Não estamos mais atualizando o serviço Amazon Machine Learning nem aceitando novos usuários para ele. Essa documentação está disponível para usuários existentes, mas não estamos mais atualizando-a. Para obter mais informações, consulte O que é o Amazon Machine Learning.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etapa 1: Preparar os dados
Em Machine Learning, você geralmente obtém os dados e garante que seu formato é válido antes de iniciar o processo de treinamento. Para fins deste tutorial, obtivemos um conjunto de dados de amostra no UCI Machine Learning Repository
Para obter os requisitos de formatação do Amazon ML, consulte Noções básicas sobre o formato de dados para Amazon ML.
Para fazer download dos conjuntos de dados
-
Faça download do arquivo que contém os dados históricos dos clientes que compraram produtos semelhantes ao seu depósito bancário de longo prazo clicando em banking.zip. Descompacte a pasta e salve o arquivo banking.csv no computador.
-
Faça download do arquivo que você usará para prever se os clientes em potencial responderão à oferta clicando em banking-batch.zip. Descompacte a pasta e salve o arquivo banking-batch.csv no computador.
-
Abra o
banking.csv. Você verá linhas e colunas de dados. A linha do cabeçalho contém os nomes dos atributos de cada coluna. Um atributo é uma propriedade exclusiva nomeada que descreve uma característica específica de cada cliente, por exemplo, nr_employed indica o status de contratação do cliente. Cada linha representa a coleção de observações sobre um único cliente.
Você quer que o modelo de ML responda à pergunta "O cliente se inscreverá no meu novo produto?". No conjunto de dados
banking.csv, a resposta a essa pergunta é o atributo y, que contém os valores 1 (para sim) ou 0 (para não). O atributo que você deseja que o Amazon ML saiba como prever é chamado de atributo de destino.nota
O atributo y é um atributo binário. Ele pode conter apenas um dos dois valores, neste caso, 0 ou 1. No conjunto de dados UCI original, o atributo y é Sim ou Não. Editamos o conjunto de dados original para você. Agora, todos os valores do atributo y que significam sim são 1, e todos os valores que significam não são 0. Se você usar seus próprios dados, poderá usar outros valores para um atributo binário. Para obter mais informações sobre valores válidos, consulte Usando o AttributeType campo.
Os exemplos a seguir mostram os dados antes e depois que alteramos os valores do atributo y para os atributos binários 0 e 1.
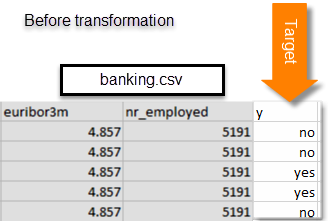
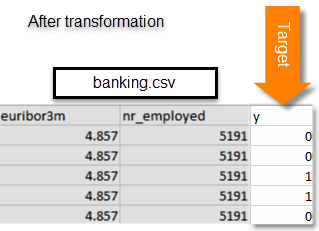
O arquivo banking-batch.csv não contém o atributo y. Após criar um modelo de ML, você o usará para prever y para cada registro nesse arquivo.
Em seguida, faça upload dos arquivos banking.csv e banking-batch.csv para o Amazon S3.
Para fazer upload dos arquivos para um local do Amazon S3
Faça login no AWS Management Console e abra o console do Amazon S3 em. https://console.aws.amazon.com/s3/
-
Na lista All Buckets (Todos os buckets), crie um bucket ou escolha o local onde você deseja fazer upload dos arquivos.
-
Na barra de navegação, escolha Upload (Fazer upload).
-
Escolha Adicionar arquivos.
-
Na caixa de diálogo, navegue até a área de trabalho, escolha
banking.csvebanking-batch.csve escolha Open (Abrir).
Agora, você está pronto para criar a fonte de dados de treinamento.
