Avaliar a qualidade dos dados para trabalhos de ETL no AWS Glue Studio
Neste tutorial, você começa a usar o AWS Glue Data Quality no AWS Glue Studio. Você aprenderá a fazer o seguinte:
-
Criar regras usando o compilador de regras da Data Quality Definition Language (DQDL).
-
Especificar ações de qualidade de dados, dados a serem produzidos e o local de saída dos resultados de qualidade de dados.
-
Analisar os resultados de qualidade dos dados.
Para praticar com um exemplo, revise a postagem do blog Getting started with AWS Glue Data Quality for ETL pipelines
Etapa 1: adicionar o nó de transformação Evaluate Data Quality à tarefa visual
Nesta etapa, você adiciona o nó Evaluate Data Quality à tarefa visual
Para adicionar o nó de qualidade de dados
-
No console Glue Studio do AWS, escolha Visual com origem e destino na seção Criar tarefa e, em seguida, escolha Criar.
-
Escolha um nó ao qual você deseja aplicar a transformação de qualidade de dados. Normalmente, isso será um nó de transformação ou uma fonte de dados.
-
Abra o painel de recursos à esquerda escolhendo o ícone “+”. Em seguida, procure Evaluate Data Quality na barra de pesquisa e escolha Evaluate Data Quality nos resultados da pesquisa.
-
O editor visual de tarefas mostrará a ramificação do nó de transformação Evaluate Data Quality a partir do nó selecionado. No lado direito do console, a guia Transform (Transformar) é aberta automaticamente. Se você precisar alterar o nó principal, escolha a guia Propriedades do nó e, em seguida, escolha o nó principal no menu suspenso.
Quando você escolhe um novo nó principal, uma nova conexão é feita entre o nó superior e o nó Evaluate Data Quality (Avaliar qualidade dos dados). Remova todos os nós principais indesejados. Somente um nó principal pode ser conectado a um nó Evaluate Data Quality.
-
A transformação Evaluate Data Quality oferece suporte a vários pais para que você possa validar as regras de qualidade de dados em vários conjuntos de dados. As regras que oferecem suporte a vários conjuntos de dados incluem ReferentialIntegrity, DatasetMatch, SchemaMatch, RowCountMatch e AggregateMatch.
Ao adicionar várias entradas à transformação Evaluate Data Quality, você precisa selecionar sua entrada “primária”. Sua entrada principal é o conjunto de dados para o qual você deseja validar a qualidade dos dados. Todos os outros nós ou entradas são tratados como referências.
Você pode usar a transformação Evaluate Data Quality para identificar registros específicos que falharam nas verificações de qualidade dos dados. Recomendamos que você escolha seu conjunto de dados principal porque novas colunas que sinalizam registros incorretos são adicionadas ao conjunto de dados primário.
-
Você pode especificar aliases para fontes de dados de entrada. Os aliases fornecem outra forma de referenciar a fonte da entrada quando você está usando a regra ReferentialIntegrity. Como somente uma fonte de dados pode ser designada como fonte primária, cada fonte de dados adicional adicionada exigirá um alias.
No exemplo a seguir, a regra ReferentialIntegrity especifica a fonte de dados de entrada pelo nome do alias e realiza uma comparação individual com a fonte de dados primária.
Rules = [ ReferentialIntegrity “Aliasname.name” = 1 ]
Etapa 2: criar uma regra usando DQDL
Nesta etapa, você cria uma regra usando DQDL. Para este tutorial, você criará uma única regra usando o tipo de regra Completeness. Esse tipo de regra verifica a porcentagem de valores completos (não nulos) em uma coluna em relação a uma determinada expressão. Para obter mais informações sobre o uso de DQDL, consulte DQDL.
