As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Introdução às tabelas Apache Iceberg no Amazon Athena SQL
O Amazon Athena fornece suporte integrado para o Apache Iceberg. Você pode usar o Iceberg sem nenhuma etapa ou configuração adicional, exceto para definir os pré-requisitos de serviço detalhados na seção Introdução da documentação do Athena. Esta seção fornece uma breve introdução à criação de tabelas no Athena. Para obter mais informações, consulte Trabalhando com tabelas do Apache Iceberg usando o Athena SQL mais adiante neste guia.
Você pode criar tabelas Iceberg AWS usando mecanismos diferentes. Essas tabelas funcionam perfeitamente em todas Serviços da AWS. Para criar suas primeiras tabelas Iceberg com o Athena SQL, você pode usar o seguinte código padronizado.
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
As seções a seguir fornecem exemplos de criação de tabelas Iceberg particionadas e não particionadas no Athena. Para obter mais informações, consulte a sintaxe do Iceberg detalhada na documentação do Athena.
Criação de uma tabela não particionada
O exemplo de instrução a seguir personaliza o código SQL padronizado para criar uma tabela Iceberg não particionada no Athena. Você pode adicionar essa instrução ao editor de consultas no console do Athenapara
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Para step-by-step obter instruções sobre como usar o editor de consultas, consulte Introdução na documentação do Athena.
Criar uma tabela particionada
A declaração a seguir cria uma tabela particionada com base na data usando o conceito de particionamento ocultoday() transformação para derivar partições diárias, usando o dd-mm-yyyy formato, de uma coluna de carimbo de data/hora. O Iceberg não armazena esse valor como uma nova coluna no conjunto de dados. Em vez disso, o valor é derivado dinamicamente quando você grava ou consulta dados.
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Criando uma tabela e carregando dados com uma única instrução CTAS
Nos exemplos particionados e não particionados das seções anteriores, as tabelas Iceberg são criadas como tabelas vazias. Você pode carregar dados nas tabelas usando a MERGE instrução INSERT or. Como alternativa, você pode usar uma CREATE TABLE AS SELECT (CTAS) instrução para criar e carregar dados em uma tabela Iceberg em uma única etapa.
O CTAS é a melhor maneira no Athena de criar uma tabela e carregar dados em uma única instrução. O exemplo a seguir ilustra como usar o CTAS para criar uma tabela Iceberg () a partir de uma tabela Hive/Parquet existente (iceberg_ctas_table) no Athena. hive_table
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
Para saber mais sobre o CTAS, consulte a documentação do Athena CTAS.
Inserindo, atualizando e excluindo dados
O Athena oferece suporte a diferentes formas de gravar dados em uma tabela Iceberg usando as INSERT INTO instruções, UPDATEMERGE INTO, e M. DELETE FRO
Nota:UPDATE,MERGE INTO, e DELETE FROM use a merge-on-read abordagem com exclusões posicionais. Atualmente, a copy-on-write abordagem não é compatível com o Athena SQL.
Por exemplo, a declaração a seguir é usada INSERT INTO para adicionar dados a uma tabela Iceberg:
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
Exemplo de resultado:

Para obter mais informações, consulte a documentação do Athena.
Consultando tabelas Iceberg
Você pode executar consultas SQL regulares em suas tabelas do Iceberg usando o Athena SQL, conforme ilustrado no exemplo anterior.
Além das consultas usuais, o Athena também oferece suporte a consultas de viagem no tempo para tabelas Iceberg. Conforme discutido anteriormente, você pode alterar os registros existentes por meio de atualizações ou exclusões em uma tabela do Iceberg, portanto, é conveniente usar consultas de viagem no tempo para examinar as versões mais antigas da sua tabela com base em um carimbo de data/hora ou em um ID de instantâneo.
Por exemplo, a instrução a seguir atualiza um valor de cor para ePerson5, em seguida, exibe um valor anterior de 4 de janeiro de 2023:
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
Exemplo de resultado:
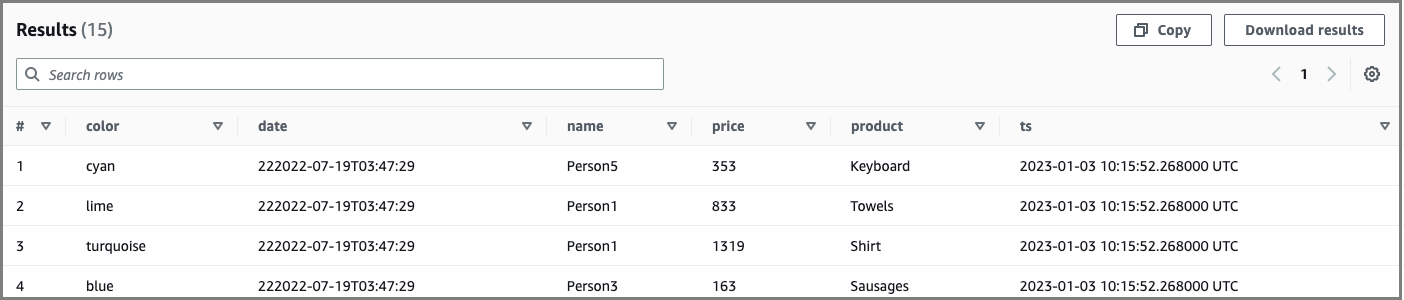
Para ver exemplos adicionais e de sintaxe de viagens no tempo, consulte a documentação do Athena.
Anatomia da mesa de iceberg
Agora que abordamos as etapas básicas do trabalho com mesas Iceberg, vamos nos aprofundar nos detalhes intrincados e no design de uma mesa Iceberg.
