As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Processamento de consultas SQL no Amazon Redshift
O Amazon Redshift roteia uma consulta SQL enviada por meio do analisador e otimizador para desenvolver um plano de consulta. O mecanismo de execução então converte o plano de consulta em código e envia esse código para nós de computação para execução. Antes de criar um plano de consulta, é fundamental entender como o processamento de consultas funciona.
Planejamento de consulta e fluxo de trabalho de execução
O diagrama a seguir fornece uma visão de alto nível do fluxo de trabalho de planejamento e execução de consultas.
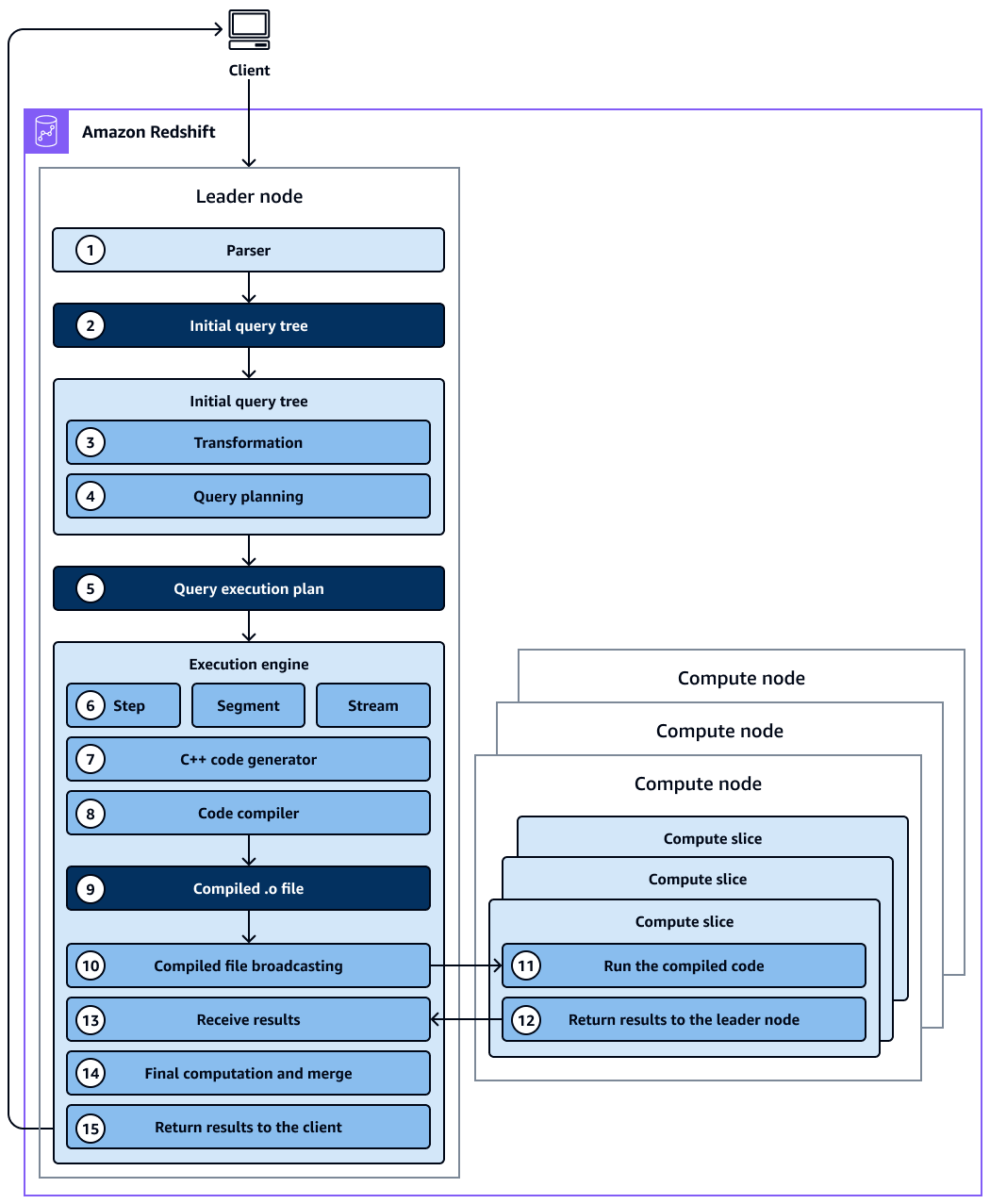
O diagrama mostra o seguinte fluxo de trabalho:
-
O nó líder no cluster do Amazon Redshift recebe a consulta e analisa a instrução SQL.
-
O analisador produz uma árvore de consulta inicial que é uma representação lógica da consulta original.
-
O otimizador de consultas pega a árvore de consulta inicial e a avalia, analisa as estatísticas da tabela para determinar a ordem de junção e a seletividade dos predicados e, se necessário, reescreve a consulta para maximizar sua eficiência. Às vezes, uma única consulta pode ser escrita como várias declarações dependentes em segundo plano.