-
Na guia Transformar, adicione um tipo de regra clicando no botão Inserir. Isso adiciona o tipo de regra ao editor de regras, onde você pode inserir os parâmetros da regra.
nota
Ao editar regras, verifique se as regras estão entre colchetes e certifique-se de que as regras estejam separadas por vírgulas. Por exemplo, uma expressão de regra completa terá a seguinte aparência:
Rules= [ Completeness "year">0.8, Completeness "month">0.8 ]Este exemplo especifica o parâmetro de completude para as colunas denominadas 'ano' e 'mês'. Para que a regra seja aprovada, essas colunas devem estar mais de 80% 'completas' ou ter dados em mais de 80% das instâncias para cada coluna respectiva.
Neste exemplo, pesquise e insira o tipo de regra Completeness (Completude). Isso adiciona o tipo de regra ao editor de regras. Esse tipo de regra tem a seguinte sintaxe:
Completeness <COL_NAME> <EXPRESSION>.A maioria dos tipos de regras exige que você forneça uma expressão como parâmetro para criar uma resposta booleana. Para obter mais informações sobre expressões DQDL compatíveis, consulte Expressões DQDL. Em seguida, você adicionará o nome da coluna.
-
No compilador de regras DQDL, clique na guia Esquema. Use a barra de pesquisa para localizar o nome da coluna no esquema de entrada. O esquema de entrada exibe o nome da coluna e o tipo de dados.
-
No editor de regras, clique à direita do tipo de regra para inserir o cursor onde a coluna será inserida. Como alternativa, você pode digitar o nome da coluna na regra.
Por exemplo, na lista de colunas na lista de esquemas de entrada, clique no botão Inserir ao lado da coluna (neste exemplo, ano). Isso adicionará a coluna à regra.
-
Em seguida, no editor de regras, adicione uma expressão para avaliar a regra. Como o tipo de regra Completeness verifica a porcentagem de valores completos (não nulos) em uma coluna em relação a uma determinada expressão, insira uma expressão como
> 0.8. Essa regra verificará se a coluna tem mais de 80% de valores completos (não nulos).
Etapa 3: configurar saídas de qualidade de dados
Depois de criar regras de qualidade de dados, você pode selecionar opções adicionais para especificar a saída do nó de qualidade de dados.
-
Em Data quality transform output (Saída de transformação de qualidade de dados), escolha uma das seguintes opções:
-
Original data: escolha para saída dos dados de entrada originais. Quando você escolhe essa opção, um novo nó filho “rowLevelOutcomes” é adicionado ao trabalho. O esquema corresponde ao esquema do conjunto de dados primário que foi passado como entrada para a transformação. Essa opção é útil se você quiser apenas transmitir os dados e rejeitar o trabalho quando ocorrerem problemas de qualidade.
Outro caso de uso é quando você deseja detectar registros incorretos que falharam nas verificações de qualidade dos dados. Para detectar registros incorretos, escolha a opção Adicionar novas colunas para indicar erros na qualidade dos dados. Essa ação adiciona quatro novas colunas ao esquema da transformação “rowLevelOutcomes”.
-
DataQualityRulesPass (matriz de strings): Fornece uma matriz de regras que passaram pelas verificações de qualidade dos dados.
-
DataQualityRulesFail (matriz de strings): Fornece uma matriz de regras que foram reprovadas pelas verificações de qualidade dos dados.
-
DataQualityRulesSkip (matriz de strings): Fornece uma matriz de regras que foram ignoradas. As regras a seguir não podem identificar registros de erro porque são aplicadas no nível do conjunto de dados.
-
AggregateMatch
-
ColumnCount
-
ColumnExists
-
ColumnNamesMatchPattern
-
CustomSql
-
RowCount
-
RowCountMatch
-
StandardDeviation
-
Média
-
ColumnCorrelation
-
-
DataQualityEvaluationResult: fornece o status “Aprovado” ou “Falha” no nível da linha. Observe que seu resultado geral pode ser FALHA, mas um determinado registro pode ser aprovado. Por exemplo, a regra RowCount pode ter falhado, mas todas as outras regras podem ter sido bem-sucedidas. Nesses casos, o status desse campo é “Aprovado”.
-
-
-
Resultados de qualidade dos dados: opte pela saída das regras configuradas e seu status de aprovação ou reprovação. Essa opção é útil se você quiser gravar seus resultados no Amazon S3 ou em outros bancos de dados.
