As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Preparação e limpeza de dados
A preparação e a limpeza de dados são uma das etapas mais importantes, porém mais demoradas, do ciclo de vida dos dados. O diagrama a seguir mostra como o estágio de preparação e limpeza de dados se encaixa no ciclo de vida de automação e controle de acesso da engenharia de dados.
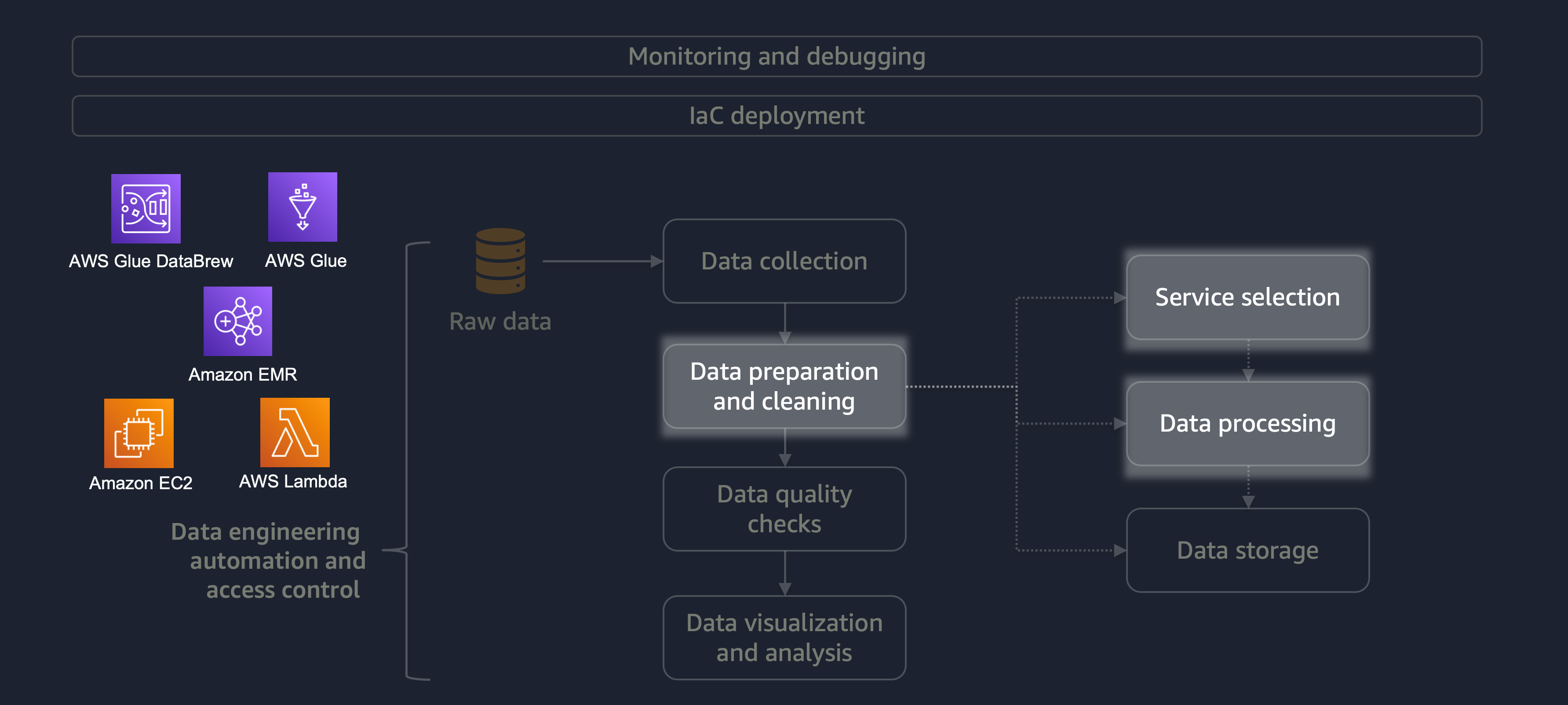
Aqui estão alguns exemplos de preparação ou limpeza de dados:
-
Mapeando colunas de texto para códigos
-
Ignorando colunas vazias
-
Preenchendo campos de dados vazios com
0None, ou'' -
Anonimizar ou mascarar informações de identificação pessoal (PII)
Se você tem uma grande carga de trabalho com uma variedade de dados, recomendamos que você use o Amazon EMR ouDataFrame DynamicFrame Além disso, você pode usar o AWS Glue DataBrew
Para cargas de trabalho menores que não exigem processamento distribuído e podem ser concluídas em menos de 15 minutos, recomendamos que você use o AWS
É essencial escolher o serviço certo da AWS para preparação e limpeza de dados e entender as vantagens e desvantagens envolvidas em sua escolha. Por exemplo, considere um cenário em que você está escolhendo entre o AWS Glue e o Amazon EMR. DataBrew O AWS Glue é ideal se o trabalho de ETL não for frequente. Um trabalho pouco frequente ocorre uma vez por dia, uma vez por semana ou uma vez por mês. Além disso, você pode presumir que seus engenheiros de dados são proficientes em escrever código Spark (para casos de uso de big data) ou criar scripts em geral. Se o trabalho for mais frequente, executar o AWS Glue constantemente pode sair caro. Nesse caso, o Amazon EMR fornece recursos de processamento distribuído e oferece uma versão sem servidor e baseada em servidor. Se seus engenheiros de dados não tiverem as habilidades certas ou se você precisar fornecer resultados rapidamente, essa DataBrew é uma boa opção. DataBrew pode reduzir o esforço de desenvolver código e acelerar o processo de preparação e limpeza de dados.
