As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Arquitetura de referência
O diagrama a seguir mostra o fluxo de trabalho depois de aplicar a solução automatizada deste guia a um relatório diário de operações. Quando novos arquivos são ingeridos no Amazon Simple Storage Service (Amazon S3), eles podem ser imediatamente visualizados em um QuickSight painel após serem processados.
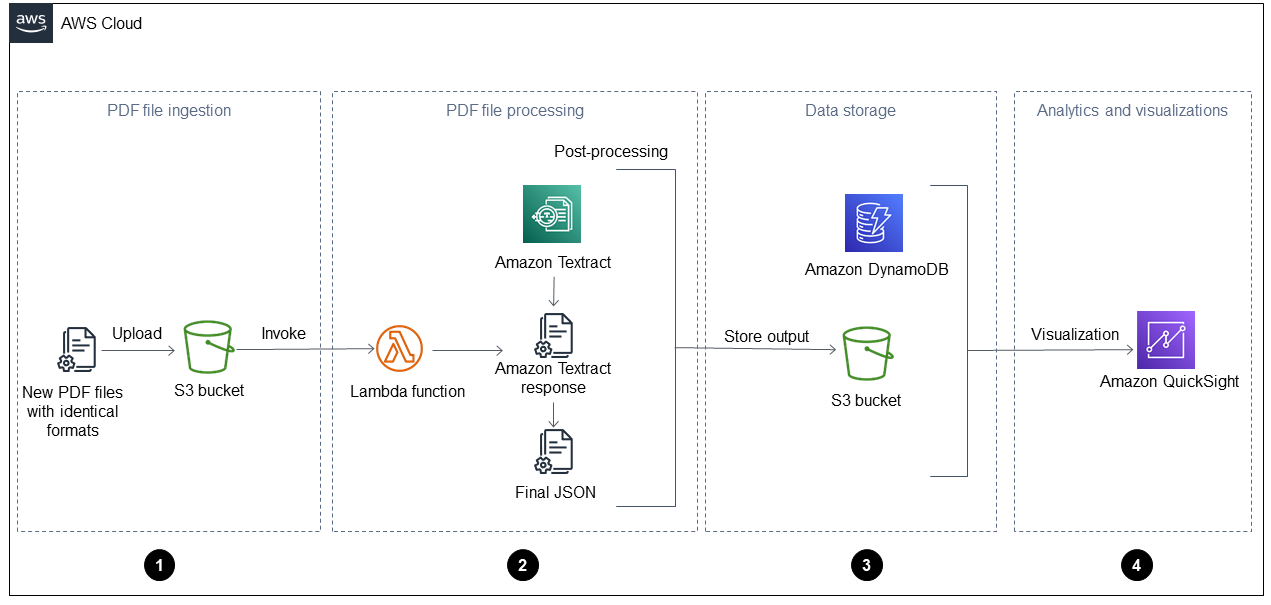
O diagrama mostra as quatro fases a seguir:
-
Ingestão de arquivos PDF — Seu aplicativo ingere automaticamente novos arquivos PDF com formato idêntico (por exemplo, um relatório diário de operações) em um bucket do Amazon Simple Storage Service (Amazon S3). O Amazon S3 inicia um
ObjectCreatedevento quando novos arquivos PDF são adicionados ao bucket e isso invoca uma função. AWS Lambda Para obter mais informações sobre isso, consulte Usando um gatilho do Amazon S3 para invocar uma função Lambda na documentação do Amazon S3. -
Processamento de arquivos PDF — A função Lambda envia um arquivo PDF para o Amazon Textract, que extrai o conteúdo. Um script de pós-processamento executa e analisa a resposta do Amazon Textract e usa um modelo predefinido para esse tipo de arquivo PDF. Esse modelo contém os atributos corretos e ajuda a extrair corretamente todos os pares de valores-chave, tabelas e outros textos brutos. Para obter mais informações sobre isso, consulte o padrão Extrair automaticamente conteúdo de arquivos PDF usando o Amazon Textract no site AWS Prescriptive Guidance.
-
Armazenamento de dados — Os dados extraídos e corrigidos são armazenados em uma tabela do Amazon DynamoDB, além de um arquivo JSON para cada arquivo PDF. Os arquivos JSON são armazenados em um bucket do S3 que pode ser usado por serviços de processamento e análise downstream, como Amazon Athena ou Amazon AI. QuickSight SageMaker
-
Análise e visualizações — QuickSight analisa os dados e cria visualizações que ajudam a gerar insights para todos os arquivos PDF processados. Depois que os painéis forem criados QuickSight, você poderá compartilhá-los com seus usuários finais e equipes de negócios.
Considerações
A solução deste guia é apropriada para processar arquivos PDF que tenham um formato idêntico e um layout consistente de formulários e tabelas. No entanto, você deve definir um modelo e editá-lo com antecedência para automatizar totalmente o processo e disponibilizar os dados extraídos para análise. Esse modelo é então usado durante o processamento com a função Lambda.
Embora essa solução possa ser aplicada a diferentes tipos de arquivos PDF ao mesmo tempo, você deve criar e definir modelos separados para cada tipo de arquivo PDF e armazená-los em um local acessível (por exemplo, Amazon S3). Recomendamos que você use um identificador exclusivo para cada tipo de arquivo PDF, como um nome de arquivo PDF ou pastas diferentes em seu bucket do S3. A função Lambda pode então chamar o modelo apropriado ao processar o tipo de arquivo PDF.
