As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migre o SQL Server para a AWS usando grupos de disponibilidade distribuídos
Criado por Praveen Marthala (AWS)
Resumo
Os grupos de disponibilidade do Microsoft SQL Server Always On fornecem uma solução de alta disponibilidade (HA) e recuperação de desastres (DR) para o SQL Server. Um grupo de disponibilidade consiste em uma réplica primária que aceita tráfego de leitura/gravação e até oito réplicas secundárias que aceitam tráfego de leitura. Um grupo de disponibilidade é configurado em um cluster de failover do Windows Server (WSFC) com dois ou mais nós.
Os grupos de disponibilidade distribuídos do Microsoft SQL Server Always On fornecem uma solução para configurar dois grupos de disponibilidade separados entre dois grupos independentes WFSCs. Os grupos de disponibilidade que fazem parte do grupo de disponibilidade distribuída não precisam estar no mesmo datacenter. Um grupo de disponibilidade pode estar no local e o outro grupo de disponibilidade pode estar na nuvem da Amazon Web Services (AWS) em instâncias da Amazon Elastic Compute Cloud (Amazon EC2) em um domínio diferente.
Esse padrão descreve as etapas para usar um grupo de disponibilidade distribuído para migrar bancos de dados SQL Server locais que fazem parte de um grupo de disponibilidade existente para o SQL Server com grupos de disponibilidade configurados na Amazon. EC2 Seguindo esse padrão, você pode migrar os bancos de dados para a Nuvem AWS com o mínimo de tempo de inatividade durante a substituição. Os bancos de dados estão altamente disponíveis na AWS imediatamente após a substituição. Você também pode usar esse padrão para alterar o sistema operacional subjacente on-premises para a AWS, mantendo a mesma versão do SQL Server.
Pré-requisitos e limitações
Pré-requisitos
Uma conta AWS ativa
AWS Direct Connect ou AWS Site-to-Site VPN
A mesma versão do SQL Server instalada on-premises e nos dois nós da AWS
Versões do produto
SQL Server versão 2016 e posterior
SQL Server Enterprise Edition
Arquitetura
Pilha de tecnologia de origem
Banco de dados do Microsoft SQL Server com grupos de disponibilidade Always On on-premises
Pilha de tecnologias de destino
Banco de dados Microsoft SQL Server com grupos de disponibilidade Always On na Amazon EC2 na nuvem da AWS
Arquitetura de migração
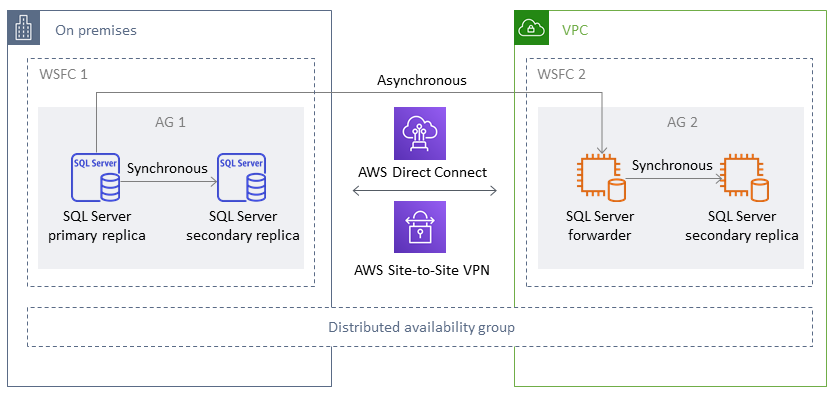
Terminologia
WSFC 1 – WSFC on-premises
WSFC 2 – WSFC na Nuvem AWS
AG 1 – Primeiro grupo de disponibilidade, que está no WSFC 1
AG 2 – Segundo grupo de disponibilidade, que está no WSFC 2
Réplica primária do SQL Server – nó no AG 1 que é considerado o principal global para todas as gravações
Encaminhador do SQL Server – nó no AG 2 que recebe dados de forma assíncrona da réplica primária do SQL Server
Réplica secundária do SQL Server – nós no AG 1 ou AG 2 que recebem dados de forma síncrona da réplica primária ou do encaminhador
Ferramentas
AWS Direct Connect: o AWS Direct Connect vincula sua rede interna a um local do AWS Direct Connect por meio de um cabo de fibra óptica de Ethernet padrão. Com essa conexão, você pode criar interfaces virtuais diretamente para serviços públicos da AWS, ignorando provedores de serviço da internet no caminho da sua rede.
Amazon EC2 — A Amazon Elastic Compute Cloud (Amazon EC2) fornece capacidade de computação escalável na Nuvem AWS. Você pode usar EC2 a Amazon para lançar quantos servidores virtuais precisar e pode expandir ou aumentar a escala.
AWS Site-to-Site VPN — O AWS Site-to-Site VPN oferece suporte à criação de uma rede privada site-to-site virtual (VPN). Você pode configurar o VPN para transmitir tráfego entre instâncias que você executa na AWS e sua própria rede remota.