-
O otimizador gera um plano de consulta (ou vários, se a etapa anterior resultou em múltiplas consultas) para a execução com a melhor performance. O plano de consulta especifica opções de execução, como ordem de execução, operações de rede, tipos de junção, ordem de junção, opções de agregação e distribuições de dados.
-
Um plano de consulta contém informações sobre as operações individuais necessárias para executar uma consulta. Use o comando
EXPLAINpara visualizar o plano de consulta. O plano de consulta é uma ferramenta fundamental para analisar e ajustar consultas complexas. -
O otimizador de consultas envia o plano de consulta para o mecanismo de execução. O mecanismo de execução verifica o cache do plano compilado em busca de uma correspondência do plano de consulta e usa o cache compilado (se encontrado). Caso contrário, o mecanismo de execução traduz o plano de consulta em etapas, segmentos e fluxos:
-
As etapas são operações individuais que ocorrem durante a execução da consulta. As etapas são identificadas por um rótulo (por exemplo
scan,dist,hjoin, oumerge). Uma etapa é a menor unidade. Você pode combinar etapas para que os nós de computação possam realizar uma consulta, união ou outra operação de banco de dados. -
Um segmento se refere a um segmento de uma consulta e combina várias etapas que podem ser realizadas por um único processo. Um segmento é a menor unidade de compilação executável por uma fatia do nó de computação. Uma fatia é a unidade de processamento paralelo no Amazon Redshift.
-
Um stream é uma coleção de segmentos a serem distribuídos entre as fatias de nós de computação disponíveis. Os segmentos em um fluxo correm paralelamente nas fatias dos nós. Portanto, a mesma etapa do mesmo segmento também é executada paralelamente em várias fatias.
-
-
O gerador de código recebe o plano traduzido e gera uma função C++ para cada segmento.
-
A função C++ gerada é compilada pela coleção de compiladores GNU e convertida em um arquivo O ()
.o. -
O código compilado (arquivo O) é executado. O código compilado é executado mais rapidamente que o código interpretado e usa menos capacidade computacional.
-
O arquivo O compilado é então transmitido para os nós de computação.
-
Cada nó de computação consiste em várias fatias de computação. As fatias de computação executam os segmentos de consulta em paralelo. O Amazon Redshift aproveita a comunicação de rede, a memória e o gerenciamento de disco otimizados para transmitir resultados intermediários de uma etapa do plano de consulta para a próxima. Isso também ajuda a acelerar a execução da consulta. Considere o seguinte:
-
As etapas 6, 7, 8, 9, 10 e 11 acontecem uma vez para cada stream.
-
O mecanismo cria os segmentos executáveis para um fluxo e os envia para os nós de computação.
-
Depois que os segmentos de um fluxo anterior são concluídos, o mecanismo gera os segmentos para o próximo fluxo. Desta forma, o mecanismo pode analisar o que aconteceu no fluxo anterior (por exemplo, se as operações foram baseadas em disco) para influenciar a geração de segmentos no fluxo seguinte.
-
-
Depois que os nós de computação são concluídos, eles retornam os resultados da consulta ao nó líder para o processamento final. O nó líder mescla os dados em um único conjunto de resultados e aborda qualquer classificação ou agregação necessária.
-
O nó líder retorna os resultados ao cliente.
O diagrama a seguir mostra o fluxo de trabalho de execução de fluxos, segmentos, etapas e fatias de nós de computação. Lembre-se do seguinte:
-
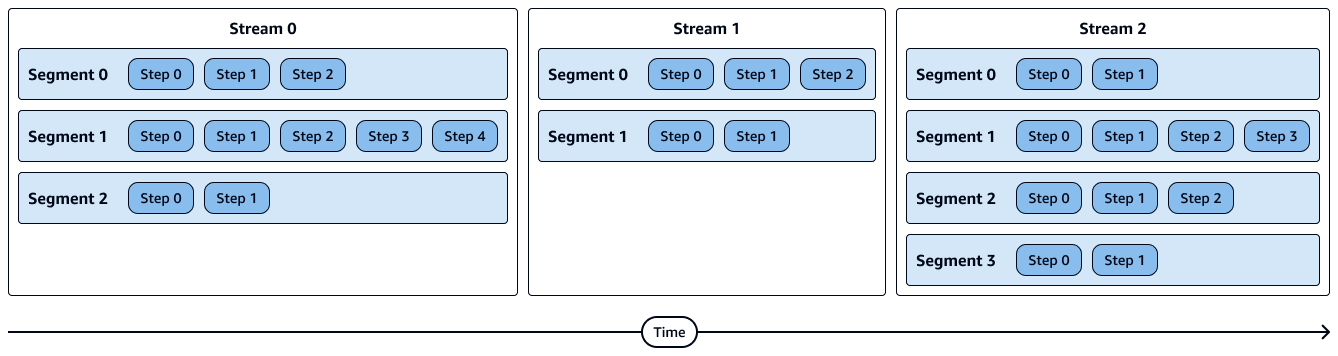
As etapas em um segmento são executadas sequencialmente.
