As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Principais tendências do banco de dados
Esta seção discute as principais tendências do banco de dados no momento da publicação. Essas informações ajudam a esclarecer as motivações que direcionam as cargas de trabalho do banco de dados para a nuvem. A seção aborda os seguintes tópicos:
Tendências de banco de dados no mercado corporativo
Atualmente, o mercado de bancos de dados está passando por mudanças significativas. Os volumes de dados estão crescendo exponencialmente. A quantidade total de dados capturados, copiados e consumidos globalmente por ano está aumentando. Os clientes devem extrair mais valor de seus dados. Empresas de nuvem como a AWS oferecem uma variedade de tecnologias de banco de dados criadas especificamente para as necessidades do banco de dados. Esses serviços oferecem agilidade, inovação, menos despesas gerais de manutenção e mais controle, além de serem mais econômicos. Estratégias de dados modernas podem dar suporte a casos de uso atuais e futuros, incluindo as etapas para criar uma solução de end-to-end dados para armazenar, acessar, analisar, visualizar e prever resultados futuros. Para obter mais informações sobre serviços e soluções de dados da AWS, consulte o site da AWS for Data
Os bancos de dados relacionais comerciais se tornaram populares há mais de 40 anos. Naquela época, a capacidade do hardware era limitada e cara. Os custos de armazenamento eram muito altos e os dados foram normalizados para evitar o armazenamento de duplicatas. Agora, a maior parte do armazenamento é mais barata do que computação e memória. Os requisitos também mudaram, e talvez você precise de desempenho de microssegundos em diferentes conjuntos de dados que incluam dados estruturados e não estruturados. Durante anos, os clientes se limitaram a usar um pequeno conjunto de plataformas de banco de dados. Aplicativos comerciais off-the-shelf (COTS), como Oracle E-Business Suite, Siebel e PeoplesoftCRM, só podiam ser executados no Oracle. As empresas desenvolveram aplicativos internos usando recursos proprietários, como PL/ SQL ou Pro*C, e esses aplicativos personalizados atenderam às demandas comerciais. No entanto, com o tempo, os recursos proprietários se tornaram complexos e difíceis de manter. As restrições orçamentárias de TI forçaram muitas empresas a repensar sua abordagem para atender às demandas comerciais e a se concentrarem na otimização de suas estruturas de custos migrando para opções mais baratas, nas quais seus custos de migração eram determinados pelo nível de personalização necessário.
Como alternativa aos produtos de banco de dados comerciais, AWS introduziu um portfólio de bancos de dados totalmente gerenciados, relacionais e de código aberto, bem como mecanismos de banco de dados não relacionais criados especificamente para otimização da carga de trabalho de casos de uso específicos. A principal vantagem dos bancos de dados de código aberto é seu menor custo. Os orçamentos de TI não são onerados por pagamentos contratuais, porque eles não precisam mais pagar as taxas de licença associadas ao software comercial. Com essas economias, os departamentos de TI têm uma enorme flexibilidade, para que possam experimentar e ser ágeis. Por exemplo, muitos clientes modernizam suas cargas de trabalho Oracle migrando para o Postgre. SQL A SQL funcionalidade do Postgre melhorou significativamente nos últimos 10 anos e agora inclui muitos recursos de banco de dados corporativo para suportar cargas de trabalho grandes e críticas.
A forma como os bancos de dados estão operando também está passando por mudanças. Nos últimos 30 anos, os clientes operaram seus próprios data centers localmente: compraram e gerenciaram infraestrutura, mantiveram hardware, licenciaram redes e bancos de dados comerciais e contrataram profissionais de TI para administrar os data centers. Os administradores do banco de dados (DBAs) configuraram e operaram principalmente bancos de dados relacionais. Suas tarefas operacionais incluíam instalação de hardware e software, resolução de problemas de licenciamento, configuração, aplicação de patches e backup de banco de dados. DBAstambém gerenciou o ajuste de desempenho e a configuração para problemas de alta disponibilidade, segurança e conformidade. O gerenciamento de bancos de dados incluía tarefas repetitivas e tediosas, além de ser demorado e caro. Os clientes passaram tempo gerenciando a infraestrutura em vez de se concentrarem nas principais competências comerciais. Por esse motivo, as empresas investiram em automação DBA e tarefas operacionais sempre que possível para melhor utilizar DBA os recursos, para que pudessem dedicar mais tempo à inovação. Para obter mais informações, consulte o IDC relatório Amazon Relational Database Service Delivers Enhanced Database Performance at Lower Total Cost
Bancos de dados personalizados versus bancos de dados convergentes
O Oracle Exadata foi lançado inicialmente em 2008. Ele foi projetado para resolver um gargalo comum em grandes bancos de dados: mover grandes volumes de dados do armazenamento em disco para os servidores de banco de dados. Resolver esse problema pode ser particularmente benéfico para aplicativos de data warehouse em que a digitalização de grandes conjuntos de dados é comum. O Exadata aumentou o canal entre a camada de armazenamento e banco de dados usando InfiniBand e reduziu a quantidade de dados que seriam transferidos do disco para a camada do banco de dados usando recursos de software como o Exadata Smart Scan. Em alguns casos, o Exadata introduziu melhorias de desempenho, mas isso resultou no aumento do custo total de propriedade (TCO) e na redução da agilidade, pelos motivos mencionados na seção anterior.
