As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Manutenção de tabelas usando compactação
O Iceberg inclui recursos que permitem realizar operações de manutenção da tabela
Compactação de iceberg
No Iceberg, você pode usar a compactação para realizar quatro tarefas:
-
Combinação de arquivos pequenos em arquivos maiores que geralmente têm mais de 100 MB. Essa técnica é conhecida como embalagem de lixo.
-
Mesclando arquivos excluídos com arquivos de dados. Os arquivos excluídos são gerados por atualizações ou exclusões que usam a merge-on-read abordagem.
-
(Re) classificando os dados de acordo com os padrões de consulta. Os dados podem ser gravados sem qualquer ordem de classificação ou com uma ordem de classificação adequada para gravações e atualizações.
-
Agrupar os dados usando curvas de preenchimento de espaço para otimizar padrões de consulta distintos, particularmente a classificação de ordem z.
Ativado AWS, você pode executar operações de compactação e manutenção de tabelas para o Iceberg por meio do Amazon Athena ou usando o Spark no Amazon EMR ou. AWS Glue
Ao executar a compactação usando o procedimento rewrite_data_files
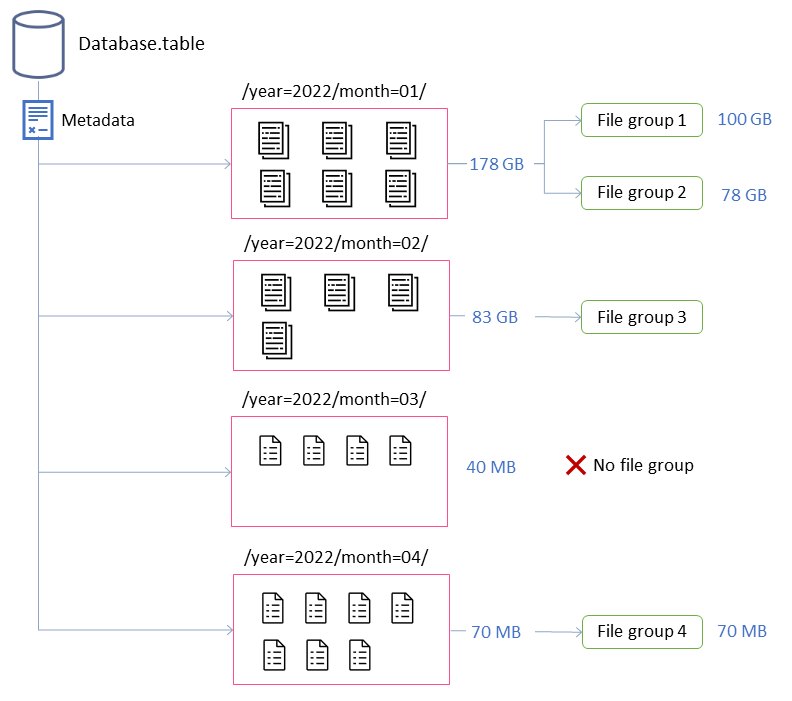
Neste exemplo, a tabela Iceberg consiste em quatro partições. Cada partição tem um tamanho diferente e um número diferente de arquivos. Se você iniciar um aplicativo Spark para executar a compactação, o aplicativo criará um total de quatro grupos de arquivos para processar. Um grupo de arquivos é uma abstração do Iceberg que representa uma coleção de arquivos que serão processados por uma única tarefa do Spark. Ou seja, o aplicativo Spark que executa a compactação criará quatro trabalhos do Spark para processar os dados.
Ajustando o comportamento de compactação
As propriedades principais a seguir controlam como os arquivos de dados são selecionados para compactação:
-
MAX_FILE_GROUP_SIZE_BYTES
define o limite de dados para um único grupo de arquivos (tarefa do Spark) em 100 GB por padrão. Essa propriedade é especialmente importante para tabelas sem partições ou tabelas com partições que abrangem centenas de gigabytes. Ao definir esse limite, você pode dividir as operações para planejar o trabalho e progredir, evitando o esgotamento dos recursos no cluster. Nota: Cada grupo de arquivos é classificado separadamente. Portanto, se você quiser realizar uma classificação em nível de partição, deverá ajustar esse limite para corresponder ao tamanho da partição.
