As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Atributos e limites da pesquisa vetorial
Disponibilidade da pesquisa vetorial
A configuração do MemoryDB habilitada para pesquisa vetorial é suportada nos tipos de nós R6g, R7g e T4g e está disponível em todas as regiões em que o MemoryDB está disponível. AWS
Não é possível modificar os clusters existentes para habilitar a pesquisa. No entanto, clusters habilitados para pesquisa podem ser criados com base em snapshots de clusters com a pesquisa desabilitada.
Restrições paramétricas
A tabela a seguir mostra os limites de vários itens de pesquisa vetorial:
| Item | Valor máximo |
|---|---|
| Número de dimensões em um vetor | 32768 |
| Número de índices que podem ser criados | 10 |
| Número de campos em um índice | 50 |
| Cláusula TIMEOUT de FT.SEARCH e FT.AGGREGATE (milissegundos) | 10000 |
| Número de estágios do pipeline no comando FT.AGGREGATE | 32 |
| Número de campos na cláusula FT.AGGREGATE LOAD | 1024 |
| Número de campos na cláusula FT.AGGREGATE GROUPBY | 16 |
| Número de campos na cláusula FT.AGGREGATE SORTBY | 16 |
| Número de parâmetros na cláusula FT.AGGREGATE PARAM | 32 |
| Parâmetro HNSW M | 512 |
| Parâmetro HNSW EF_CONSTRUCTION | 4096 |
| Parâmetro HNSW EF_RUNTIME | 4096 |
Limites de escala
Atualmente, a pesquisa vetorial para MemoryDB está limitada a um único fragmento, e não há suporte para escala horizontal. A pesquisa vetorial oferece suporte para escala vertical e de réplica.
Restrições operacionais
Persistência e preenchimento de índices
O recurso de pesquisa vetorial mantém a definição de índices e o conteúdo do índice. Isso significa que, durante qualquer solicitação ou evento operacional que faça com que um nó seja iniciado ou reiniciado, a definição e o conteúdo do índice são restaurados a partir do snapshot mais recente e todas as transações pendentes são lidas do log de transações Multi-AZ. Nenhuma ação do usuário é necessária para iniciar isso. A reconstrução é executada como uma operação de preenchimento assim que os dados são restaurados. Isso é funcionalmente equivalente ao sistema executar automaticamente um comando FT.CREATE para cada índice definido. Observe que o nó fica disponível para operações do aplicativo assim que os dados são restaurados, mas provavelmente antes da conclusão do preenchimento do índice, o que significa que os preenchimentos voltarão a ficar visíveis para as aplicações. Por exemplo, comandos de pesquisa usando índices de preenchimento podem ser rejeitados. Para obter mais informações sobre preenchimento, consulte Visão geral sobre a pesquisa vetorial.
A conclusão do preenchimento do índice não é sincronizada entre um primário e uma réplica. Essa falta de sincronização pode se tornar inesperadamente visível para as aplicações e, portanto, é recomendável que estas verifiquem a conclusão do preenchimento nos primários e em todas as réplicas antes de iniciar as operações de pesquisa.
Instantâneo import/export e migração ao vivo
A presença de índices de pesquisa em um arquivo RDB limita a transportabilidade compatível desses dados. O formato dos índices de vetores definidos pela funcionalidade de pesquisa vetorial do MemoryDB somente é compreendido por outro cluster habilitado para vetores do MemoryDB. Além disso, os arquivos RDB dos clusters de pré-visualização podem ser importados pela versão GA dos clusters do MemoryDB, que reconstruirá o conteúdo do índice ao carregar o arquivo RDB.
No entanto, arquivos RDB que não contêm índices não são restritos dessa maneira. Assim, os dados em um cluster de prévia podem ser exportados para clusters sem prévia, excluindo os índices antes da exportação.
Consumo de memória
O consumo de memória é baseado no número de vetores, no número de dimensões, no valor M e na quantidade de dados não vetoriais, como metadados associados ao vetor ou outros dados armazenados na instância.
A memória total necessária é uma combinação do espaço necessário para os dados vetoriais reais e o espaço necessário para os índices de vetores. O espaço necessário para dados vetoriais é calculado medindo a capacidade real necessária para armazenar vetores em estruturas de dados HASH ou JSON e a sobrecarga até as placas de memória mais próximas, para alocações de memória ideais. Cada um dos índices de vetores usa referências aos dados vetoriais armazenados nessas estruturas de dados e usa otimizações de memória eficientes para remover qualquer cópia duplicada dos dados vetoriais no índice.
O número de vetores depende de como você decide representar os dados como vetores. Por exemplo, você pode optar por representar um único documento em vários blocos, onde cada um representa um vetor. Como alternativa, você pode optar por representar o documento inteiro como um único vetor.
O número de dimensões dos vetores depende do modelo de incorporação escolhido. Por exemplo, se você optar por usar o modelo de incorporação AWS Titan
O parâmetro M representa o número de links bidirecionais criados para cada novo elemento durante a construção do índice. O MemoryDB padroniza esse valor para 16, mas você pode substituí-lo. Um parâmetro M mais alto funciona melhor para requisitos de alta dimensionalidade e and/or alto recall, enquanto parâmetros M baixos funcionam melhor para requisitos de baixa dimensionalidade e and/or baixo recall. O valor M aumenta o consumo de memória à medida que o índice aumenta.
Na experiência do console, o MemoryDB oferece uma maneira fácil de escolher o tipo de instância certo com base nas características da workload vetorial após marcar Habilitar pesquisa vetorial nas configurações do cluster.
