As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Máquinas de estados do Aurora e Step Functions
Esta seção aborda as máquinas de processo e estado específicas para o failover e o failback dos clusters do Amazon Aurora. Os clusters são configurados como um banco de dados global.
nota
Para fins de demonstração, este exemplo usa a edição compatível com o Aurora MySQL. Você pode usar etapas semelhantes para a edição compatível com o Aurora PostgreSQL.
Estado estacionário
No estado estável, um banco de dados global compatível com Amazon Aurora MySQL dr-globaldb-cluster-mysql () foi criado com dois clusters de banco de dados. O primeiro cluster de banco de dados (db-cluster-01) foi criado no primary Região da AWS
(us-east-1) para atender à carga de trabalho de leitura/gravação. O segundo cluster de banco de dados (db-cluster-02) foi criado na região secundária (us-west-2) para atender à carga de trabalho somente para leitura.
Além de fornecer a solução de DR, você pode reduzir a carga em seu cluster de banco de dados primário roteando consultas de leitura de seus aplicativos para o cluster de banco de dados secundário. Cada um desses clusters contém uma instância de banco de dados chamada dbcluster-01-use1-instance-1 edbcluster-02-usw2-instance-2, respectivamente.
Estado do evento
Ao usar um banco de dados global do Amazon Aurora, você pode planejar e se recuperar de um desastre com bastante rapidez. A recuperação de desastres geralmente é medida usando valores para objetivo de tempo de recuperação (RTO) e objetivo de ponto de recuperação (RPO). Para obter mais informações, consulte Uso de alternância ou failover em um banco de dados global do Amazon Aurora.
Com um banco de dados global Aurora, há duas abordagens diferentes para o failover:
-
Transição (failover planejado gerenciado)
-
Failover (failover manual não planejado ou desanexar e promover)
Transição
A transição é destinada a ambientes controlados, como manutenção operacional e outros procedimentos operacionais planejados. Ao usar um failover planejado gerenciado, você pode realocar o cluster de banco de dados principal do seu banco de dados global Aurora para uma das regiões secundárias. Como o switchover espera até que os clusters de banco de dados secundários sejam sincronizados com o banco de dados primário, o RPO é 0 (sem perda de dados). Para saber mais, consulte Execução de transições para bancos de dados globais do Amazon Aurora.
A máquina de dr-orchestrator-stepfunction-FAILOVER estado é invocada durante o estado do evento para alternar seu cluster primário para a região secundária escolhida (us-west-2).
Para realizar a transição, faça o seguinte:
-
Faça login no AWS Management Console.
-
Altere a região para a região DR (
us-west-2). -
Navegue até Services e escolha Step Functions.
-
Navegue até a máquina de
dr-orchestrator-stepfunction-FAILOVERestado. -
Escolha Iniciar execução e insira o seguinte código JSON na
Input - optionalseção:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
A máquina de
dr-orchestrator-stepfunction-FAILOVERestado lê o tipo de recurso comoPlannedFailoverAuroraMySQL e chama a máquina dedr-orchestrator-stepfunction-planned-Aurora-failoverestado para fazer o failover do banco de dados global Aurora.
-
A máquina de
dr-orchestrator-stepfunction-planned-Aurora-failoverestado executa as etapas a seguir para alternar a função de banco de dados global compatível com o Aurora MySQL.
Etapa Descrição Valores esperados Resolver importações Uma função Lambda substitui !Import <variable name>valores pelo nome real."!Import dr-globaldb-cluster-mysql-global-identifier"é substituído por"dr-globaldb-cluster-mysql".Faça o failover do Aurora Global Cluster Uma função Lambda chama as APIs failover_global_cluster Boto3 para realizar o failover do banco de dados global Aurora. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Verifique o status do failover Uma função Lambda chama as APIs Boto3 describe_db_clusters para verificar o status do failover. modificando, disponível Envie tokens de sucesso Uma função Lambda chama as APIs de Boto3 send_task_success e envia um token de sucesso de volta para a máquina de estado. DR Orchestrator FailoverH7x/83P1E0 K9MBvkzsp7D9YRT1W RiCdLtd dMccoxlzFhglsdkzp -
Navegue até o console do Amazon RDS. Em Status, os valores do banco de dados global do Aurora mudarão de Disponível para Alternância ou Modificação.
-
Depois que a máquina de
dr-orchestrator-stepfunction-planned-Aurora-failoverestado é concluída, ela envia um token de sucesso de volta para a máquina dedr-orchestrator-stepfunction-FAILOVERestado.
-
A máquina de
dr-orchestrator-stepfunction-FAILOVERestado está concluída.
No console, a função do cluster secundário (dbcluster-02) agora é cluster primário, e o cluster está pronto para atender cargas de trabalho de leitura/gravação. A função do cluster primário original (dbcluster-01) agora está listada como cluster secundário.