-
Configurações de saída de qualidade de dados (Opcional): escolha Configurações de saída de qualidade de dados para revelar o campo Local do resultado da qualidade de dados. Em seguida, clique em Procurar para procurar um local do Amazon S3 para definir como objetivo de saída de qualidade de dados.
Etapa 4: Configurar ações de qualidade de dados
Você pode usar ações para publicar métricas do CloudWatch ou para interromper trabalhos com base em critérios específicos. As ações só estarão disponíveis depois que você criar uma regra. Quando você escolhe essa opção, as mesmas métricas também são publicadas no Amazon EventBridge. Você pode usar essas opções para criar alertas para notificação.
-
Em caso de falha no conjunto de regras: você pode escolher o que fazer se um conjunto de regras falhar durante a execução do trabalho. Se você quiser que o trabalho falhe se a qualidade dos dados falhar, escolha quando o trabalho deve falhar selecionando uma das opções a seguir. Por padrão, essa ação não é selecionada e a tarefa concluirá sua execução mesmo se as regras de qualidade de dados falharem.
-
Nenhum: se você escolher Nenhum (padrão), o trabalho não falhará e continuará sendo executado apesar das falhas no conjunto de regras.
-
Falha na tarefa após carregar os dados no destino: a tarefa falha e nenhum dado é salvo. Para salvar os resultados, escolha um local do Amazon S3 onde os resultados de qualidade dos dados serão salvos.
-
Falha na tarefa sem carregar os dados de destino: essa opção causa falha na tarefa imediatamente quando ocorre um erro de qualidade de dados. Ela não carrega nenhum destino de dados, incluindo os resultados da transformação da qualidade dos dados.
-
Etapa 5: visualizar os resultados de qualidade dos dados
Depois de executar o trabalho, visualize os resultados de qualidade dos dados clicando na guia Qualidade dos dados.
-
Para cada trabalho executado, veja os resultados de qualidade dos dados. Cada nó exibe um status de qualidade de dados e detalhes de status. Clique em um nó para ver todas as regras e o status de cada regra.
-
Escolha Baixar resultados para baixar um arquivo CSV que contém informações sobre a execução do trabalho e os resultados da qualidade dos dados.
-
Se você tiver mais de uma execução de trabalho com resultados de qualidade de dados, poderá filtrar os resultados por intervalo de data e hora. Clique em Filtrar por um intervalo de data e hora para expandir a janela do filtro.
-
É possível escolher entre intervalo relativo e intervalo absoluto. Para intervalos absolutos, use o calendário para selecionar uma data e insira valores para hora de início e hora de término. Após terminar, escolha Aplicar.
Qualidade de dados automática
Quando você cria um trabalho de ETL do AWS Glue com o Amazon S3 como destino, o ETL do AWS Glue habilita automaticamente uma regra de qualidade de dados que verifica se os dados que estão sendo carregados têm pelo menos uma coluna. Essa regra foi desenvolvida para garantir que os dados que estão sendo carregados não estejam vazios ou corrompidos. No entanto, se essa regra falhar, o trabalho não falhará; em vez disso, você notará uma redução no seu índice de qualidade de dados. Além disso, a detecção de anomalias é ativada por padrão e monitora o número de colunas nos dados. Se houver alguma variação ou anormalidade na contagem de colunas, o ETL do AWS Glue informará você sobre essas anomalias. Esse recurso ajuda você a identificar possíveis problemas com os dados e a tomar as medidas apropriadas. Para visualizar a regra de qualidade de dados e sua configuração, é possível clicar no destino do Amazon S3 em seu trabalho de ETL do AWS Glue. A configuração da regra será exibida, conforme mostrado na captura de tela fornecida.
