As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Cobertura e precisão de documentos — no domínio
Comparamos a performance preditiva de deep ensembles com integração aplicada no momento do teste, a integração de MC e uma função softmax simples, conforme mostrado no gráfico a seguir. Após a inferência, as previsões com as mais altas incertezas foram descartadas em diferentes níveis, gerando uma cobertura de dados restante que variou no intervalo de 10 a 100%. Esperávamos que o deep ensemble identificasse com mais eficiência as previsões incertas devido à sua maior capacidade de quantificar a incerteza epistêmica; ou seja, identificar regiões nos dados em que o modelo tem menos experiência. Isso deve se refletir em maior precisão para diferentes níveis de cobertura de dados. Para cada deep ensemble, usamos 5 modelos e aplicamos inferência 20 vezes. Para a integração de MC, aplicamos a inferência 100 vezes para cada modelo. Usamos o mesmo conjunto de hiperparâmetros e arquitetura de modelo para cada método.
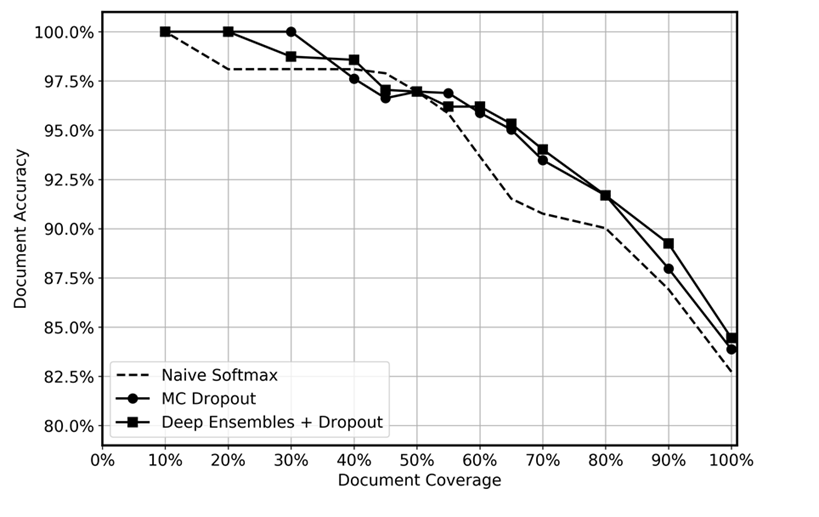
O gráfico parece mostrar um pequeno benefício em usar deep ensembles e integração de MC em comparação com o softmax simples. Isso é mais notório no intervalo de cobertura de dados de 50 a 80%. Por que isso não é maior? Conforme mencionado na seção de deep ensembles, a força dos deep ensembles vem das diferentes trajetórias de perda percorridas. Nessa situação, estamos usando modelos pré-treinados. Embora tenhamos ajustado todo o modelo, a grande maioria dos pesos é inicializada a partir do modelo pré-treinado e apenas algumas camadas ocultas são inicializadas aleatoriamente. Consequentemente, conjeturamos que o pré-treinamento de modelos grandes pode causar excesso de confiança devido à pouca diversificação. Até onde sabemos, a eficácia dos deep ensembles não foi testada anteriormente em cenários de aprendizado por transferência, e vemos isso como uma área promissora para pesquisas futuras.