Failover manual não planejado
Em raras ocasiões, seu banco de dados global Aurora pode sofrer uma interrupção inesperada em seu banco de dados primário. Região da AWS Se isso acontecer, seu cluster de banco de dados Aurora primário e seu nó de gravador não estarão disponíveis, e a replicação entre o cluster primário e os secundários cessará. Para minimizar o tempo de inatividade (RTO) e a perda de dados (RPO), trabalhe rapidamente para realizar um failover entre regiões e reconstruir seu banco de dados global Aurora. Para obter mais informações, consulte Recuperação de um banco de dados global do Amazon Aurora após uma interrupção não planejada.
A execução de um failover não planejado exige que você separe seu cluster secundário do banco de dados global Aurora. Antes de realizar o failover não planejado, interrompa as gravações do aplicativo em seu cluster de banco de dados Aurora primário. Depois que o failover for concluído com êxito, reconfigure o aplicativo para gravar no novo cluster de banco de dados primário. Essa abordagem ajuda a evitar a perda de dados. Também ajuda a evitar inconsistências de dados se o nó do gravador primário voltar a ficar on-line durante o processo de failover.
Para realizar o failover não planejado, ligue para a máquina de dr-orchestrator-stepfunction-FAILOVER estado. Neste exemplo, o cluster secundário (db-cluster-02) está na região DR (us-west-2) em estado estável.
Para realizar o failover, faça o seguinte:
-
Faça login no console do .
-
Altere a região para a região DR (
us-west-2). -
Navegue até Services e escolha Step Functions.
-
Navegue até a máquina de
dr-orchestrator-stepfunction-FAILOVERestado. -
Escolha Iniciar execução e insira o seguinte código JSON na
Input - optionalseção, usandoUnPlannedFailoverAuroracomo:resourceType{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
A máquina de
dr-orchestrator-stepfunction-FAILOVERestado lê o tipo de recurso comoUnPlannedFailoverAuroraMySQLe chama a tarefaDetach Cluster from Global Databaseda máquina dedr-orchestrator-stepfunction-unplanned-Aurora-failoverestado.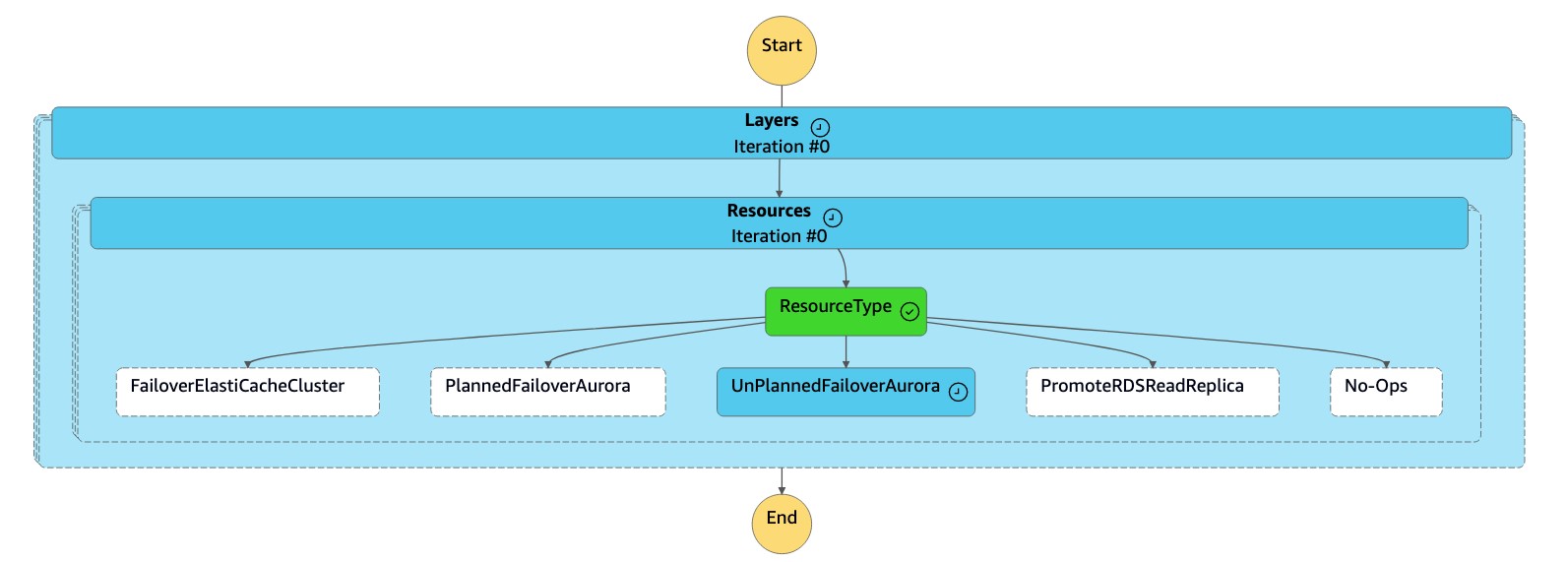
-
A
Detach Cluster from Global Databasetarefa separa (remove) o cluster secundário do banco de dados global.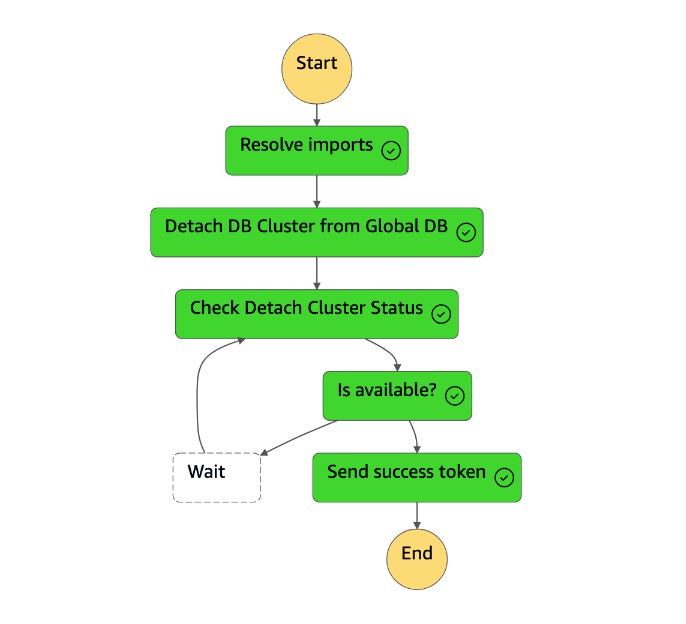
-
O cluster secundário (
dbcluster-02) é promovido para se tornar um cluster independente e pode atender cargas de trabalho de leitura/gravação. -
A máquina de
dr-orchestrator-stepfunction-FAILOVERestado está concluída.
-
O cluster secundário (
dbcluster-02) é separado do banco de dados global Aurora e se torna um cluster independente para atender à carga de trabalho de leitura/gravação. -
Reconfigure seu aplicativo para enviar todas as operações de gravação para esse novo cluster de banco de dados Aurora independente usando seu novo endpoint de cluster.
Failback
