Data Collection without AWS Organizations
When deploying AWS Cost Intelligence Dashboard (CID), customers who don’t have direct access to AWS Organizations (because it’s managed by partners or separate internal teams) should first consider collaborating with the team owning AWS Management (Payer) Account to deploy CID at scale across the organization with Row Level Security implemented, ensuring each business unit can only view cost and operational data for their specific AWS accounts.
However, if collaboration with the Management account team isn’t feasible due to organizational constraints, customers can still deploy multiple CID dashboards independently without requiring AWS Organizations access, providing flexibility even without centralized organizational visibility.
Following dashboards are available without access to AWS Organization:
| Dashboard | Requirement | Details |
|---|---|---|
|
CUDOS, CID, KPI |
Data Exports |
CUR |
|
SPG Marketplace |
Data Exports |
CUR |
|
Sustainability |
Data Exports |
CUR, Carbon |
|
CORA |
Data Exports |
COH |
|
Amazon Connect Cost Insights Dashboard |
Data Exports |
CUR |
|
Trusted Advisor |
Data Collection |
Trusted Advisor Module |
|
Support Cases Radar |
Data Collection |
Support Cases Module |
|
Extended Support Cost Projection |
Data Collection |
Inventory Module |
|
Graviton Savings Dashboard |
Data Collection |
Inventory and Pricing Modules |
|
AWS News Feeds |
Data Collection |
AWS Feeds Module |
Following Dashboards are not available without access to AWS Organization:
-
Health Events Dashboards, Compute Optimizer Dashboards, Anomaly Detection Dashboard, AWS Budgets Dashboard
Data Exports without AWS Organizations
Foundational dashboards like CUDOS, CID, and KPI are only depend on AWS Cost and Usage report in AWS Data Exports. Also CORA and FOCUS depend on Cost Optimization Hub and Focus reports respectively.
