As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Entendendo a carga de trabalho
Para aplicar a estrutura, comece entendendo a carga de trabalho que você deseja analisar. Um diagrama da arquitetura do sistema fornece um ponto de partida para documentar os detalhes mais relevantes do sistema. No entanto, tentar analisar uma carga de trabalho inteira pode ser complexo, pois muitos sistemas têm vários componentes e interações. Em vez disso, recomendamos que você se concentre nas histórias de usuários
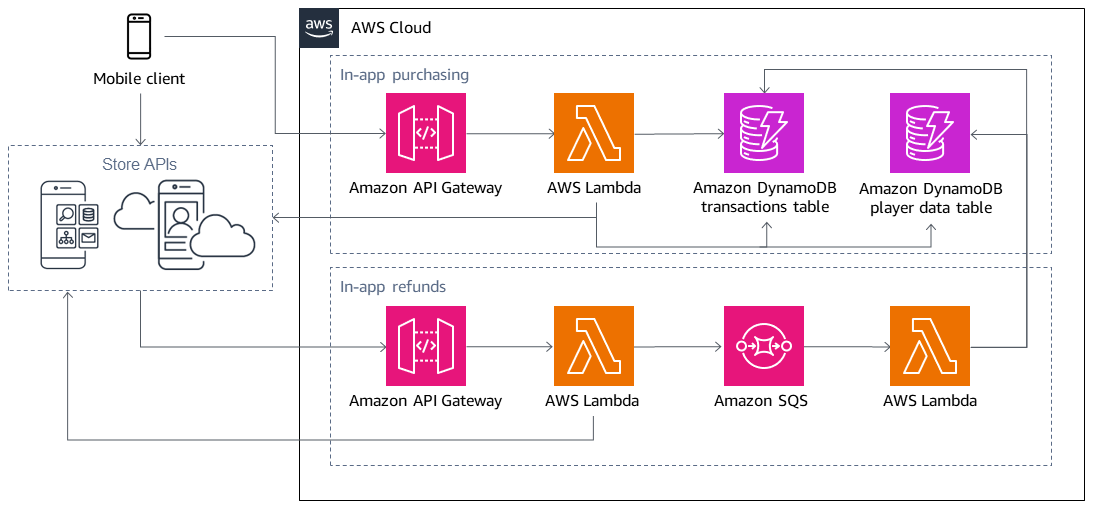
Cada história de usuário consiste em quatro componentes comuns: código e configuração, infraestrutura, armazenamentos de dados e dependências externas. Seus diagramas devem incluir todos esses componentes e refletir as interações entre os componentes. Por exemplo, se houver carga excessiva em seu endpoint do Amazon API Gateway, considere como essa carga é transmitida em cascata para outros componentes do sistema, como suas AWS Lambda funções ou tabelas do Amazon DynamoDB. O rastreamento dessas interações ajuda você a entender como o modo de falha pode afetar a história do usuário. Você pode capturar esse fluxo visualmente com um diagrama de fluxo de dados ou usando setas de fluxo simples em um diagrama de arquitetura, como na ilustração anterior. Para cada componente, considere capturar detalhes como o tipo de informação que está sendo transmitida, a informação recebida, se a comunicação é síncrona ou assíncrona e quais limites de falha estão sendo ultrapassados. No exemplo, as tabelas do DynamoDB são compartilhadas nas duas histórias de usuário, como você pode ver pelas setas que indicam que o componente Lambda na história de reembolsos no aplicativo acessa as tabelas do DynamoDB na história de compras no aplicativo. Isso significa que uma falha causada pela história do usuário de compra no aplicativo pode se transformar em cascata na história do usuário de reembolsos no aplicativo como resultado de um destino compartilhado.
Além disso, é importante entender a configuração básica de cada componente. A configuração básica identifica restrições como o número médio e máximo de transações por segundo, o tamanho máximo de uma carga útil, o tempo limite do cliente e as cotas de serviço padrão ou atuais para o recurso. Se você estiver modelando um novo design, recomendamos que documente os requisitos funcionais do projeto e considere os limites. Isso ajuda você a entender como os modos de falha podem se manifestar no componente.
Por fim, você deve priorizar as histórias de usuários com base no valor comercial que elas fornecem. Essa priorização ajuda você a se concentrar primeiro na funcionalidade mais crítica da sua carga de trabalho. Em seguida, você pode concentrar sua análise nos componentes da carga de trabalho que fazem parte do caminho crítico para essa funcionalidade e obter valor ao utilizar a estrutura mais rapidamente. À medida que avança no processo, você pode examinar histórias de usuários adicionais com prioridades diferentes.
