As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Nomeando buckets do Amazon S3 em suas camadas de dados
As seções a seguir fornecem estruturas de nomenclatura para buckets do Amazon Simple Storage Service (Amazon S3) em suas camadas de data lake. No entanto, você pode personalizar o bucket do Amazon S3 e os nomes dos caminhos de acordo com os requisitos da sua organização. Recomendamos que você crie buckets separados para cada camada individual, pois os requisitos de arquivamento, controle de versão, acesso e criptografia podem variar para cada camada.
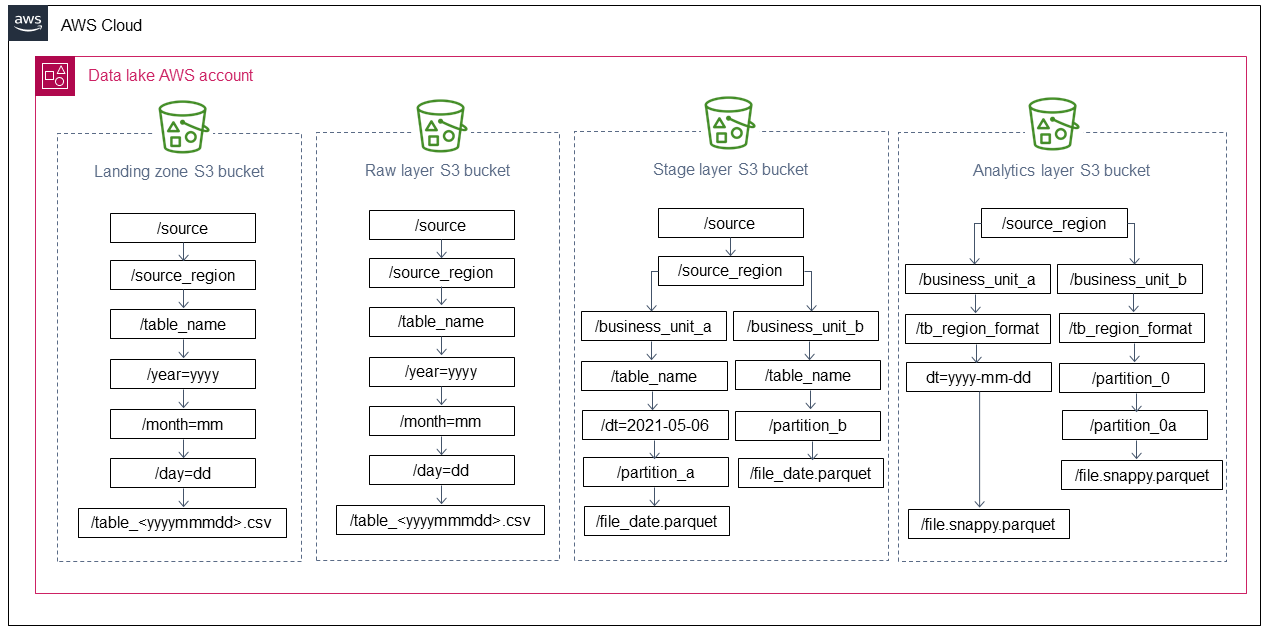
O diagrama a seguir mostra a estrutura de nomenclatura recomendada para buckets do Amazon S3 nas camadas de data lake recomendadas. A estrutura de nomenclatura separa várias unidades de negócios, formatos de arquivo e partições.
Importante
Os buckets do Amazon S3 devem seguir as diretrizes de nomenclatura das regras de nomenclatura do bucket na documentação do Amazon S3.
Você pode adaptar as partições de dados de acordo com os requisitos da sua organização. No entanto, você deve usar pares de minúsculas e de valores-chave (por exemplo, year=yyyy em vez deyyyy) para poder atualizar o catálogo com o comando. MSCK REPAIR
TABLE
A definição de uma estratégia de partição depende da natureza dos seus dados e, o mais importante, da natureza das consultas dos usuários. Recomendamos que você analise os padrões de consumo e processamento de dados para encontrar a estratégia mais adequada para sua organização. Em geral, faz sentido fornecer níveis hierárquicos mais altos, como, eyear=yyyy, month=mm na camada de dados brutosday=dd, e níveis hierárquicos mais baixos nas camadas de dados de consumo, como a camada de estágio e a camada de análise. Isso ocorre porque as camadas de dados brutos geralmente não têm os padrões complexos de consumo dos pipelines de processamento de dados.
Bucket Amazon S3 da zona de aterrissagem
Você precisará de um bucket do Amazon S3 para sua landing zone se conjuntos de dados confidenciais contiverem elementos que precisem ser mascarados antes que os dados sejam movidos para o bucket bruto.
A tabela a seguir fornece a estrutura de nomenclatura, uma descrição da estrutura de nomenclatura e um exemplo de nome para o bucket do Amazon S3 na sua camada de landing zone.
| Formato de nomenclatura | Exemplo |
|---|---|
|
|
Bucket Amazon S3 de camada bruta
A camada de dados brutos contém dados ingeridos que não foram transformados e estão em seu formato de arquivo original, como JSON ou CSV. Esses dados geralmente são organizados por fonte de dados e pela data em que foram ingeridos no bucket Amazon S3 da camada de dados brutos.
A tabela a seguir fornece a estrutura de nomenclatura, uma descrição da estrutura de nomenclatura e um exemplo de nome para o bucket do Amazon S3 em sua camada de dados brutos.
| Formato de nomenclatura | Exemplo |
|---|---|
|
|
Bucket Amazon S3 de camada de estágio
Os dados na camada de estágio são lidos e transformados da camada bruta (por exemplo, usando uma tarefa AWS Glue ou do Amazon EMR). Esse processo valida os dados (por exemplo, verificando os tipos de dados e cabeçalhos) e os armazena em um formato de arquivo pronto para consumo, como o Apache Parquet. Os metadados são armazenados em uma tabela no AWS Glue Data Catalog.
A tabela a seguir fornece a estrutura de nomenclatura, uma descrição da estrutura de nomenclatura e um exemplo de nome para o bucket do Amazon S3 em sua camada de dados de estágio.
| Formato de nomenclatura | Exemplo |
|---|---|
|
|
Camada de análise: bucket Amazon S3
A camada de análise é semelhante à camada de estágio porque os dados estão em um formato de arquivo processado, mas os dados são agregados de acordo com os requisitos da sua organização.
A tabela a seguir fornece a estrutura de nomenclatura, uma descrição da estrutura de nomenclatura e um exemplo de nome para o bucket do Amazon S3 em sua camada de dados analíticos.
| Formato de nomenclatura | Exemplo |
|---|---|
|
|