Um failback retorna seu banco de dados para o local principal original (ou novo) após a resolução de um desastre (ou evento programado). Quando a interrupção não planejada for resolvida, talvez você queira adicionar sua antiga região primária de volta ao banco de dados global da Aurora. Primeiro, você deve excluir o cluster de banco de dados existente da antiga região primária, criar um novo cluster de banco de dados da nova região primária e, em seguida, usar o processo de failover planejado gerenciado para mudar a função do novo cluster.
Isso pode ser considerado uma atividade planejada que você pode realizar fora do horário de pico ou em um fim de semana.
Você deve modificar manualmente o cluster de banco de dados Amazon Aurora e desativá-lo DeletionProtection antes de executar a máquina de DR Orchestrator FAILBACK estado da antiga região primária (us-east-1) porque ela foi criada com. DeletionProtection
O DR Orchestrator Framework usa a máquina de dr-orchestrator-stepfunction-FAILBACK estado para automatizar as etapas para excluir o cluster existente e criar um novo cluster na antiga região primária.
Para desativarDeletionProtection, faça o seguinte:
-
Faça login no console do .
-
Altere a região para a antiga região primária (
us-east-1). -
Navegue até o console do Amazon RDS, selecione o nome do cluster (
dbcluster-01) e escolha Modificar. -
Em Proteção contra exclusão, desmarque a caixa de seleção Ativar proteção contra exclusão e escolha Continuar.
-
Escolha Aplicar imediatamente e, em seguida, escolha Modificar cluster.
A máquina de DR Orchestrator FAILBACK estado é invocada durante o processo de failback da antiga região primária ()us-east-1.
Para realizar o failback, faça o seguinte:
-
Faça login no console do .
-
Altere a região para a antiga região primária (
us-east-1). -
Navegue até Services e escolha Step Functions.
-
Navegue até a máquina de
DR Orchestrator FAILBACKestado. -
Escolha Iniciar execução e insira o seguinte código JSON na
Input - optionalseção:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
A máquina de
DR Orchestrator FAILBACKestado lê o tipo de recurso comoCreateAuroraSecondaryDBClustere chama a máquina dedr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestado.
-
A máquina de
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestado exclui o cluster existente (dbcluster-01) da antiga região primária (us-east-1).
-
Depois que o cluster (
dbcluster-01) é excluído, a máquina de estado cria um novo cluster (dbcluster-01) junto com a instância de banco de dados e se junta ao banco de dados global Aurora como cluster secundário para atender cargas de trabalho somente para leitura.
-
Depois que o cluster secundário estiver disponível, a máquina de
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterestado será concluída e enviará um token de sucesso de volta para a máquina deDR Orchestrator Failbackestado.
-
A máquina de
dr-orchestrator-stepfunction-FAILBACKestado está concluída.
-
Você pode verificar o banco de dados global do Aurora no console do Amazon RDS.
