As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Interpretabilidade local
Os métodos mais populares para interpretabilidade local de modelos complexos são baseados em Shapley Additive Explanations (SHAP) [8] ou em gradientes integrados [11]. Cada método tem várias variantes específicas para um tipo de modelo.
Para modelos de conjunto de árvores, use o SHAP de árvore
No caso de modelos baseados em árvore, a programação dinâmica permite o cálculo rápido e exato dos valores de Shapley
Para redes neurais e modelos diferenciáveis, use gradientes e condutância integrados
Gradientes integrados fornecem uma maneira simples de calcular atribuições de recursos em redes neurais. A condutância se baseia em gradientes integrados para ajudá-lo a interpretar atribuições de partes de redes neurais, como camadas e neurônios individuais. (Veja [3,11], a implementação está em https://captum.ai/
Para todos os outros casos, use Kernel SHAP
Você pode usar o Kernel SHAP para calcular atribuições de recursos para qualquer modelo, mas é uma aproximação ao cálculo dos valores completos de Shapley e permanece computacionalmente caro (consulte [8]). Os recursos computacionais necessários para o Kernel SHAP crescem rapidamente com o número de recursos. Isso requer métodos de aproximação que possam reduzir a fidelidade, a repetibilidade e a robustez das explicações. O Amazon SageMaker Clarify fornece métodos convenientes que implantam contêineres pré-criados para computar valores de Kernal SHAP em instâncias separadas. (Para ver um exemplo, consulte o repositório do GitHub Justiça e explicabilidae com o Clarify
Para modelos de árvore única, as variáveis divididas e os valores foliares fornecem um modelo imediatamente explicável, e os métodos discutidos anteriormente não fornecem informações adicionais. Da mesma forma, para modelos lineares, os coeficientes fornecem uma explicação clara do comportamento do modelo. (O SHAP e os métodos de gradiente integrado retornam contribuições que são determinadas pelos coeficientes.)
Tanto o SHAP quanto os métodos integrados baseados em gradientes têm pontos fracos. O SHAP exige que as atribuições sejam derivadas de uma média ponderada de todas as combinações de recursos. As atribuições obtidas dessa forma podem ser enganosas ao estimar a importância dos recursos se houver uma forte interação entre os recursos. Métodos baseados em gradientes integrados podem ser difíceis de interpretar devido ao grande número de dimensões presentes em grandes redes neurais, e esses métodos são sensíveis à escolha de um ponto base. De forma mais geral, os modelos podem usar recursos de maneiras inesperadas para atingir um certo nível de desempenho e isso pode variar de acordo com o modelo — a importância do recurso sempre depende do modelo.
Visualizações recomendadas
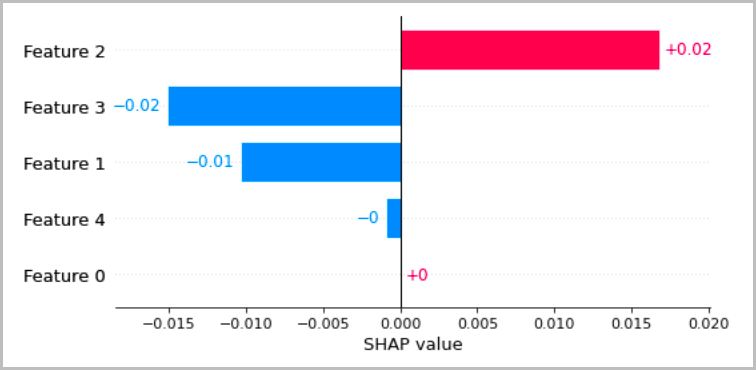
O gráfico a seguir apresenta várias maneiras recomendadas de visualizar as interpretações locais que foram discutidas nas seções anteriores. Para dados tabulares, recomendamos um gráfico de barras simples que mostre as atribuições, para que possam ser facilmente comparadas e usadas para inferir como o modelo está fazendo previsões.
Para dados de texto, a incorporação de tokens leva a um grande número de entradas escalares. Os métodos recomendados nas seções anteriores produzem uma atribuição para cada dimensão da incorporação e para cada saída. Para transformar essas informações em uma visualização, as atribuições de um determinado token podem ser somadas. O exemplo a seguir mostra a soma das atribuições do modelo de resposta a perguntas baseado em BERT que foi treinado no conjunto de dados SQUAD. Nesse caso, o rótulo previsto e verdadeiro é o símbolo da palavra “frança”.

Caso contrário, a norma vetorial das atribuições de token pode ser atribuída como um valor total de atribuição, conforme mostrado no exemplo a seguir.

Para camadas intermediárias em modelos de aprendizado profundo, agregações semelhantes podem ser aplicadas às condutâncias para visualização, conforme mostrado no exemplo a seguir. Essa norma vetorial da condutância do token para camadas de transformadores mostra a eventual ativação da previsão do token final (“frança”).

Os vetores de ativação conceitual fornecem um método para estudar redes neurais profundas com mais detalhes [6]. Esse método extrai recursos de uma camada em uma rede já treinada e treina um classificador linear nesses recursos para fazer inferências sobre as informações na camada. Por exemplo, talvez você queira determinar qual camada de um modelo de linguagem baseado em BERT contém mais informações sobre as partes do discurso. Nesse caso, você pode treinar um modelo linear de parte da fala em cada saída da camada e fazer uma estimativa aproximada de que o classificador de melhor desempenho está associado à camada que tem mais informações sobre parte da fala. Embora não recomendemos isso como um método primário para interpretar redes neurais, ele pode ser uma opção para um estudo mais detalhado e auxílio no projeto da arquitetura de rede.