Há duas abordagens para hospedar aplicativos de banco de dados:
-
Usando bancos de dados específicos e criados especificamente para cargas de trabalho ou casos de uso específicos
-
Usando um banco de dados convergente que ofereça suporte a diferentes cargas de trabalho de banco de dados no mesmo banco de dados
Depois que os clientes migram para a nuvem, eles geralmente querem modernizar suas arquiteturas de aplicativos
AWS oferece bancos de dados relacionais de alto desempenho a um custo muito menor em comparação com bancos de dados comerciais de nível corporativo e oito bancos de dados específicos. Cada banco de dados criado especificamente é projetado exclusivamente para fornecer desempenho ideal para um caso de uso específico, para que as empresas não precisem se comprometer, como geralmente acontece ao usar a abordagem de banco de dados convergente. O diagrama a seguir ilustra as ofertas AWS de banco de dados.
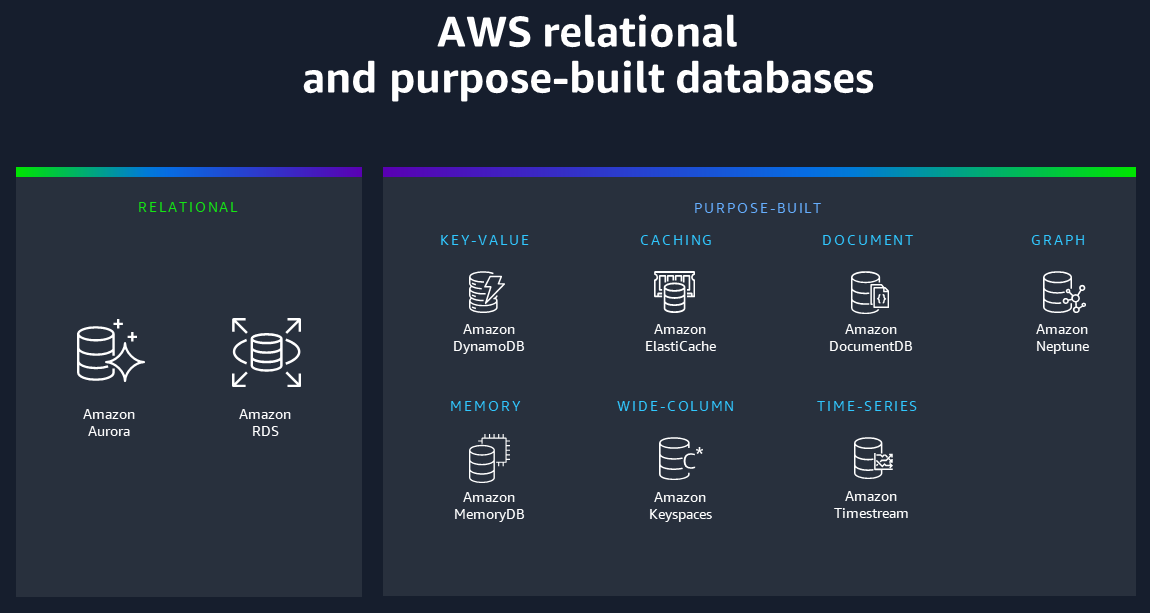
Tipo de banco de dados |
Casos de uso |
Produto da AWS |
|---|---|---|
Relacional |
Aplicativos tradicionais, planejamento de recursos corporativos, gerenciamento de relacionamento com o cliente |
Amazon Aurora, AmazonRDS, Amazon Redshift |
Chave-valor |
Aplicativos web de alto tráfego, sistemas de comércio eletrônico, aplicativos de jogos |
Amazon DynamoDB |
Na memória |
Cache, gerenciamento de sessões, tabelas de classificação de jogos, aplicativos geoespaciais |
Amazon ElastiCache, Amazon MemoryDB |
Documento |
Gerenciamento de conteúdo, catálogos, perfis de usuário |
Amazon DocumentDB (compatível com MongoDB) |
Coluna larga |
Aplicações industriais de alta escala para manutenção de equipamentos, gerenciamento de frotas e otimização de rotas |
Amazon Keyspaces (para Apache Cassandra) |
Gráfico |
Detecção de fraudes, redes sociais, mecanismos de recomendação |
Amazon Neptune |
Séries temporais |
Aplicativos da Internet das Coisas (IoT) DevOps, telemetria industrial |
Amazon Timestream |
