidade atuais, se disponível, para a transformação. Escolha Estimate quality (Estimar qualidade) para iniciar uma tarefa para estimar a qualidade da transformação. A precisão da estimativa da qualidade é baseada na rotulagem dos dados de origem.
Navegue até a guia History (Histórico). Nesse painel, estão listadas as execuções de tarefa para a transformação, incluindo a tarefa Estimating quality (Estimar qualidade). Para obter mais detalhes sobre a execução, escolha Logs. Verifique se o status da execução é Succeeded (Bem-sucedido) após a conclusão.
Etapa 5: adicionar e executar um trabalho com sua transformação de machine learning
Nesta etapa, você usará a transformação de machine learning para adicionar e executar um trabalho no AWS Glue. Quando a transformação demo-xform-dblp-acm estiver Ready for use (Pronta para uso), você poderá usá-la em um trabalho de ETL.
-
No console do AWS Glue, no painel de navegação, escolha Jobs (Trabalhos).
-
Escolha Add job (Adicionar trabalho), e siga as etapas do assistente para criar um trabalho de ETL do Spark com um script gerado. Escolha os seguintes valores de propriedade para sua transformação:
-
Em Name (Nome), escolha o trabalho de exemplo neste tutorial, demo-etl-dblp-acm.
-
Em IAM role (Função do IAM), escolha uma função do IAM com permissão para os dados de origem do Amazon S3, o arquivo de rotulagem e as operações da API do AWS Glue. Para obter mais informações, consulte Criar uma função do IAM para o AWS Glue no Guia do desenvolvedor do AWS Glue.
-
Em ETL language (Linguagem de ETL), escolha Scala. Esta será a linguagem de programação no script de ETL.
-
Em Script file name (Nome do arquivo de script), escolha demo-etl-dblp-acm. Este é o nome do arquivo do script Scala (igual ao nome do trabalho).
-
Em Data source (Fonte de dados), escolha dblp_acm_records_csv. A fonte de dados que você escolher deve corresponder ao esquema da fonte de dados da transformação de machine learning.
-
Em Transform type (Tipo de transformação), escolha Find matching records (Encontrar registros correspondentes) para criar um trabalho usando uma transformação de machine learning.
-
Desmarque Remove duplicate records (Remover registros duplicados). Não remova os registros duplicados porque os registros de saída de gravados têm um campo extra
match_idadicionado. -
Em Transform (Transformação), escolha a transformação de machine learning demo-xform-dblp-acm usada pelo trabalho.
-
Em Create tables in your data target (Criar tabelas em seu destino de dados), escolha criar tabelas com as seguintes propriedades:
-
Data store type (Tipo de armazenamento de dados):
Amazon S3 -
Format (Formato):
CSV -
Compression type (Tipo de compactação):
None -
Target path (Caminho de destino): o caminho do Amazon S3 onde a saída do trabalho é gravada (no console da região da AWS atual)
-
-
-
Escolha Save job and edit script (Salvar trabalho e editar script) para exibir a página do editor de script.
-
Edite o script para adicionar uma instrução para fazer com que a saída do trabalho para o Target path (Caminho de destino) seja gravado em um único arquivo de partição. Adicione essa instrução imediatamente após a instrução que executa a transformação
FindMatches. A instrução é semelhante ao seguinte.val single_partition = findmatches1.repartition(1)Você deve modificar a instrução
.writeDynamicFrame(findmatches1)para gravar a saída como.writeDynamicFrame(single_partion). -
Depois de editar o script, escolha Save (Salvar). O script modificado é similar ao código a seguir, mas personalizado para seu ambiente.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Escolha Run job (Executar trabalho) para iniciar a execução do trabalho. Verifique o status do trabalho na lista de trabalhos. Quando o trabalho terminar, em ML transform (Transformação de ML), guia History (Histórico), haverá uma nova linha adicionada Run ID (ID de execução) do tipo ETL job (Trabalho de ETL).