-
Segmentos em um riacho correm em paralelo.
-
Os fluxos são executados sequencialmente.
-
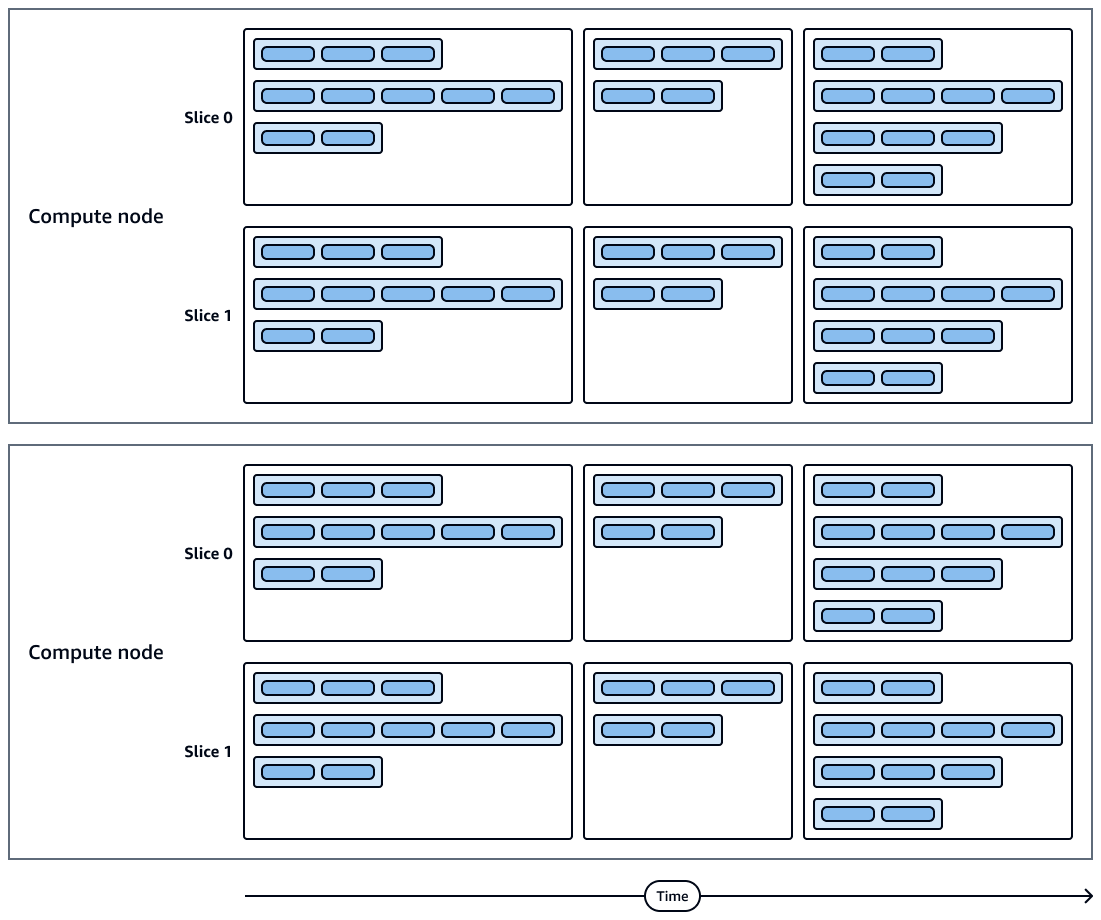
As fatias dos nós de computação são executadas em paralelo.
O diagrama a seguir mostra uma representação visual de fluxos, segmentos e etapas. Cada segmento contém várias etapas e cada fluxo contém vários segmentos.
O diagrama a seguir mostra uma representação visual das execuções de consultas e das fatias dos nós de computação. Cada nó de computação contém várias fatias, fluxos, segmentos e etapas.
Considerações adicionais
Recomendamos que você considere o seguinte em relação ao processamento de consultas:
-
O código compilado em cache é compartilhado entre sessões no mesmo cluster, portanto, as execuções subsequentes da mesma consulta serão mais rápidas, geralmente mesmo com parâmetros diferentes.
-
Ao comparar suas consultas, recomendamos que você sempre compare os tempos da segunda execução de uma consulta, porque o primeiro tempo de execução inclui a sobrecarga da compilação do código. Para obter mais informações, consulte Fatores de desempenho da consulta no guia de melhores práticas de consulta para o Amazon Redshift.
-
Os nós de computação podem retornar alguns dados ao nó líder durante a execução da consulta, se necessário. Por exemplo, se você tiver uma subconsulta com uma
LIMITcláusula, o limite será aplicado no nó líder antes que os dados sejam redistribuídos pelo cluster para processamento adicional.
