Não estamos mais atualizando o serviço Amazon Machine Learning nem aceitando novos usuários para ele. Essa documentação está disponível para usuários existentes, mas não estamos mais atualizando-a. Para obter mais informações, consulte O que é o Amazon Machine Learning.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Insights do modelo de regressão
Interpretação das previsões
A saída de um modelo de ML de regressão é um valor numérico para a previsão de destino do modelo. Por exemplo, se você estiver prevendo preços de imóveis residenciais, a previsão do modelo pode ser um valor como 254.013.
nota
O intervalo de previsões pode ser diferente do intervalo do destino nos dados de treinamento. Por exemplo, digamos que você esteja prevendo os preços de imóveis residenciais e o destino nos dados de treinamento tenha valores entre 0 e 450.000. O destino previsto não precisa estar no mesmo intervalo e pode aceitar qualquer valor positivo (maior do que 450.000) ou negativo (menor do que zero). É importante planejar como abordar os valores de previsão que ficam fora de um intervalo aceitável para seu aplicativo.
Medição da precisão do modelo de ML
Para tarefas de regressão, o Amazon ML usa a métrica de raiz do erro quadrático médio do setor (RMSE). Ele é uma medida de distância entre o destino numéricos previsto e a resposta numérica real (verdade). Quanto menor o valor do RMSE, melhor será a precisão preditiva do modelo. Um modelo com previsões perfeitamente corretas teria um RMSE igual a 0. O exemplo a seguir mostra os dados de avaliação que contêm N registros:

RMSE de referência
O Amazon ML fornece uma métrica de referência para modelos de regressão. Ela é o RMSE de um modelo de regressão hipotética que sempre prevê a média do destino como a resposta. Por exemplo, se você estiver prevendo a idade dos compradores de imóveis e a idade média das observações em seus dados de treinamento for 35, o modelo de referência sempre preverá a resposta como 35. Compare seu modelo de ML com essa referência para validar se o seu modelo de ML é melhor do que um modelo que prevê essa resposta constante.
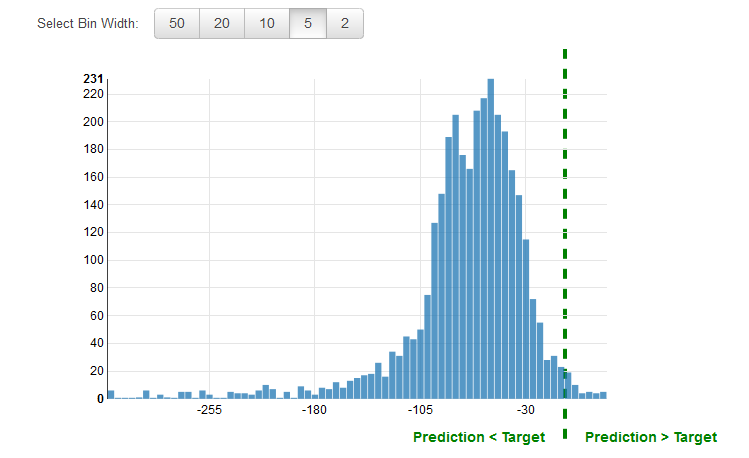
Uso da visualização de desempenho
É uma prática comum examinar os resíduos de problemas de regressão Um resíduo de uma observação nos dados de avaliação é a diferença entre o destino verdadeiro e o previsto. Os resíduos representam a parte do destino que o modelo não consegue prever. Um resíduo positivo indica que o modelo subestima o destino (o destino real é maior do que o previsto). Um resíduo negativo indica uma superestimação (o destino real é menor do que o previsto). Quando distribuído em forma de sino e na base zero, o histograma dos resíduos nos dados de avaliação indica que o modelo comete erros aleatórios e não prevê sistematicamente para mais ou para menos nenhum intervalo de valores de destino. Se os resíduos não se apresentam como um sino de base zero, há estrutura no erro de previsão do modelo. A adição de mais variáveis ao modelo pode ajudá-lo a capturar o padrão que não é captado pelo modelo atual. A ilustração a seguir mostra resíduos que não são centrados em zero.