Using CID Data Exports stack you can deploy AWS Data Exports in a set of AWS Account, and using replication consolidate all data in one of accounts called Data Collection Account for deploying of Dashboards.
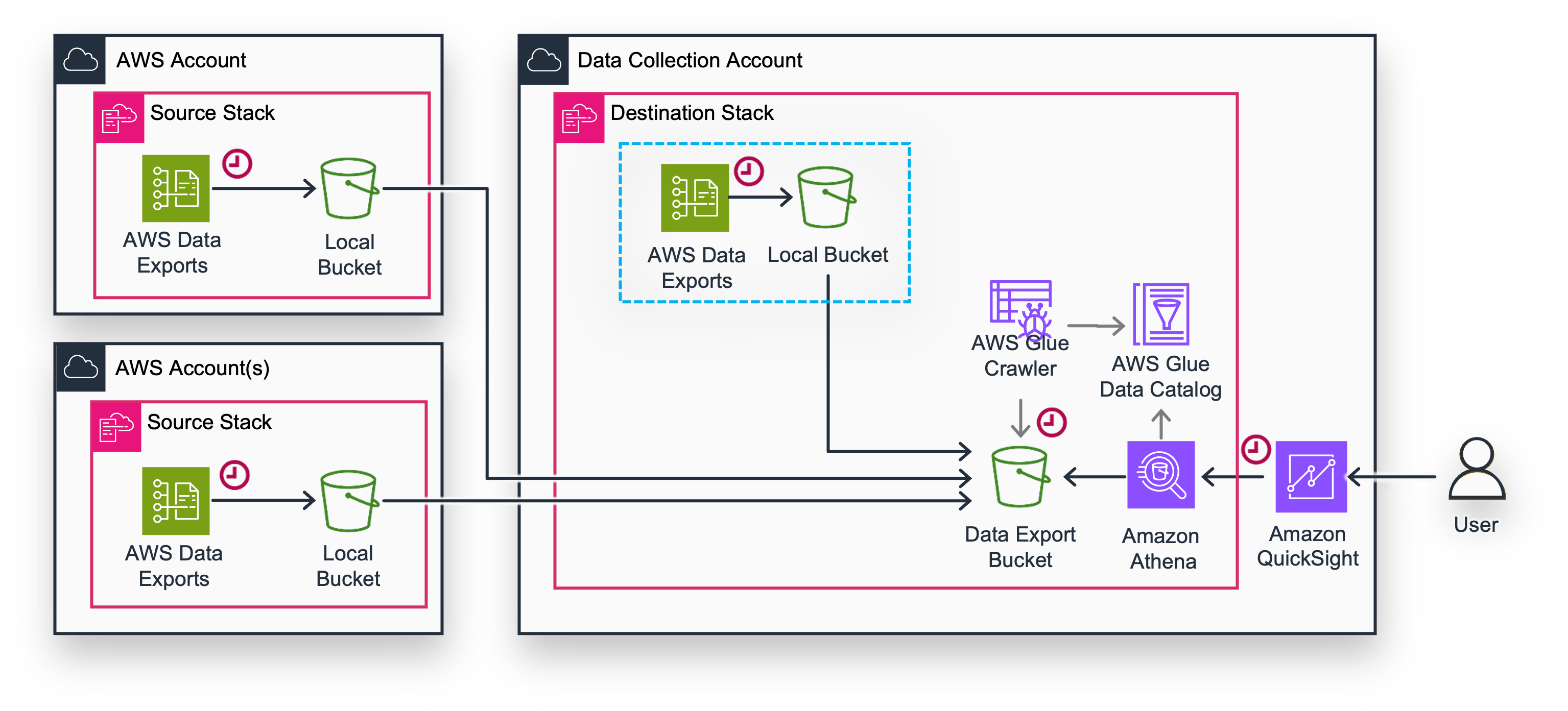
Please follow the instructions in Data Exports and first install the Stack with Destination parameters in the Data Collection account. Please Note that in order to get data for the Data Collection itself you need to put the AWS Account of Data Collection Account in the list of SourceAccountIds as FIRST, and then you can add all other Account Ids that will later transfer their Data Exports here.
Once done you can go ahead and install the Stack with only Source parameters in each AWS Account of your perimeter. (you need to specify Destination Account Id and keep Source Account Ids as empty). Do not forget to set the exports you need on both sides.
Data Collection without AWS Organizations
By default, the Data Collection tooling uses AWS Organizations to obtain a list of accounts in scope for the modules that collect information at the Linked Account level. However, in some cases, business or governance policies may limit access to AWS Organizations. This guide shows you how to manually define a list of specific Linked Accounts to poll directly, rather than relying on the AWS Organizations API.
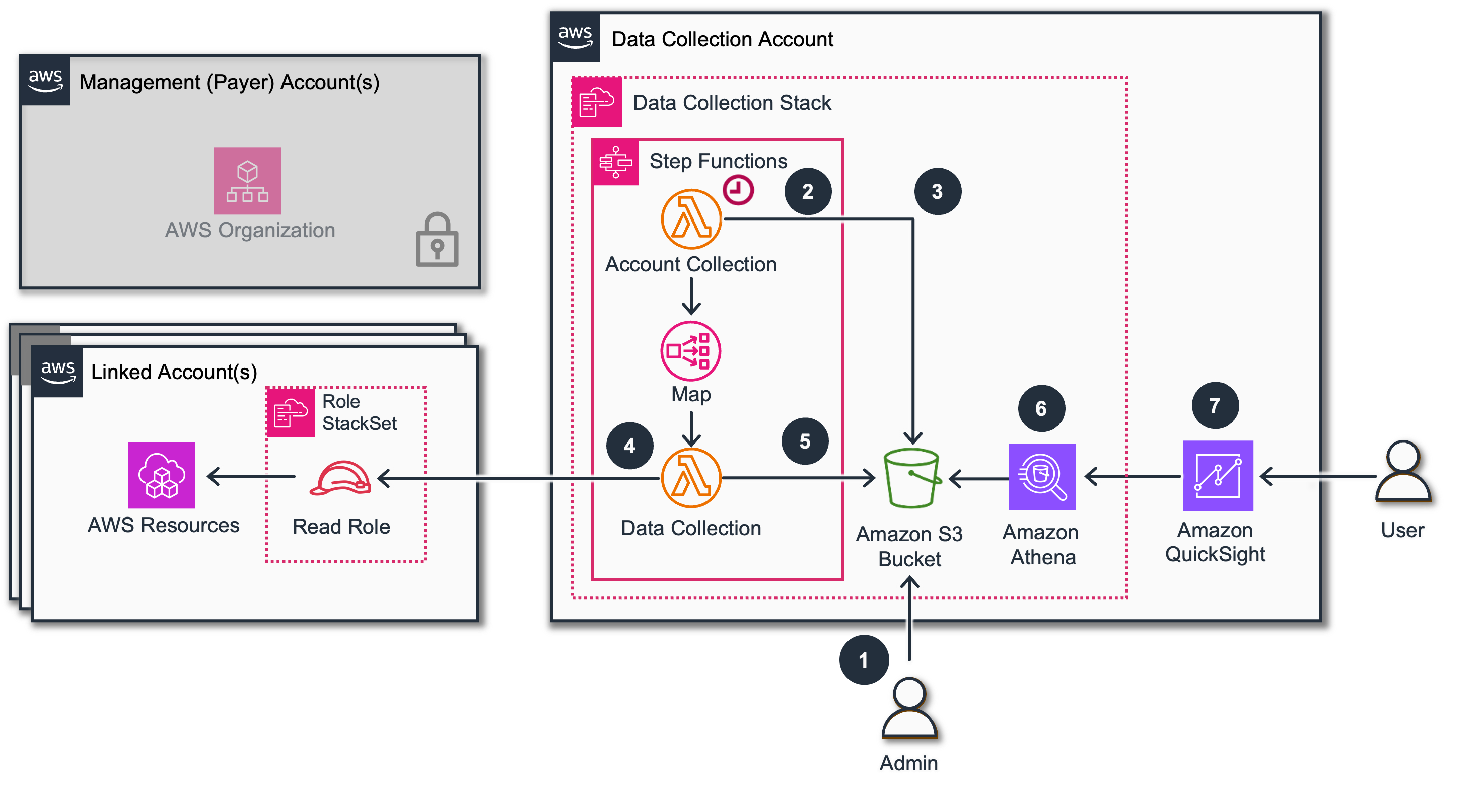
-
An administrator user uploads a list of accounts to S3 bucket (can be easily automated).
-
A scheduled event trigger an execution of Lambda Function. By default every 14 days.
-
The Account Collection Lambda can detect an account list on s3 bucket.
-
The data collection Lambda goes to each account and assume the role to read the information
-
The Lambda Stores collected data to S3
-
Customer can query tables via Athena
-
or deploy Quicksight Dashboards on top of these data.
To enable data collection you must first ensure that the deploy-in-linked-account.yaml