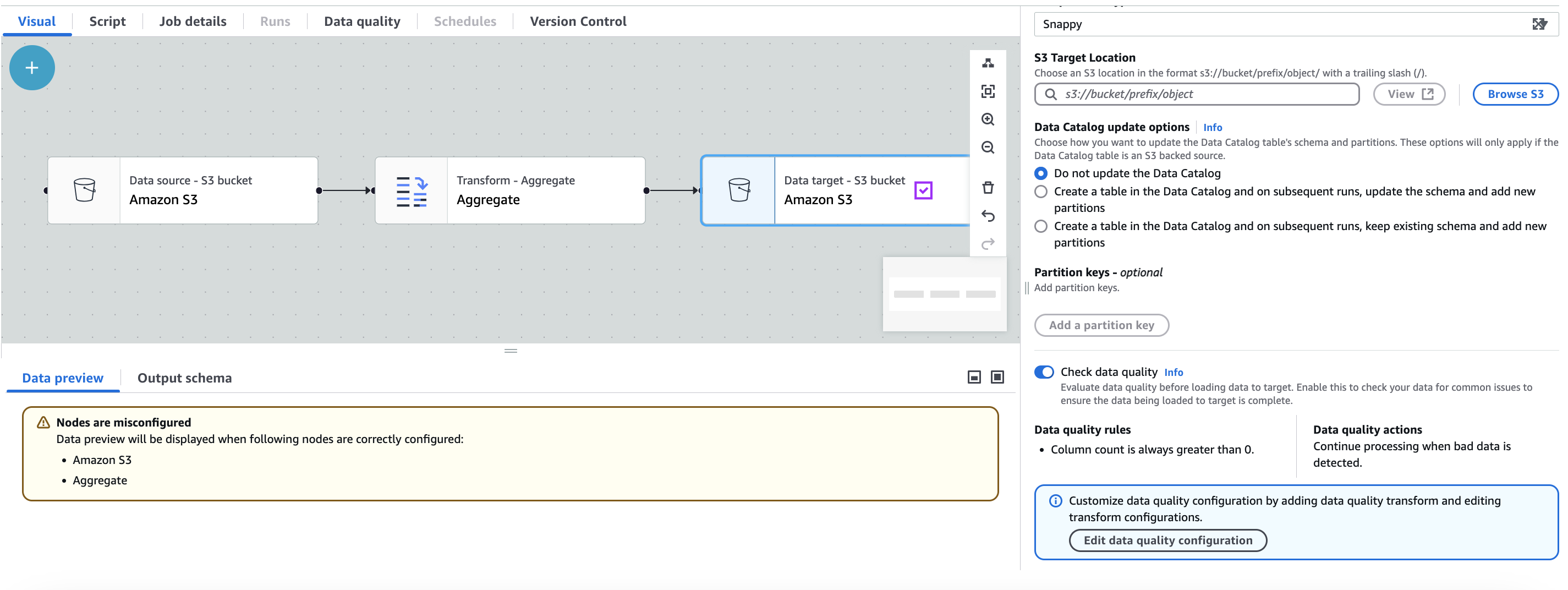
Você pode adicionar outras regras de qualidade de dados selecionando Editar configuração de qualidade de dados.
Métricas agregadas
Você pode exigir métricas agregadas, como o número de registros aprovados, reprovados ou ignorados no nível da regra ou no nível do conjunto de regras para criar painéis. Para obter as métricas agregadas e as métricas de regras para cada regra, primeiro habilite as métricas agregadas adicionando a opção publishAggregatedMetrics à sua função EvaluateDataQuality.
As opções possíveis para additional_options publishAggregatedMetrics são ENABLED e DISABLED. Exemplo:
EvaluateDataQualityMultiframe = EvaluateDataQuality().process_rows( frame=medicare_dyf, ruleset=EvaluateDataQuality_ruleset, publishing_options={ "dataQualityEvaluationContext": "EvaluateDataQualityMultiframe", "enableDataQualityCloudWatchMetrics": False, "enableDataQualityResultsPublishing": False, }, additional_options={"publishAggregatedMetrics.status": "ENABLED"}, )
Se não for especificado, o publishAggregatedMetrics.status é DISABLED por padrão, e as ruleMetrics e as métricas agregadas agora serão computadas. Esse atributo é atualmente suportado nas sessões interativas do AWS Glue e nas tarefas de ETL do Glue. Isso não é suportado nas APIs do Glue Catalog Data Quality.
