As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Pilar Eficiência de performance
O pilar de eficiência de desempenho do AWS Well-Architected Framework se concentra em como otimizar o desempenho ao ingerir ou consultar dados. A otimização do desempenho é um processo incremental e contínuo do seguinte:
-
Confirmando os requisitos de negócios
-
Medindo o desempenho da carga de trabalho
-
Identificação de componentes com baixo desempenho
-
Ajustando componentes para atender às suas necessidades de negócios
O pilar de eficiência de desempenho fornece diretrizes específicas para casos de uso que podem ajudá-lo a identificar o modelo de dados gráficos e as linguagens de consulta corretos a serem usados. Também inclui as melhores práticas a serem seguidas ao ingerir e consumir dados do Neptune Analytics.
O pilar de eficiência de desempenho se concentra nas seguintes áreas principais:
-
Modelagem gráfica
-
Otimização de consultas
-
Dimensionamento correto do gráfico
-
Otimização de gravação
Entenda a modelagem gráfica para análise
O guia Applying the AWS Well-Architected Framework for Amazon Neptune discute a modelagem gráfica para eficiência de desempenho. As decisões de modelagem que afetam o desempenho incluem escolher quais nós e bordas são necessários IDs, seus rótulos e propriedades, a direção das bordas, se os rótulos devem ser genéricos ou específicos e, em geral, com que eficiência o mecanismo de consulta pode navegar pelo gráfico para processar consultas comuns.
Essas considerações também se aplicam ao Neptune Analytics; no entanto, é importante distinguir entre padrões de uso transacional e analítico. Um modelo gráfico eficiente para consultas em um banco de dados transacional, como um banco de dados Neptune, talvez precise ser reformulado para fins analíticos.
Por exemplo, considere um gráfico de fraude em um banco de dados do Neptune, cujo objetivo é verificar padrões fraudulentos em pagamentos com cartão de crédito. Esse gráfico pode ter nós que representam contas, pagamentos e recursos (como endereço de e-mail, endereço IP, número de telefone) da conta e do pagamento. Esse gráfico conectado suporta consultas como percorrer um caminho de comprimento variável que começa com um determinado pagamento e leva vários passos para encontrar recursos e contas relacionados. A figura a seguir mostra esse gráfico.
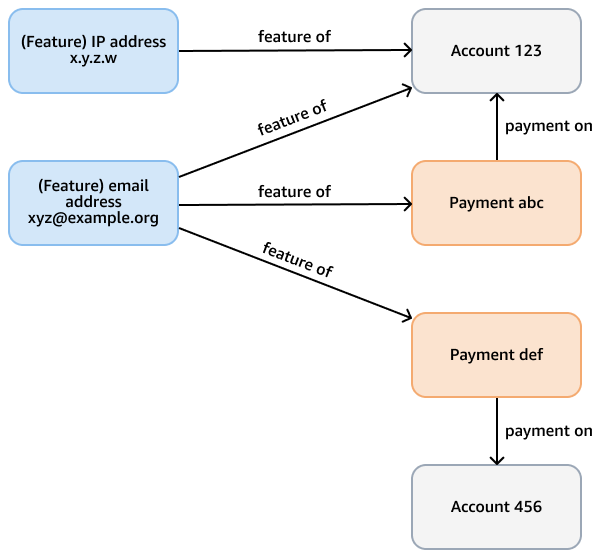
O requisito analítico pode ser mais específico, como encontrar comunidades de contas vinculadas por um recurso. Você pode usar o algoritmo de componentes fracamente conectados (WCC) para essa finalidade. Executá-lo em relação ao modelo do exemplo anterior é ineficiente, pois ele precisa atravessar vários tipos diferentes de nós e bordas. O modelo no diagrama a seguir é mais eficiente. Ele vincula account os nós a uma shares feature vantagem se as próprias contas — ou os pagamentos das contas — compartilharem um recurso. Por exemplo, Account 123 tem o recurso xyz@example.org de e-mail e Account 456 usa esse mesmo e-mail para um pagamento (Payment def).

A complexidade computacional do WCC éO(|E|logD): onde |E| está o número de arestas no gráfico e D o diâmetro (o comprimento do caminho mais longo) que conecta os nós. Como o modelo transacional omite nós e bordas não essenciais, ele otimiza o número de arestas e o diâmetro e reduz a complexidade do algoritmo WCC.
Ao usar o Neptune Analytics, use os algoritmos e as consultas analíticas necessárias. Se necessário, reformule o modelo para otimizar essas consultas. Você pode remodelar o modelo antes de carregar dados no gráfico ou escrever consultas que modifiquem os dados existentes no gráfico.
Otimizar consultas
Siga estas recomendações para otimizar as consultas do Neptune Analytics:
-
Use consultas parametrizadas e o cache do plano de consulta, que é ativado por padrão. Quando você usa o cache do plano, o mecanismo prepara a consulta para uso posterior, desde que a consulta seja concluída em 100 milissegundos ou menos, o que economiza tempo em invocações subsequentes.
-
Para consultas lentas, execute um plano de explicação para identificar gargalos e fazer as melhorias necessárias.
-
Se você usar a pesquisa de similaridade vetorial, decida se incorporações menores produzem resultados de similaridade precisos. Você pode criar, armazenar e pesquisar incorporações menores com mais eficiência.
