As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Desafios comuns de escalabilidade
Um data lake passa por vários estágios quando seus dados crescem após a implantação inicial. Se você não usou uma arquitetura escalável para projetar seu data lake, sua organização pode enfrentar desafios e ser prejudicada pelo crescimento do data lake.
As seções a seguir explicam como o crescimento típico de um data lake pode causar desafios de escalabilidade.
Implantação inicial do data lake
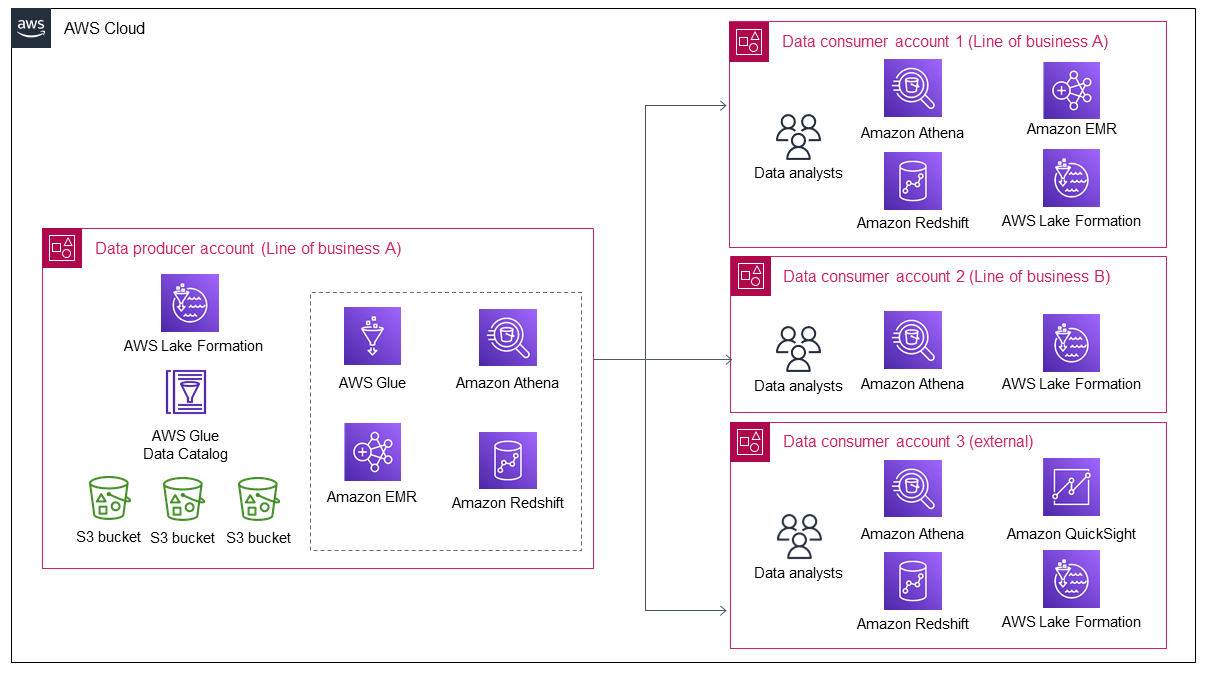
O diagrama a seguir mostra a arquitetura de um data lake após sua implantação inicial pela linha de negócios A.

O diagrama mostra os seguintes componentes:
-
A conta do produtor de dados coleta e processa dados, armazena os dados processados e os prepara para consumo.
-
Os dados na conta do produtor de dados são armazenados em buckets do Amazon Simple Storage Service (Amazon S3), que podem ter várias camadas de dados.
-
Você pode usar AWS serviços para processamento de dados (por exemplo, AWS Gluee o Amazon EMR).
-
O produtor de dados não apenas produz e armazena dados no data lake, mas também precisa decidir quais dados compartilhar com um consumidor de dados e como compartilhá-los. AWS Lake Formation gerencia o data lake na conta do produtor de dados, além de gerenciar o compartilhamento de dados entre contas do produtor de dados para o consumidor de dados.
-
A conta do consumidor de dados consome dados compartilhados da conta do produtor de dados para casos específicos de uso comercial.
Os consumidores de dados aumentam
O diagrama a seguir mostra que mais dados são trazidos para o data lake quando os dados da linha de negócios A crescem. O data lake então atrai mais consumidores de dados para aproveitar e obter valor dos dados.
O diagrama mostra como uma organização gera valor quase contínuo a partir de um ativo de dados existente e que isso atrai mais consumidores de dados. No entanto, quando os consumidores de dados aumentam, o produtor de dados só tem as duas opções a seguir para acomodar esse crescimento:
-
Gerencie manualmente o compartilhamento e o acesso de dados por consumidores individuais de dados, o que não é uma abordagem escalável.
-
Desenvolva um processo automatizado ou semiautomatizado para compartilhamento de dados e gerenciamento do acesso aos dados. Embora essa possa ser uma opção escalável, ela exige muito tempo e esforço para ser projetada e criada, pois os consumidores de dados internos e externos têm requisitos de controle de segurança diferentes. No futuro, também seriam necessários mais tempo e esforço para qualquer melhoria na solução.
Aumento dos produtores de dados
O diagrama a seguir mostra a arquitetura do data lake quando várias linhas de negócios se unem como produtoras de dados.

A arquitetura do data lake se torna cada vez mais complicada, mesmo com apenas três produtores e três consumidores de dados.
Cada produtor de dados precisa lidar com o compartilhamento de dados e o gerenciamento do acesso aos dados para vários consumidores de dados. Não é realista esperar que todos os produtores de dados desenvolvam um processo automatizado ou semiautomatizado para compartilhamento de dados e gerenciamento de acesso a dados. Alguns produtores de dados podem optar por não compartilhar seus dados e, portanto, evitar despesas inacessíveis de gerenciamento. Da mesma forma, cada consumidor de dados precisa interagir com vários produtores de dados para entender seus diferentes processos de consumo de dados. Isso significa que consumidores de dados individuais enfrentam uma sobrecarga crescente de gerenciamento para lidar com diferentes padrões de compartilhamento de dados.
Em muitas organizações, esse data lake causa gargalos e não pode crescer ou escalar. Isso pode significar que sua organização deve redesenhar e reconstruir seu data lake para remover o gargalo, o que pode custar tempo, recursos e dinheiro significativos.