Depois que o processamento for concluído, os dados do processo de ETL serão armazenados na AWS. A escolha do armazenamento depende do tipo de dados com os quais você está lidando. Por exemplo, você pode trabalhar com dados não relacionais, como dados gráficos, dados de pares de valores-chave, imagens, arquivos de texto ou dados estruturados relacionais.
Conforme mostrado no diagrama a seguir, você pode usar os seguintes serviços da AWS para armazenamento de dados:
-
O Amazon S3
armazena dados não estruturados ou dados semiestruturados (por exemplo, arquivos, imagens e vídeos do Apache Parquet). -
O Amazon Neptune
armazena conjuntos de dados gráficos que você pode consultar usando SPARQL ou GREMLIN. -
O Amazon Keyspaces (para Apache Cassandra)
armazena conjuntos de dados compatíveis com o Apache Cassandra. -
O Amazon Aurora armazena conjuntos
de dados relacionais. -
O Amazon DynamoDB
armazena dados de valores-chave ou documentos em um banco de dados NoSQL. -
O Amazon Redshift
armazena cargas de trabalho para dados estruturados em um data warehouse.
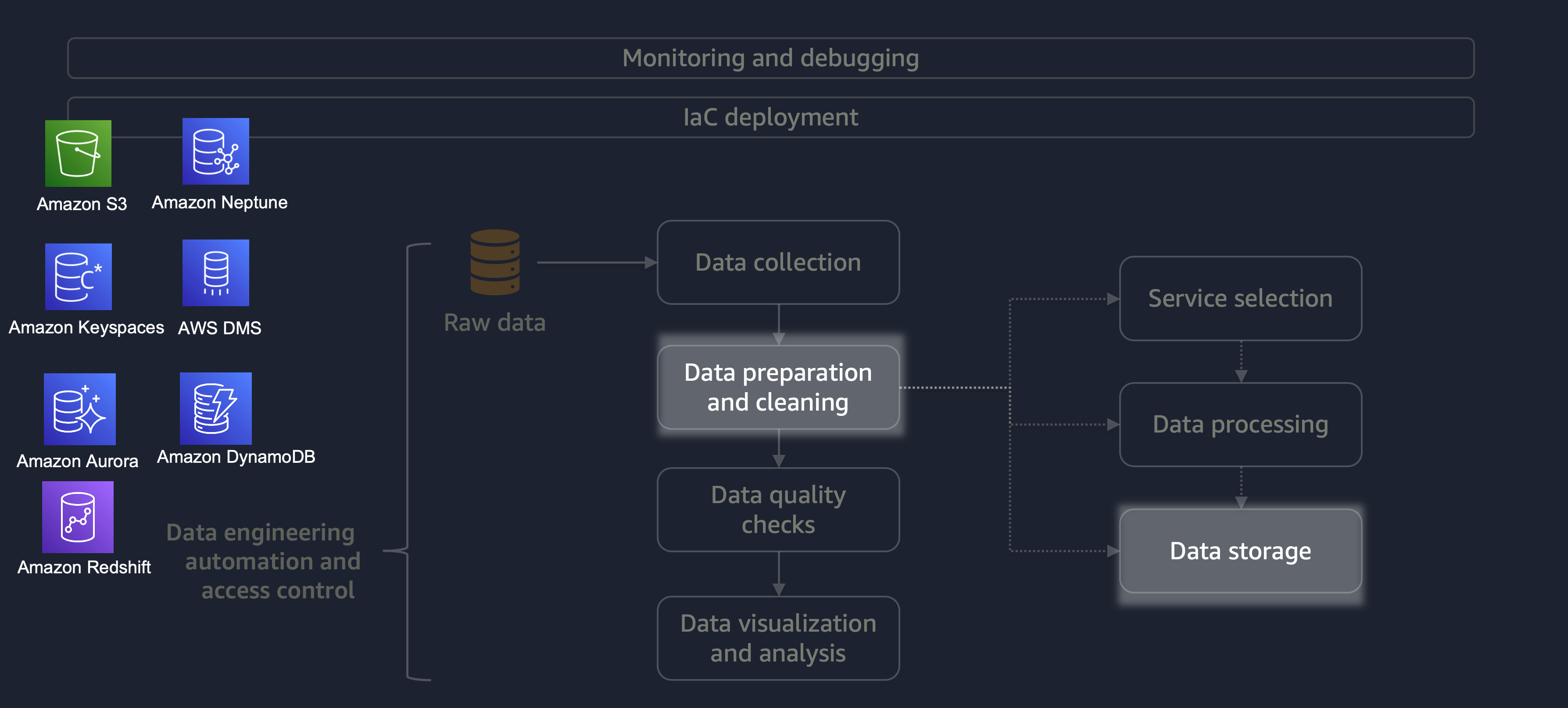
Ao usar o serviço certo com as configurações corretas, você pode armazenar seus dados da maneira mais eficiente e eficaz. Isso minimiza o esforço envolvido na recuperação de dados.