-
Siga as melhores práticas documentadas para usar o OpenCypher no Neptune Analytics. Por exemplo, use mapas nivelados em uma cláusula UNWIND e especifique rótulos de borda sempre que possível.
-
Ao usar um algoritmo gráfico, entenda as entradas e saídas do algoritmo, sua complexidade computacional e, em geral, como ele funciona.
-
Antes de chamar um algoritmo gráfico, use uma
MATCHcláusula para minimizar o conjunto de nós de entrada. Por exemplo, para limitar a pesquisa abrangente (BFS) a partir dos nós, siga os exemplos fornecidos na documentação do Neptune Analytics. -
Filtre as etiquetas dos nós e das bordas, se possível. Por exemplo, o BFS tem parâmetros de entrada para filtrar a passagem para um rótulo de nó específico (
vertexLabel) ou rótulos de borda específicos ().edgeLabels -
Use parâmetros delimitadores, como
maxDepthpara limitar os resultados. -
Experimente com o
concurrencyparâmetro. Experimente com um valor de 0, que usa todos os encadeamentos de algoritmo disponíveis para paralelizar o processamento. Compare isso com a execução de um único encadeamento definindo o parâmetro como 1. Um algoritmo pode ser concluído mais rapidamente em um único encadeamento, especialmente em entradas menores, como pesquisas superficiais, nas quais o paralelismo não oferece nenhuma redução mensurável no tempo de execução e pode gerar sobrecarga. -
Escolha entre tipos similares de algoritmos. Por exemplo, Bellman-Ford e delta-stepping são algoritmos de caminho mais curto de fonte única. Ao testar com seu próprio conjunto de dados, experimente os dois algoritmos e compare os resultados. O Delta-Stepping geralmente é mais rápido do que o Bellman-Ford devido à sua menor complexidade computacional. No entanto, o desempenho depende do conjunto de dados e dos parâmetros de entrada, principalmente do
deltaparâmetro.
-
Otimize as gravações
Siga estas práticas para otimizar as operações de gravação no Neptune Analytics:
-
Busque a maneira mais eficiente de carregar dados em um gráfico. Ao carregar dados no Amazon S3, use a importação em massa se os dados tiverem mais de 50 GB de tamanho. Para dados menores, use o carregamento em lote. Se você receber out-of-memory erros ao executar o carregamento em lote, considere aumentar o valor de m-NCU ou dividir a carga em várias solicitações. Uma forma de fazer isso é dividir os arquivos em vários prefixos no bucket do S3. Nesse caso, chame o carregamento em lote separadamente para cada prefixo.
-
Use a importação em massa ou o carregador de lotes para preencher o conjunto inicial de dados gráficos. Use as operações transacionais de criação, atualização e exclusão do OpenCypher somente para pequenas alterações.
-
Use a importação em massa ou o carregador de lotes com uma simultaneidade de 1 (thread único) para ingerir incorporações no gráfico. Tente carregar as incorporações antecipadamente usando um desses métodos.
-
Avalie a dimensão das incorporações vetoriais necessárias para uma pesquisa precisa de similaridade em algoritmos de pesquisa de similaridade vetorial. Use uma dimensão menor, se possível. Isso resulta em uma velocidade de carregamento mais rápida para incorporações.
-
Use algoritmos de mutação para lembrar os resultados algorítmicos, se necessário. Por exemplo, o algoritmo de centralidade de mutação de grau encontra o grau de cada nó de entrada e grava esse valor como uma propriedade do nó. Se as conexões ao redor desses nós não mudarem posteriormente, a propriedade manterá o resultado correto. Não há necessidade de executar o algoritmo novamente.
-
Use a ação administrativa de redefinição de gráfico para limpar todos os nós, bordas e incorporações se precisar recomeçar. Eliminar todos os nós, bordas e incorporações usando uma consulta OpenCypher não é viável se o gráfico for grande. Uma única consulta suspensa em um grande conjunto de dados pode atingir o tempo limite. Conforme o tamanho aumenta, o conjunto de dados leva mais tempo para ser removido e o tamanho da transação aumenta. Por outro lado, o tempo para concluir uma redefinição gráfica é praticamente constante, e a ação oferece a opção de criar um instantâneo antes de executá-lo.
Gráficos do tamanho certo
O desempenho geral depende da capacidade provisionada de um gráfico do Neptune Analytics. A capacidade é medida em unidades chamadas Unidades de Capacidade de Netuno otimizadas para memória (m-). NCUs Certifique-se de que seu gráfico tenha tamanho suficiente para suportar o tamanho do gráfico e as consultas. Observe que o aumento da capacidade não necessariamente melhora o desempenho de uma consulta individual.
Se possível, crie o gráfico importando dados de uma fonte existente, como o Amazon S3 ou de um cluster ou snapshot existente do Neptune. Você pode colocar limites na capacidade mínima e máxima. Você também pode alterar a capacidade provisionada em um gráfico existente.
Monitore CloudWatch métricas comoNumQueuedRequestsPerSec,NumOpenCypherRequestsPerSec, GraphStorageUsagePercentGraphSizeBytes, e avalie CPUUtilization se o gráfico está no tamanho certo. Determine se é necessária mais capacidade para suportar o tamanho e a carga do gráfico. Para obter mais informações sobre como interpretar algumas dessas métricas, consulte a seção Pilar da excelência operacional.