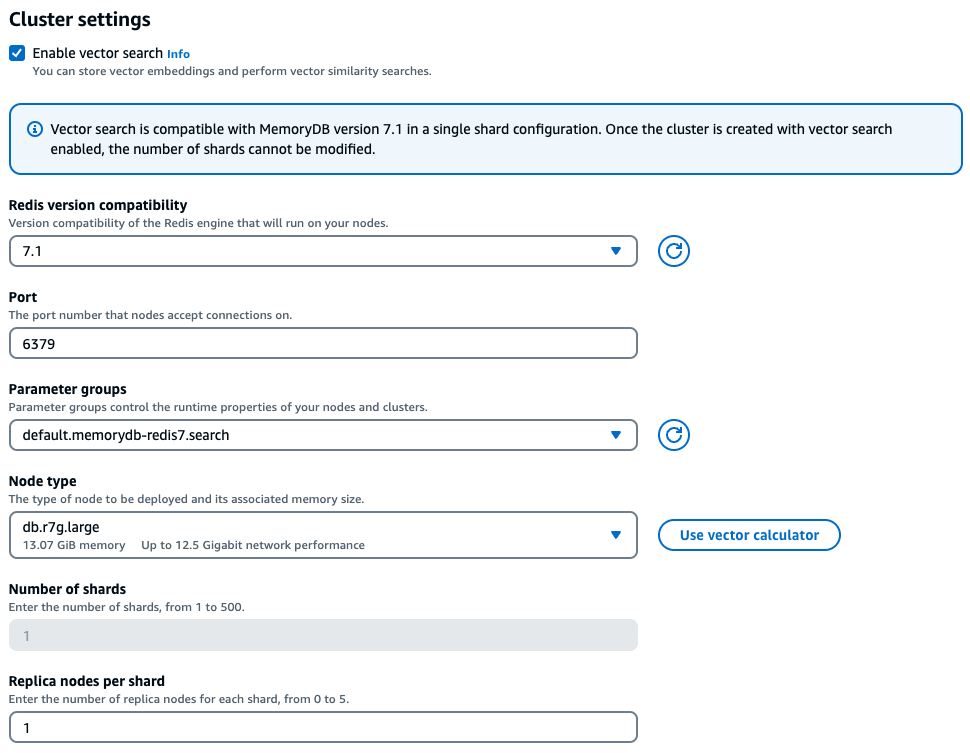
Exemplo de workload
Um cliente deseja criar um mecanismo de busca semântica baseado em seus documentos financeiros internos. Atualmente, ele tem 1 milhão de documentos financeiros que estão divididos em 10 vetores por documento usando o modelo de incorporação Titan com 1.536 dimensões, sem nenhum dado não vetorial. O cliente decide usar o padrão de 16 como parâmetro M.
Vetores: 1M * 10 blocos = 10 milhões de vetores
Dimensions: 1.536
Dados não vetoriais (GB): 0 GB
Parâmetro M: 16
Com esses dados, o cliente pode clicar no botão Usar calculadora vetorial no console para obter um tipo de instância recomendado com base em seus parâmetros:
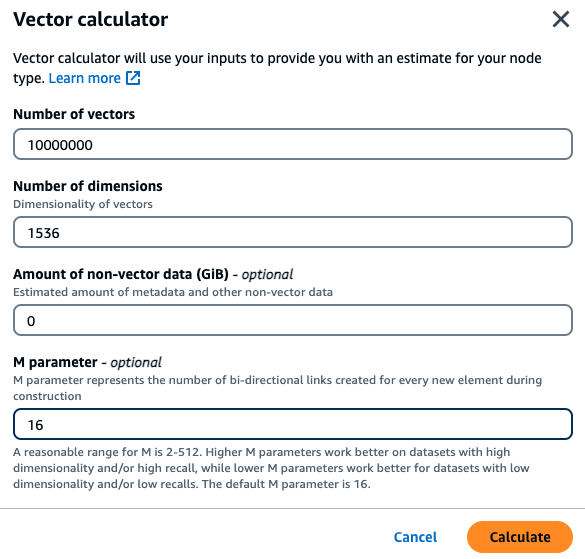

Neste exemplo, a calculadora vetorial procurará o menor tipo de nó r7g do MemoryDB
Com base no método de cálculo acima e nos parâmetros da workload da amostra, esses dados vetoriais exigiriam 104,9 GB para armazenamento e um único índice. Nesse caso, o tipo de instância db.r7g.4xlarge seria recomendado, pois tem 105,81 GB de memória utilizável. O próximo menor tipo de nó seria muito pequeno para conter a workload vetorial.
Como cada um dos índices de vetores usa referências aos dados vetoriais armazenados e não cria cópias adicionais dos dados vetoriais no índice de vetores, os índices também consumirão relativamente menos espaço. Isso é muito útil na criação de vários índices e também em situações em que partes dos dados vetoriais foram excluídos e quando a reconstrução do gráfico HNSW ajudaria a criar conexões de nós ideais para gerar resultados de pesquisa vetorial de alta qualidade.
Sem memória durante o preenchimento
Semelhante às operações de gravação do Valkey e do Redis OSS, um preenchimento de índice está sujeito a limitações. out-of-memory Se a memória do mecanismo ficar cheia enquanto um preenchimento estiver em andamento, todos os preenchimentos serão pausados. Se a memória ficar disponível, o processo de preenchimento será retomado. Também é possível excluir e indexar quando o preenchimento é pausado devido à falta de memória.
Transações
Os comandosFT.CREATE,, FT.DROPINDEX FT.ALIASADDFT.ALIASDEL, e FT.ALIASUPDATE não podem ser executados em um contexto transacional, ou seja, não dentro de um MULTI/EXEC bloco ou dentro de um script LUA ou FUNCTION.