Navegue até Jobs (Trabalhos), guia History (Histórico). Nesse painel, estão listadas as execuções de trabalho. Para obter mais detalhes sobre a execução, escolha Logs. Verifique se o status da execução é Succeeded (Bem-sucedido) após a conclusão.
Etapa 6: verificar os dados de saída do Amazon S3
Nesta etapa, verifique a saída da execução do trabalho no bucket do Amazon S3 que você escolheu quando adicionou o trabalho. Você pode fazer download do arquivo de saída em sua máquina local e verificar se os registros correspondentes foram identificados.
Abra o console do Amazon S3 em https://console.aws.amazon.com/s3/
. Faça download do arquivo de saída de destino do trabalho
demo-etl-dblp-acm. Abra o arquivo em um aplicativo de planilha (talvez seja necessário adicionar uma extensão de arquivo.csvpara que o arquivo abra corretamente).A imagem a seguir mostra um trecho da saída no Microsoft Excel.
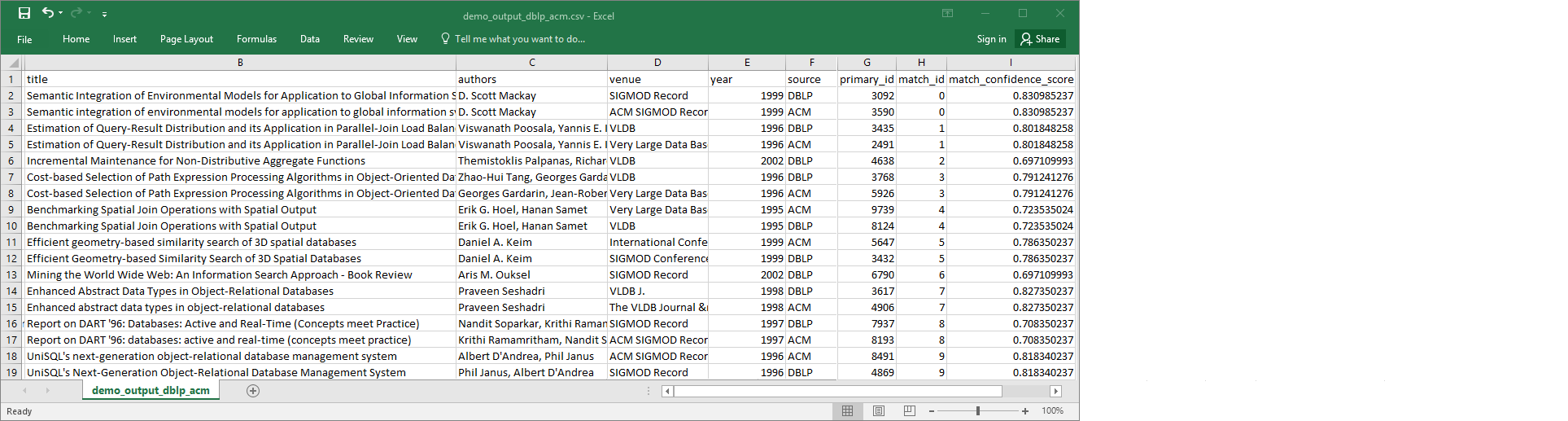
O arquivo da fonte de dados e o arquivo do destino têm 4.911 registros. No entanto, a transformação
Find matchesadiciona outra coluna chamadamatch_idpara identificar registros correspondentes na saída. As linhas com o mesmomatch_idsão consideradas registros correspondentes. Omatch_confidence_scoreé um número entre 0 e 1 que fornece uma estimativa da qualidade das correspondências encontradas porFind matches.-
Classifique o arquivo de saída por
match_idpara ver facilmente quais registros são correspondentes. Compare os valores nas outras colunas para ver se você concorda com os resultados da transformaçãoFind matches. Se você não concordar, poderá continuar a ensinar a transformação adicionando mais rótulos.Também é possível classificar o arquivo por outro campo, como
title, para ver se os registros com títulos semelhantes têm o mesmomatch_id.