Microsoft SQL Server Management Studio
: o Microsoft SQL Server Management Studio (SSMS) é um ambiente integrado para o gerenciamento de uma infraestrutura do SQL Server. Ele fornece uma interface de usuário e um grupo de ferramentas com editores de scripts avançados que interagem com o SQL Server.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Crie um WSFC na AWS. | Crie o WSFC 2 em EC2 instâncias da Amazon com dois nós para HA. Você usará esse cluster de failover para criar o segundo grupo de disponibilidade (AG 2) na AWS. | Administrador de sistemas, SysOps administrador |
Crie o segundo grupo de disponibilidade no WSFC 2. | Usando o SSMS, crie o AG 2 em dois nós no WSFC 2. O primeiro nó no WSFC 2 atuará como encaminhador. O segundo nó no WSFC 2 atuará como a réplica secundária do AG 2. Neste estágio, nenhum banco de dados está disponível no AG 2. Esse é o ponto de partida para configurar o grupo de disponibilidade distribuído. | DBA, Desenvolvedor |
Crie bancos de dados sem opção de recuperação no AG 2. | Faça backup dos bancos de dados no grupo de disponibilidade on-premises (AG 1). Restaure os bancos de dados tanto para o encaminhador quanto para a réplica secundária do AG 2 sem opção de recuperação. Ao restaurar os bancos de dados, especifique um local com espaço em disco suficiente para os arquivos de dados do banco de dados e os arquivos de log. Nesse estágio, os bancos de dados estão em estado de restauração. Eles não fazem parte do AG 2 ou do grupo de disponibilidade distribuída e não estão sincronizando. | DBA, Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Crie o grupo de disponibilidade distribuída no AG 1. | Para criar o grupo de disponibilidade distribuído no AG 1, use o
| DBA, Desenvolvedor |
Crie o grupo de disponibilidade distribuída no AG 2. | Para criar o grupo de disponibilidade distribuído no AG 2, use o
O grupo de disponibilidade distribuída é criado entre o AG 1 e o AG 2. Os bancos de dados no AG 2 ainda não estão configurados para participar do fluxo de dados do AG 1 para o AG 2. | DBA, Desenvolvedor |
Adicione bancos de dados ao encaminhador e à réplica secundária no AG 2. | Adicione os bancos de dados ao grupo de disponibilidade distribuído usando Isso inicia o fluxo de dados assíncrono entre bancos de dados no AG 1 e no AG 2. O primário global faz gravações, envia dados de forma síncrona para a réplica secundária no AG 1 e envia os dados de forma assíncrona para o encaminhador no AG 2. O encaminhador no AG 2 envia dados de forma síncrona para a réplica secundária no AG 2. | DBA, Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Registros de uso DMVs e do SQL Server. | Monitore o status do fluxo de dados entre dois grupos de disponibilidade usando exibições de gerenciamento dinâmico (DMVs) e registros do SQL Server. DMVs que são de interesse para monitoramento incluem Para saber o status da sincronização do encaminhador, monitore o estado sincronizado no log do SQL Server no encaminhador. | DBA, Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Interrompa todo o tráfego para a réplica primária. | Interrompa o tráfego de entrada para a réplica primária no AG 1 para que nenhuma atividade de gravação ocorra nos bancos de dados e os bancos de dados estejam prontos para a migração. | Proprietário do aplicativo, desenvolvedor |
Altere o modo de disponibilidade do grupo de disponibilidade distribuída no AG 1. | Na réplica primária, defina o modo de disponibilidade do grupo de disponibilidade distribuído como síncrono. Depois de alterar o modo de disponibilidade para síncrono, os dados são enviados de forma síncrona da réplica primária no AG 1 para o encaminhador no AG 2. | DBA, Desenvolvedor |
Verifique LSNs em ambos os grupos de disponibilidade. | Verifique os últimos números de sequência de log (LSNs) no AG 1 e no AG 2. Como nenhuma gravação está acontecendo na réplica primária no AG 1, os dados são sincronizados e os últimos LSNs para os dois grupos de disponibilidade devem corresponder. | DBA, Desenvolvedor |
Atualize o AG 1 para a função secundária. | Quando você atualiza o AG 1 para a função secundária, o AG 1 perde a função de réplica principal e não aceita gravações, e o fluxo de dados entre dois grupos de disponibilidade é interrompido. | DBA, Desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Faça o failover manual para o AG 2. | No encaminhador no AG 2, altere o grupo de disponibilidade distribuído para permitir a perda de dados. Como você já verificou e confirmou que os últimos LSNs no AG 1 e no AG 2 coincidem, a perda de dados não é uma preocupação. Quando você permite a perda de dados no encaminhador no AG 2, as funções do AG 1 e do AG 2 mudam:
| DBA, Desenvolvedor |
Altere o modo de disponibilidade do grupo de disponibilidade distribuída no AG 2. | Na réplica primária no AG 2, altere o modo de disponibilidade para assíncrono. Isso altera a movimentação de dados do AG 2 para o AG 1, de síncrono para assíncrono. Essa etapa é necessária para evitar a latência de rede entre o AG 2 e o AG 1, se houver, e não afetará o desempenho do banco de dados. | DBA, Desenvolvedor |
Comece a enviar tráfego para a nova réplica primária. | Atualize a cadeia de conexão para usar o endpoint de URL do receptor no AG 2 para enviar tráfego para os bancos de dados. O AG 2 agora aceita gravações e envia dados para o encaminhador no AG 1, além de enviar dados para sua própria réplica secundária no AG 2. Os dados são movidos de forma assíncrona do AG 2 para o AG 1. | Proprietário do aplicativo, desenvolvedor |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Descarte o grupo de disponibilidade distribuída no AG 2. | Monitore a migração pelo período de tempo planejado. Em seguida, descarte o grupo de disponibilidade distribuída no AG 2 para remover a configuração do grupo de disponibilidade distribuída entre o AG 2 e o AG 1. Isso remove a configuração do grupo de disponibilidade distribuído e o fluxo de dados do AG 2 para o AG 1 é interrompido. Neste momento, o AG 2 está altamente disponível na AWS, com uma réplica primária que recebe gravações e uma réplica secundária no mesmo grupo de disponibilidade. | DBA, Desenvolvedor |
Desative os servidores on-premises. | Desative os servidores on-premises no WSFC 1 que fazem parte do AG 1. | Administrador de sistemas, SysOps administrador |
Recursos relacionados