Para habilitar os recursos descritos anteriormente neste guia, o Iceberg foi projetado com camadas hierárquicas de dados e arquivos de metadados. Essas camadas gerenciam os metadados de forma inteligente para otimizar o planejamento e a execução de consultas.
O diagrama a seguir retrata a organização de uma tabela Iceberg por meio de duas perspectivas: a Serviços da AWS usada para armazenar a tabela e a colocação do arquivo no Amazon S3.
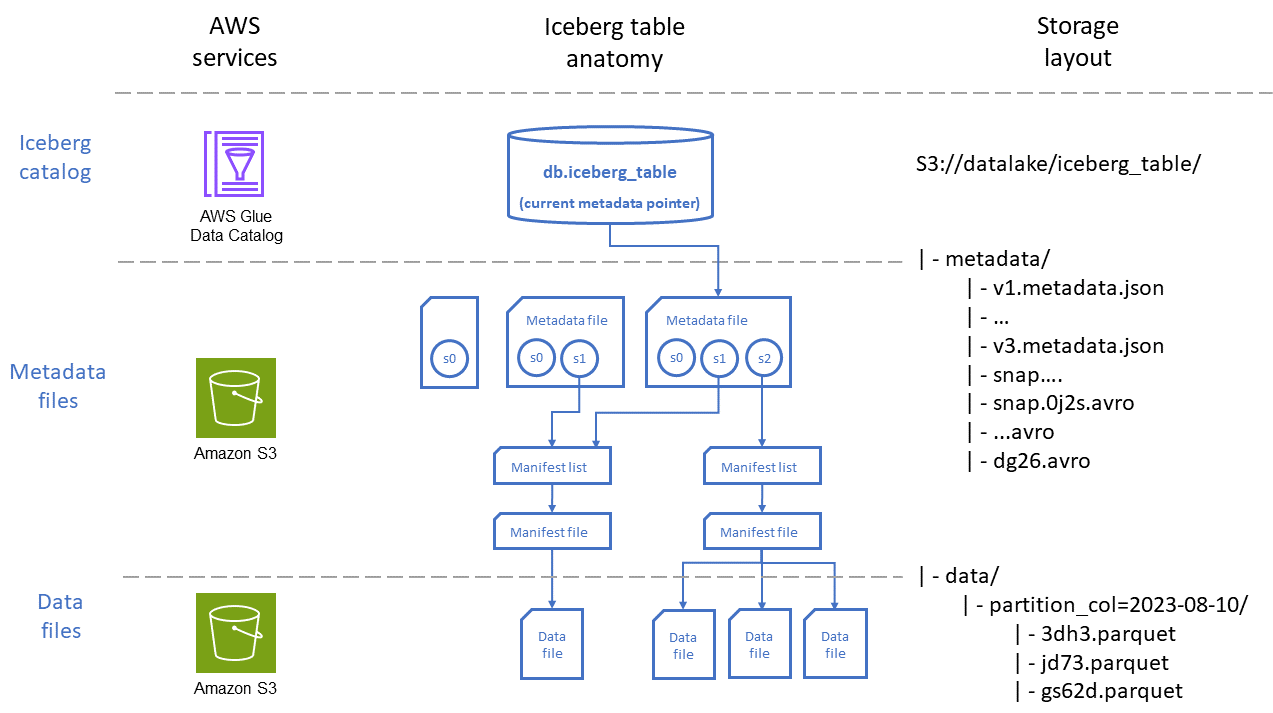
Conforme mostrado no diagrama, uma tabela Iceberg consiste em três camadas principais:
-
Catálogo Iceberg: AWS Glue Data Catalog integra-se nativamente ao Iceberg e é, para a maioria dos casos de uso, a melhor opção para cargas de trabalho executadas em. AWS Os serviços que interagem com as tabelas do Iceberg (por exemplo, Athena) usam o catálogo para encontrar a versão instantânea atual da tabela, seja para ler ou gravar dados.
-
Camada de metadados: os arquivos de metadados, ou seja, os arquivos de manifesto e os arquivos de lista de manifestos, controlam informações como o esquema das tabelas, a estratégia de partição e a localização dos arquivos de dados, bem como estatísticas em nível de coluna, como intervalos mínimos e máximos dos registros armazenados em cada arquivo de dados. Esses arquivos de metadados são armazenados no Amazon S3 dentro do caminho da tabela.
-
Os arquivos de manifesto contêm um registro para cada arquivo de dados, incluindo sua localização, formato, tamanho, soma de verificação e outras informações relevantes.
-
As listas de manifestos fornecem um índice dos arquivos de manifesto. À medida que o número de arquivos de manifesto aumenta em uma tabela, dividir essas informações em subseções menores ajuda a reduzir o número de arquivos de manifesto que precisam ser verificados por consultas.
-
Os arquivos de metadados contêm informações sobre toda a tabela Iceberg, incluindo as listas de manifestos, os esquemas, os metadados da partição, os arquivos de instantâneos e outros arquivos usados para gerenciar os metadados da tabela.
-
-
Camada de dados: essa camada contém os arquivos que têm os registros de dados nos quais as consultas serão executadas. Esses arquivos podem ser armazenados em diferentes formatos, incluindo Apache Parquet, Apache
Avro e Apache ORC . -
Os arquivos de dados contêm os registros de dados de uma tabela.
-
Os arquivos de exclusão codificam operações de exclusão e atualização em nível de linha em uma tabela Iceberg. O Iceberg tem dois tipos de arquivos de exclusão, conforme descrito na documentação do Iceberg
. Esses arquivos são criados por operações usando o merge-on-read modo.
-