Recuperar resultados de métricas agregadas
Quando additionalOptions for "publishAggregatedMetrics.status": "ENABLED", você poderá obter os resultados em dois lugares:
-
AggregatedMetricseRuleMetricssão retornados por meio doGetDataQualityResult()ao fornecer oresultIdondeAggregatedMetricseRuleMetricsincluem:Métricas agregadas:
Total de linhas processadas
Total de linhas processadas
Total de linhas com falha
Total de regras processadas
Total de regras aprovadas
Total de regras com falha

Além disso, no nível da regra, as seguintes métricas são fornecidas:
Métricas de regra:
Linhas aprovadas
Linhas com falha
Linha ignorada
Total de linhas processadas
-
AggregatedMetricsé retornado como um quadro de dados adicional e o quadro de dadosRuleOutcomesé aumentado para incluirRuleMetrics.
Exemplos de implementação
O exemplo a seguir mostra como implementar métricas agregadas no Scala:
// Script generated for node Evaluate Data Quality val EvaluateDataQuality_node1741974822533_ruleset = """ # Example rules: Completeness "colA" between 0.4 and 0.8, ColumnCount > 10 Rules = [ IsUnique "customer_identifier", RowCount > 10, Completeness "customer_identifier" > 0.5 ] """ val EvaluateDataQuality_node1741974822533 = EvaluateDataQuality.processRows(frame=ChangeSchema_node1742850392012, ruleset=EvaluateDataQuality_node1741974822533_ruleset, publishingOptions=JsonOptions("""{"dataQualityEvaluationContext": "EvaluateDataQuality_node1741974822533", "enableDataQualityCloudWatchMetrics": "true", "enableDataQualityResultsPublishing": "true"}"""), additionalOptions=JsonOptions("""{"compositeRuleEvaluation.method":"ROW","observations.scope":"ALL","performanceTuning.caching":"CACHE_NOTHING", "publishAggregatedMetrics.status": "ENABLED"}""")) println("--------------------------------ROW LEVEL OUTCOMES--------------------------------") val rowLevelOutcomes_node = EvaluateDataQuality_node1741974822533("rowLevelOutcomes") rowLevelOutcomes_node.show(10) println("--------------------------------RULE LEVEL OUTCOMES--------------------------------") val ruleOutcomes_node = EvaluateDataQuality_node1741974822533("ruleOutcomes") ruleOutcomes_node.show() println("--------------------------------AGGREGATED METRICS--------------------------------") val aggregatedMetrics_node = EvaluateDataQuality_node1741974822533("aggregatedMetrics") aggregatedMetrics_node.show()
Exemplos de resultados
Os resultados são retornados da seguinte forma:
{ "Rule": "IsUnique \"customer_identifier\"", "Outcome": "Passed", "FailureReason": null, "EvaluatedMetrics": { "Column.customer_identifier.Uniqueness": 1 }, "EvaluatedRule": "IsUnique \"customer_identifier\"", "PassedCount": 10, "FailedCount": 0, "SkippedCount": 0, "TotalCount": 10 } { "Rule": "RowCount > 10", "Outcome": "Failed", "FailureReason": "Value: 10 does not meet the constraint requirement!", "EvaluatedMetrics": { "Dataset.*.RowCount": 10 }, "EvaluatedRule": "RowCount > 10", "PassedCount": 0, "FailedCount": 0, "SkippedCount": 10, "TotalCount": 10 } { "Rule": "Completeness \"customer_identifier\" > 0.5", "Outcome": "Passed", "FailureReason": null, "EvaluatedMetrics": { "Column.customer_identifier.Completeness": 1 }, "EvaluatedRule": "Completeness \"customer_identifier\" > 0.5", "PassedCount": 10, "FailedCount": 0, "SkippedCount": 0, "TotalCount": 10 }
As métricas agregadas são as seguintes:
{ "TotalRowsProcessed": 10, "PassedRows": 10, "FailedRows": 0, "TotalRulesProcessed": 3, "RulesPassed": 2, "RulesFailed": 1 }