-
MIN_FILE_SIZE_BYTES ou MIN_FILE_SIZE_DEFAULT_RATIO
assumem como padrão 75 por cento do tamanho do arquivo de destino definido no nível da tabela. Por exemplo, se uma tabela tiver um tamanho alvo de 512 MB, qualquer arquivo menor que 384 MB será incluído no conjunto de arquivos que serão compactados. -
MAX_FILE_SIZE_BYTES ou MAX_FILE_SIZE_DEFAULT_RATIO
assumem como padrão 180 por cento do tamanho do arquivo de destino . Assim como as duas propriedades que definem tamanhos mínimos de arquivo, essas propriedades são usadas para identificar arquivos candidatos para o trabalho de compactação. -
MIN_INPUT_FILES especifica o número mínimo de arquivos
a serem compactados se o tamanho da partição da tabela for menor que o tamanho do arquivo de destino. O valor dessa propriedade é usado para determinar se vale a pena compactar os arquivos com base no número de arquivos (o padrão é 5). -
DELETE_FILE_THRESHOLD
especifica o número mínimo de operações de exclusão de um arquivo antes de ser incluído na compactação. A menos que você especifique o contrário, a compactação não combina arquivos excluídos com arquivos de dados. Para habilitar essa funcionalidade, você deve definir um valor limite usando essa propriedade. Esse limite é específico para arquivos de dados individuais, portanto, se você defini-lo como 3, um arquivo de dados será regravado somente se houver três ou mais arquivos de exclusão que façam referência a ele.
Essas propriedades fornecem informações sobre a formação dos grupos de arquivos no diagrama anterior.
Por exemplo, a partição rotulada month=01 inclui dois grupos de arquivos porque excede a restrição de tamanho máximo de 100 GB. Por outro lado, a month=02 partição contém um único grupo de arquivos porque tem menos de 100 GB. A month=03 partição não atende ao requisito mínimo padrão de arquivo de entrada de cinco arquivos. Como resultado, ele não será compactado. Por fim, embora a month=04 partição não contenha dados suficientes para formar um único arquivo do tamanho desejado, os arquivos serão compactados porque a partição inclui mais de cinco arquivos pequenos.
Você pode definir esses parâmetros para o Spark executado no Amazon AWS Glue EMR ou. Para o Amazon Athena, você pode gerenciar propriedades semelhantes usando as propriedades da tabela (que começam com o prefixooptimize_).
Executando a compactação com o Spark no Amazon EMR ou AWS Glue
Esta seção descreve como dimensionar adequadamente um cluster Spark para executar o utilitário de compactação do Iceberg. O exemplo a seguir usa o Amazon EMR Serverless, mas você pode usar a mesma metodologia no Amazon EMR na Amazon ou no Amazon EKS, EC2 ou em. AWS Glue
Você pode aproveitar a correlação entre grupos de arquivos e trabalhos do Spark para planejar os recursos do cluster. Para processar os grupos de arquivos sequencialmente, considerando o tamanho máximo de 100 GB por grupo de arquivos, você pode definir as seguintes propriedades do Spark:
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
Se quiser acelerar a compactação, você pode escalar horizontalmente aumentando o número de grupos de arquivos que são compactados em paralelo. Você também pode escalar o Amazon EMR usando escalabilidade manual ou dinâmica.
-
Dimensionamento manual (por exemplo, por um fator de 4)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(nosso fator) -
spark.executor.instances=5(valor usado no exemplo) x4(nosso fator) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
Dimensionamento dinâmico
-
spark.dynamicAllocation.enabled=TRUE(padrão, nenhuma ação é necessária) -
MAX_CONCURRENT_FILE_GROUP_REWRITES
= N(alinhe esse valor comspark.dynamicAllocation.maxExecutors, que é 100 por padrão; com base nas configurações do executor no exemplo, você pode definir como 20)N
Essas são diretrizes para ajudar a dimensionar o cluster. No entanto, você também deve monitorar o desempenho de suas tarefas do Spark para encontrar as melhores configurações para suas cargas de trabalho.
-
Executando a compactação com o Amazon Athena
O Athena oferece uma implementação do utilitário de compactação do Iceberg como um recurso gerenciado por meio da declaração OPTIMIZE. Você pode usar essa instrução para executar a compactação sem precisar avaliar a infraestrutura.
Essa instrução agrupa arquivos pequenos em arquivos maiores usando o algoritmo de empacotamento de compartimentos e mescla arquivos excluídos com arquivos de dados existentes. Para agrupar os dados usando classificação hierárquica ou classificação de ordem z, use o Spark no Amazon EMR ou. AWS Glue
Você pode alterar o comportamento padrão da OPTIMIZE instrução na criação da tabela passando as propriedades da tabela na CREATE TABLE instrução ou após a criação da tabela usando a ALTER TABLE instrução. Para valores padrão, consulte a documentação do Athena.
Recomendações para executar a compactação
Caso de uso |
Recomendação |
|---|---|
Executando a compactação da embalagem de lixeiras com base em um cronograma |
|
Executando a compactação de embalagens de lixo com base em eventos |
|
Executando a compactação para classificar dados |
|
Executando a compactação para agrupar os dados usando a classificação de ordem z |
|
Executando a compactação em partições que podem ser atualizadas por outros aplicativos devido à chegada tardia de dados |
|
Executando a compactação em partições frias (partições de dados que não recebem mais gravações ativas) |
|