Note, not all Data Collection modules will work without AWS Organizations. The following modules are supported:
-
Inventory
-
ECS Chargeback
-
RDS Usage
-
Transit Gateway
-
Trusted Advisor
-
Support Cases
Step by Step Guide
-
If you have not done so already, deploy the permissions stack
into each Linked Account in scope. You should adjust the template parameters to choose the modules you wish to use, using the list of supported modules above. -
Follow Step 2 of the standard Data Collection deployment to deploy the Data Collection tooling. Select the same modules that you selected with your permissions stack deployment.
-
Create either a JSON or CSV file with your Linked Account information. For either format, declare each account as on a separate line, per the following examples. Note there is no header row for the CSV but the order is the same as the JSON:
account_id, account_name, payer_id. Name the fileaccount-list.jsonoraccount-list.csvaccordingly.JSON:
{"account_id": "111111111111", "account_name": "My account 1", "payer_id": "999999999999"} {"account id": "222222222222", "account name": "My account 2", "payer id": "999999999999"}CSV:
111111111111,My account 1,999999999999 222222222222,My account 2,999999999999
-
Locate the main bucket created by the Data Collection stack. The default is
cid-data-[YOUR ACCOUNT NUMBER]. Create a folder off of the root and name itaccount-list. Then deploy the file you created to that folder. The framework will detect the existence of the file when it next runs and use it instead of AWS Organizations for the affected modules. The bucket path should look like something likecid-data-111111111111/account-list/account-list.csv. -
Now you can trigger StepFunctions for data collection (Search TrustedAdvisor, locate the StepFunction and launch execution without any specific parameter needed).
-
When StepFunction completed you can check the data in Athena and proceed to deployment of dashboards.
