As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Processo de migração off-line: Apache Cassandra para Amazon Keyspaces
As migrações off-line são adequadas para quando é possível permitir tempo de inatividade para realizar a migração. É comum entre as empresas ter janelas de manutenção para patches, grandes lançamentos ou tempo de inatividade para atualizações de hardware ou atualizações importantes. A migração off-line pode usar essa janela para copiar dados e transferir o tráfego do aplicativo do Apache Cassandra para o Amazon Keyspaces.
A migração off-line reduz as modificações no aplicativo porque não exige comunicação simultânea com o Cassandra e o Amazon Keyspaces. Além disso, com o fluxo de dados pausado, o estado exato pode ser copiado sem manter as mutações.
Neste exemplo, usamos o Amazon Simple Storage Service (Amazon S3) como uma área de preparação de dados durante a migração off-line para minimizar o tempo de inatividade. Você pode importar automaticamente os dados armazenados no formato Parquet no Amazon S3 em uma tabela do Amazon Keyspaces usando o conector Spark Cassandra e AWS Glue. Veja a seção a seguir uma visão geral de alto nível do processo. Você pode encontrar exemplos de código para esse processo no Github.
O processo de migração offline do Apache Cassandra para o Amazon Keyspaces usando o Amazon S3 requer os seguintes trabalhos. AWS Glue AWS Glue
Um trabalho de ETL que extrai e transforma dados de CQL e os armazena em um bucket do Amazon S3.
Um segundo trabalho que importa os dados do bucket para o Amazon Keyspaces.
Um terceiro trabalho para importar dados incrementais.
Como realizar uma migração off-line do Cassandra para o Amazon Keyspaces em execução na Amazon EC2 em uma Amazon Virtual Private Cloud
Primeiro, você pode AWS Glue exportar dados da tabela do Cassandra no formato Parquet e salvá-los em um bucket do Amazon S3. Você precisa executar um AWS Glue trabalho usando um AWS Glue conector para uma VPC onde reside a EC2 instância da Amazon que executa o Cassandra. Em seguida, usando o endpoint privado do Amazon S3, você pode salvar dados no bucket do Amazon S3.
O diagrama a seguir ilustra essas etapas:
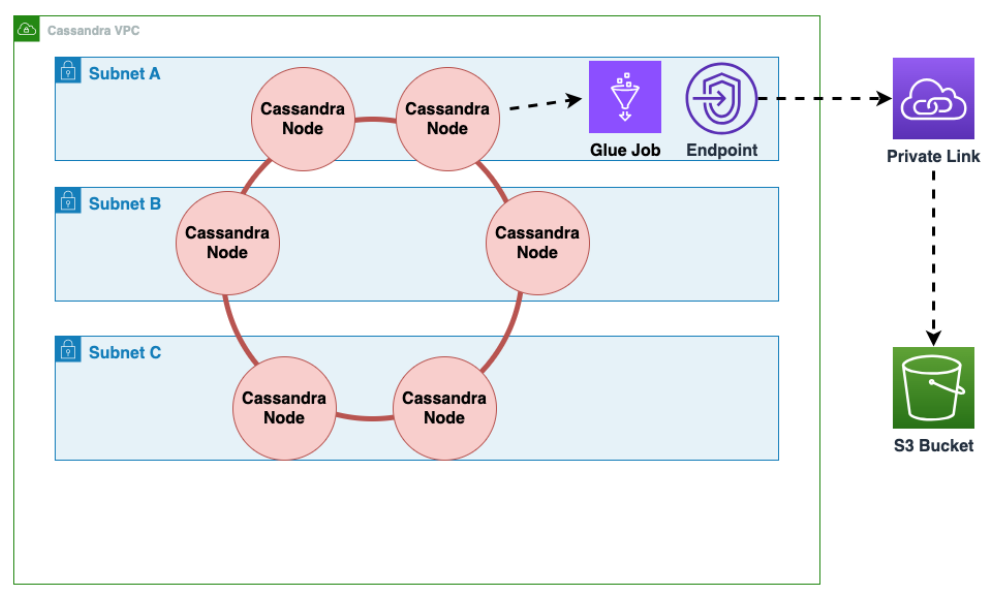
Embaralhe os dados no bucket do Amazon S3 para melhorar a randomização de dados. Dados importados uniformemente permitem um tráfego mais distribuído na tabela de destino.
Essa etapa é necessária ao exportar dados do Cassandra com partições grandes (partições com mais de 1000 linhas) para evitar padrões de teclas de atalho ao inserir os dados no Amazon Keyspaces. Problemas com teclas de atalho causam
WriteThrottleEventsno Amazon Keyspaces e resultam em maior tempo de carregamento.
Use outro AWS Glue trabalho para importar dados do bucket do Amazon S3 para o Amazon Keyspaces. Os dados embaralhados no bucket do Amazon S3 são armazenados no formato Parquet.

Para obter mais informações sobre o processo de migração off-line, consulte o workshop Amazon Keyspaces with AWS Glue
